 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers in the Dark: Navigating Unknown Search Spaces via Bandit Feedback
Mar 25, 2026Effective problem solving with Large Language Models (LLMs) can be enhanced when they are paired with external search algorithms. By viewing the space of diverse ideas and their follow-up possibilities as a tree structure, the search algorithm can navigate such a search space and guide the LLM toward better solutions more efficiently. While the search algorithm enables an effective balance between exploitation and exploration of a tree-structured space, the need for an external component can complicate the overall problem-solving process. We therefore pose the following question: Can LLMs or their underlying Transformer architectures approximate a search algorithm? To answer this question, we first introduce a simplified framework in which tree extensions and feedback signals are externally specified, allowing for controlled evaluation of search capabilities. We call this setting unknown tree search with bandit feedback. Within this setting, we show that Transformers are theoretically expressive enough to implement distinct search strategies and can be trained from scratch to approximate those strategies. Our Transformer models exhibit the possibility of generalizing to unseen conditions such as longer horizons or deeper trees. Furthermore, we demonstrate that continued task-focused training unlocks the complete capabilities of a pretrained LLM, by fine-tuning the LLM on search trajectories.
Fine-Tuning Without Forgetting In-Context Learning: A Theoretical Analysis of Linear Attention Models
Feb 26, 2026Transformer-based large language models exhibit in-context learning, enabling adaptation to downstream tasks via few-shot prompting with demonstrations. In practice, such models are often fine-tuned to improve zero-shot performance on downstream tasks, allowing them to solve tasks without examples and thereby reducing inference costs. However, fine-tuning can degrade in-context learning, limiting the performance of fine-tuned models on tasks not seen during fine-tuning. Using linear attention models, we provide a theoretical analysis that characterizes how fine-tuning objectives modify attention parameters and identifies conditions under which this leads to degraded few-shot performance. We show that fine-tuning all attention parameters can harm in-context learning, whereas restricting updates to the value matrix improves zero-shot performance while preserving in-context learning. We further show that incorporating an auxiliary few-shot loss enhances in-context learning primarily on the target task, at the expense of degraded in-context learning ability on tasks not seen during fine-tuning. We empirically validate our theoretical results.
Soft Task-Aware Routing of Experts for Equivariant Representation Learning
Oct 31, 2025Equivariant representation learning aims to capture variations induced by input transformations in the representation space, whereas invariant representation learning encodes semantic information by disregarding such transformations. Recent studies have shown that jointly learning both types of representations is often beneficial for downstream tasks, typically by employing separate projection heads. However, this design overlooks information shared between invariant and equivariant learning, which leads to redundant feature learning and inefficient use of model capacity. To address this, we introduce Soft Task-Aware Routing (STAR), a routing strategy for projection heads that models them as experts. STAR induces the experts to specialize in capturing either shared or task-specific information, thereby reducing redundant feature learning. We validate this effect by observing lower canonical correlations between invariant and equivariant embeddings. Experimental results show consistent improvements across diverse transfer learning tasks. The code is available at https://github.com/YonseiML/star.
