 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Continual Learning of Vision-Language Models via Dynamic Prefix Weighting
Apr 20, 2026We investigate recently introduced domain-class incremental learning scenarios for vision-language models (VLMs). Recent works address this challenge using parameter-efficient methods, such as prefix-tuning or adapters, which facilitate model adaptation to downstream tasks by incorporating task-specific information into input tokens through additive vectors. However, previous approaches often normalize the weights of these vectors, disregarding the fact that different input tokens require different degrees of adjustment. To overcome this issue, we propose Dynamic Prefix Weighting (DPW), a framework that dynamically assigns weights to prefixes, complemented by adapters. DPW consists of 1) a gating module that adjusts the weights of each prefix based on the importance of the corresponding input token, and 2) a weighting mechanism that derives adapter output weights as a residual of prefix-tuning weights, ensuring that adapters are utilized only when necessary. Experimental results demonstrate that our method achieves state-of-the-art performance in domain-class incremental learning scenarios for VLMs. The code is available at: https://github.com/YonseiML/dpw.
When and Where to Reset Matters for Long-Term Test-Time Adaptation
Mar 04, 2026When continual test-time adaptation (TTA) persists over the long term, errors accumulate in the model and further cause it to predict only a few classes for all inputs, a phenomenon known as model collapse. Recent studies have explored reset strategies that completely erase these accumulated errors. However, their periodic resets lead to suboptimal adaptation, as they occur independently of the actual risk of collapse. Moreover, their full resets cause catastrophic loss of knowledge acquired over time, even though such knowledge could be beneficial in the future. To this end, we propose (1) an Adaptive and Selective Reset (ASR) scheme that dynamically determines when and where to reset, (2) an importance-aware regularizer to recover essential knowledge lost due to reset, and (3) an on-the-fly adaptation adjustment scheme to enhance adaptability under challenging domain shifts. Extensive experiments across long-term TTA benchmarks demonstrate the effectiveness of our approach, particularly under challenging conditions. Our code is available at https://github.com/YonseiML/asr.
Soft Task-Aware Routing of Experts for Equivariant Representation Learning
Oct 31, 2025Equivariant representation learning aims to capture variations induced by input transformations in the representation space, whereas invariant representation learning encodes semantic information by disregarding such transformations. Recent studies have shown that jointly learning both types of representations is often beneficial for downstream tasks, typically by employing separate projection heads. However, this design overlooks information shared between invariant and equivariant learning, which leads to redundant feature learning and inefficient use of model capacity. To address this, we introduce Soft Task-Aware Routing (STAR), a routing strategy for projection heads that models them as experts. STAR induces the experts to specialize in capturing either shared or task-specific information, thereby reducing redundant feature learning. We validate this effect by observing lower canonical correlations between invariant and equivariant embeddings. Experimental results show consistent improvements across diverse transfer learning tasks. The code is available at https://github.com/YonseiML/star.