On the Similarities of Embeddings in Contrastive Learning
Jun 11, 2025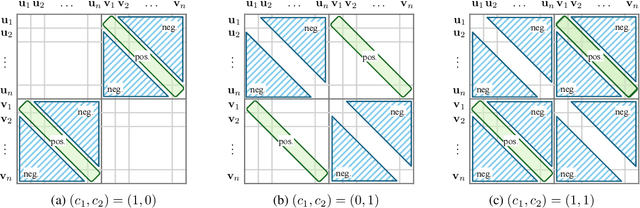
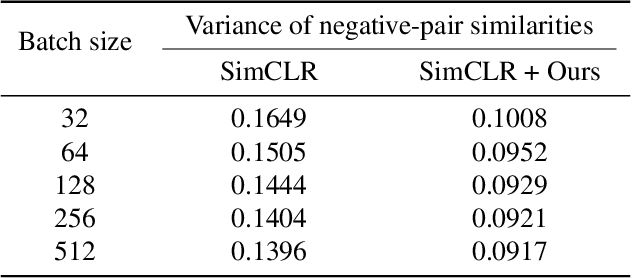
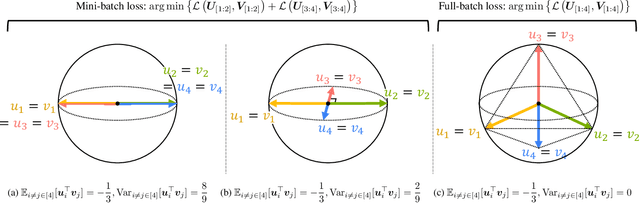
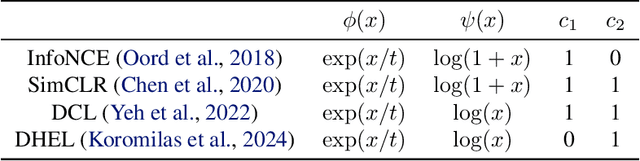
Contrastive learning (CL) operates on a simple yet effective principle: embeddings of positive pairs are pulled together, while those of negative pairs are pushed apart. Although various forms of contrastive loss have been proposed and analyzed from different perspectives, prior works lack a comprehensive framework that systematically explains a broad class of these objectives. In this paper, we present a unified framework for understanding CL, which is based on analyzing the cosine similarity between embeddings of positive and negative pairs. In full-batch settings, we show that perfect alignment of positive pairs is unattainable when similarities of negative pairs fall below a certain threshold, and that this misalignment can be alleviated by incorporating within-view negative pairs. In mini-batch settings, we demonstrate that smaller batch sizes incur stronger separation among negative pairs within batches, which leads to higher variance in similarities of negative pairs. To address this limitation of mini-batch CL, we introduce an auxiliary loss term that reduces the variance of similarities of negative pairs in CL. Empirical results demonstrate that incorporating the proposed loss consistently improves the performance of CL methods in small-batch training.
* contrastive learning, representation learning, embedding, similarity, negative pair, positive pair
Understanding the behavior of representation forgetting in continual learning
May 28, 2025In continual learning scenarios, catastrophic forgetting of previously learned tasks is a critical issue, making it essential to effectively measure such forgetting. Recently, there has been growing interest in focusing on representation forgetting, the forgetting measured at the hidden layer. In this paper, we provide the first theoretical analysis of representation forgetting and use this analysis to better understand the behavior of continual learning. First, we introduce a new metric called representation discrepancy, which measures the difference between representation spaces constructed by two snapshots of a model trained through continual learning. We demonstrate that our proposed metric serves as an effective surrogate for the representation forgetting while remaining analytically tractable. Second, through mathematical analysis of our metric, we derive several key findings about the dynamics of representation forgetting: the forgetting occurs more rapidly to a higher degree as the layer index increases, while increasing the width of the network slows down the forgetting process. Third, we support our theoretical findings through experiments on real image datasets, including Split-CIFAR100 and ImageNet1K.
FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation
Apr 22, 2025In the fast-paced financial domain, accurate and up-to-date information is critical to addressing ever-evolving market conditions. Retrieving this information correctly is essential in financial Question-Answering (QA), since many language models struggle with factual accuracy in this domain. We present FinDER, an expert-generated dataset tailored for Retrieval-Augmented Generation (RAG) in finance. Unlike existing QA datasets that provide predefined contexts and rely on relatively clear and straightforward queries, FinDER focuses on annotating search-relevant evidence by domain experts, offering 5,703 query-evidence-answer triplets derived from real-world financial inquiries. These queries frequently include abbreviations, acronyms, and concise expressions, capturing the brevity and ambiguity common in the realistic search behavior of professionals. By challenging models to retrieve relevant information from large corpora rather than relying on readily determined contexts, FinDER offers a more realistic benchmark for evaluating RAG systems. We further present a comprehensive evaluation of multiple state-of-the-art retrieval models and Large Language Models, showcasing challenges derived from a realistic benchmark to drive future research on truthful and precise RAG in the financial domain.
A Theoretical Framework for Preventing Class Collapse in Supervised Contrastive Learning
Mar 11, 2025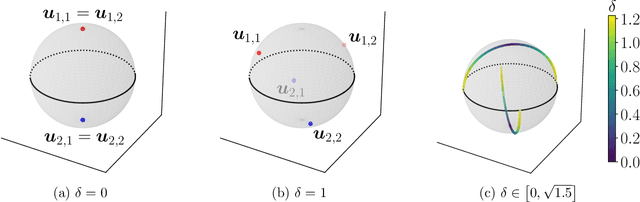

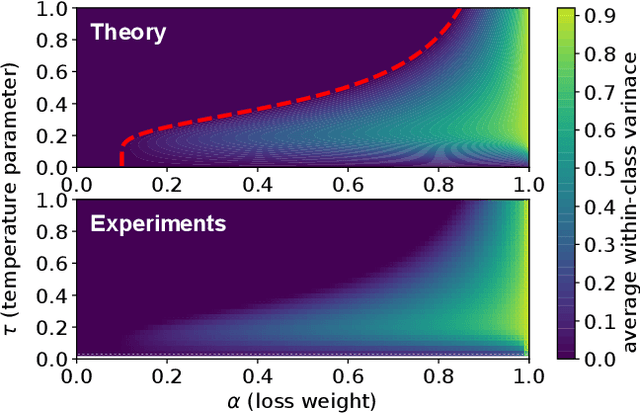
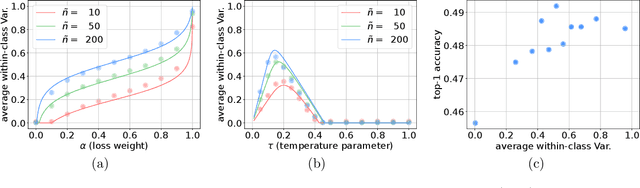
Supervised contrastive learning (SupCL) has emerged as a prominent approach in representation learning, leveraging both supervised and self-supervised losses. However, achieving an optimal balance between these losses is challenging; failing to do so can lead to class collapse, reducing discrimination among individual embeddings in the same class. In this paper, we present theoretically grounded guidelines for SupCL to prevent class collapse in learned representations. Specifically, we introduce the Simplex-to-Simplex Embedding Model (SSEM), a theoretical framework that models various embedding structures, including all embeddings that minimize the supervised contrastive loss. Through SSEM, we analyze how hyperparameters affect learned representations, offering practical guidelines for hyperparameter selection to mitigate the risk of class collapse. Our theoretical findings are supported by empirical results across synthetic and real-world datasets.
Linq-Embed-Mistral Technical Report
Dec 04, 2024
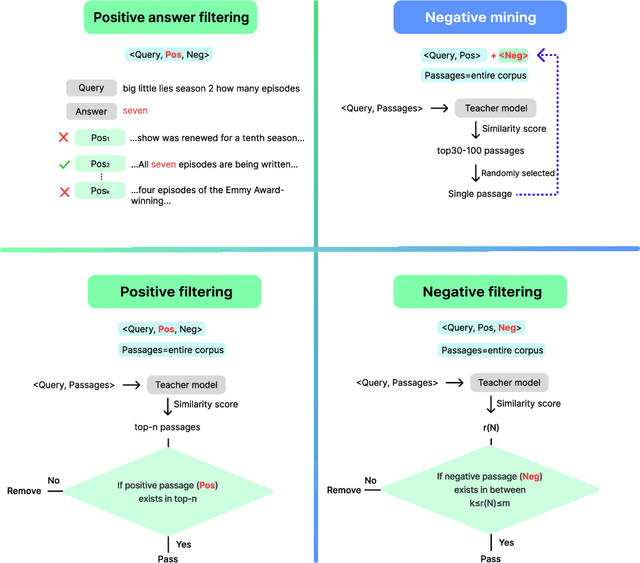

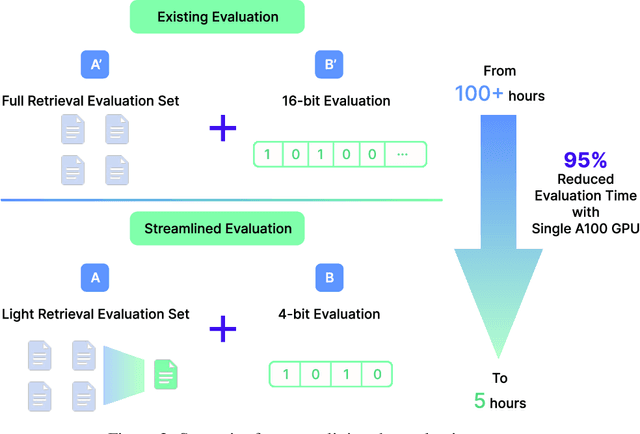
This report explores the enhancement of text retrieval performance using advanced data refinement techniques. We develop Linq-Embed-Mistral\footnote{\url{https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral}} by building on the E5-mistral and Mistral-7B-v0.1 models, focusing on sophisticated data crafting, data filtering, and negative mining methods, which are highly tailored to each task, applied to both existing benchmark dataset and highly tailored synthetic dataset generated via large language models (LLMs). Linq-Embed-Mistral excels in the MTEB benchmarks (as of May 29, 2024), achieving an average score of 68.2 across 56 datasets, and ranks 1st among all models for retrieval tasks on the MTEB leaderboard with a performance score of 60.2. This performance underscores its superior capability in enhancing search precision and reliability. Our contributions include advanced data refinement methods that significantly improve model performance on benchmark and synthetic datasets, techniques for homogeneous task ordering and mixed task fine-tuning to enhance model generalization and stability, and a streamlined evaluation process using 4-bit precision and a light retrieval evaluation set, which accelerates validation without sacrificing accuracy.