On the Similarities of Embeddings in Contrastive Learning
Jun 11, 2025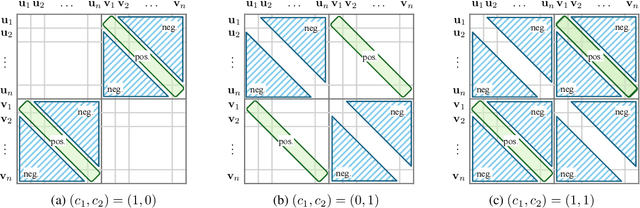
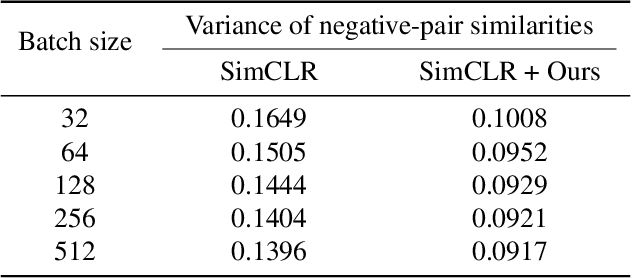
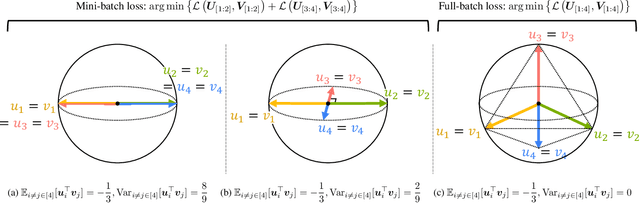
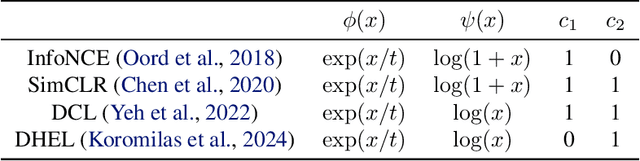
Contrastive learning (CL) operates on a simple yet effective principle: embeddings of positive pairs are pulled together, while those of negative pairs are pushed apart. Although various forms of contrastive loss have been proposed and analyzed from different perspectives, prior works lack a comprehensive framework that systematically explains a broad class of these objectives. In this paper, we present a unified framework for understanding CL, which is based on analyzing the cosine similarity between embeddings of positive and negative pairs. In full-batch settings, we show that perfect alignment of positive pairs is unattainable when similarities of negative pairs fall below a certain threshold, and that this misalignment can be alleviated by incorporating within-view negative pairs. In mini-batch settings, we demonstrate that smaller batch sizes incur stronger separation among negative pairs within batches, which leads to higher variance in similarities of negative pairs. To address this limitation of mini-batch CL, we introduce an auxiliary loss term that reduces the variance of similarities of negative pairs in CL. Empirical results demonstrate that incorporating the proposed loss consistently improves the performance of CL methods in small-batch training.
* contrastive learning, representation learning, embedding, similarity, negative pair, positive pair
A Theoretical Framework for Preventing Class Collapse in Supervised Contrastive Learning
Mar 11, 2025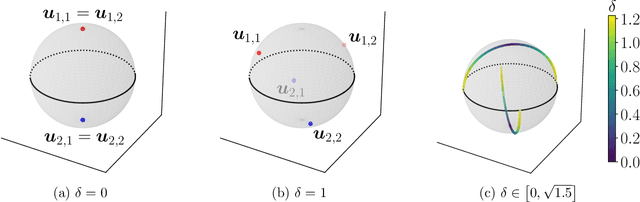

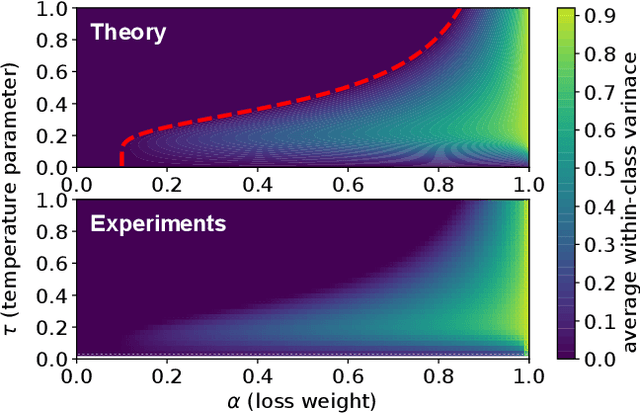
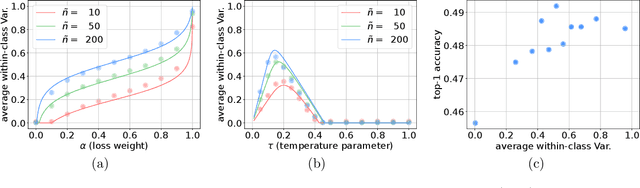
Supervised contrastive learning (SupCL) has emerged as a prominent approach in representation learning, leveraging both supervised and self-supervised losses. However, achieving an optimal balance between these losses is challenging; failing to do so can lead to class collapse, reducing discrimination among individual embeddings in the same class. In this paper, we present theoretically grounded guidelines for SupCL to prevent class collapse in learned representations. Specifically, we introduce the Simplex-to-Simplex Embedding Model (SSEM), a theoretical framework that models various embedding structures, including all embeddings that minimize the supervised contrastive loss. Through SSEM, we analyze how hyperparameters affect learned representations, offering practical guidelines for hyperparameter selection to mitigate the risk of class collapse. Our theoretical findings are supported by empirical results across synthetic and real-world datasets.