Buffer-based Gradient Projection for Continual Federated Learning
Sep 03, 2024Continual Federated Learning (CFL) is essential for enabling real-world applications where multiple decentralized clients adaptively learn from continuous data streams. A significant challenge in CFL is mitigating catastrophic forgetting, where models lose previously acquired knowledge when learning new information. Existing approaches often face difficulties due to the constraints of device storage capacities and the heterogeneous nature of data distributions among clients. While some CFL algorithms have addressed these challenges, they frequently rely on unrealistic assumptions about the availability of task boundaries (i.e., knowing when new tasks begin). To address these limitations, we introduce Fed-A-GEM, a federated adaptation of the A-GEM method (Chaudhry et al., 2019), which employs a buffer-based gradient projection approach. Fed-A-GEM alleviates catastrophic forgetting by leveraging local buffer samples and aggregated buffer gradients, thus preserving knowledge across multiple clients. Our method is combined with existing CFL techniques, enhancing their performance in the CFL context. Our experiments on standard benchmarks show consistent performance improvements across diverse scenarios. For example, in a task-incremental learning scenario using the CIFAR-100 dataset, our method can increase the accuracy by up to 27%. Our code is available at https://github.com/shenghongdai/Fed-A-GEM.
Memorization Capacity for Additive Fine-Tuning with Small ReLU Networks
Aug 01, 2024

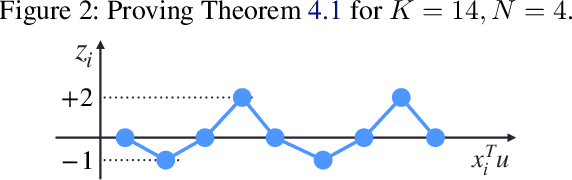
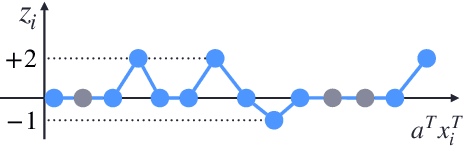
Fine-tuning large pre-trained models is a common practice in machine learning applications, yet its mathematical analysis remains largely unexplored. In this paper, we study fine-tuning through the lens of memorization capacity. Our new measure, the Fine-Tuning Capacity (FTC), is defined as the maximum number of samples a neural network can fine-tune, or equivalently, as the minimum number of neurons ($m$) needed to arbitrarily change $N$ labels among $K$ samples considered in the fine-tuning process. In essence, FTC extends the memorization capacity concept to the fine-tuning scenario. We analyze FTC for the additive fine-tuning scenario where the fine-tuned network is defined as the summation of the frozen pre-trained network $f$ and a neural network $g$ (with $m$ neurons) designed for fine-tuning. When $g$ is a ReLU network with either 2 or 3 layers, we obtain tight upper and lower bounds on FTC; we show that $N$ samples can be fine-tuned with $m=\Theta(N)$ neurons for 2-layer networks, and with $m=\Theta(\sqrt{N})$ neurons for 3-layer networks, no matter how large $K$ is. Our results recover the known memorization capacity results when $N = K$ as a special case.