To Predict or Not To Predict? Proportionally Masked Autoencoders for Tabular Data Imputation
Dec 26, 2024
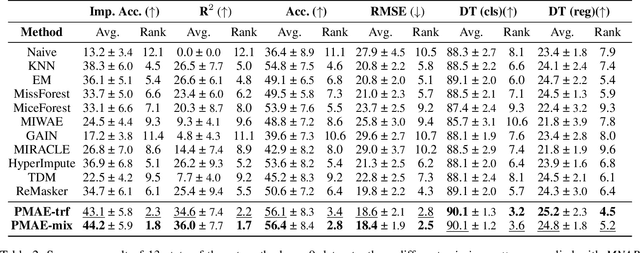
Masked autoencoders (MAEs) have recently demonstrated effectiveness in tabular data imputation. However, due to the inherent heterogeneity of tabular data, the uniform random masking strategy commonly used in MAEs can disrupt the distribution of missingness, leading to suboptimal performance. To address this, we propose a proportional masking strategy for MAEs. Specifically, we first compute the statistics of missingness based on the observed proportions in the dataset, and then generate masks that align with these statistics, ensuring that the distribution of missingness is preserved after masking. Furthermore, we argue that simple MLP-based token mixing offers competitive or often superior performance compared to attention mechanisms while being more computationally efficient, especially in the tabular domain with the inherent heterogeneity. Experimental results validate the effectiveness of the proposed proportional masking strategy across various missing data patterns in tabular datasets. Code is available at: \url{https://github.com/normal-kim/PMAE}.
Partial Channel Dependence with Channel Masks for Time Series Foundation Models
Oct 30, 2024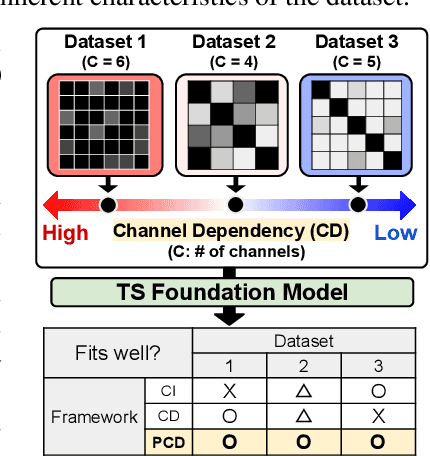
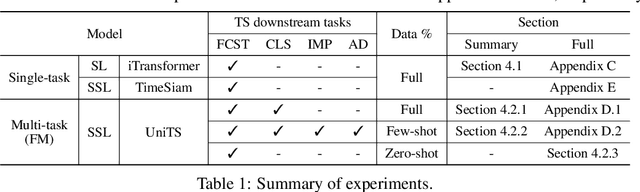
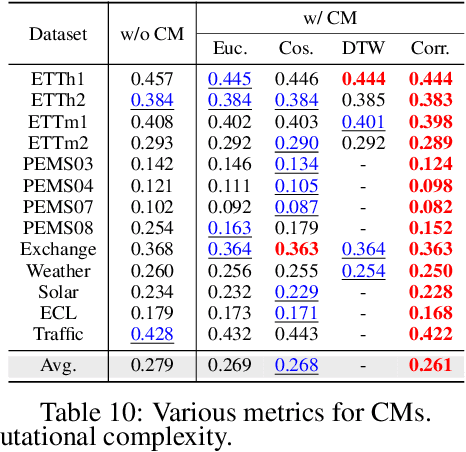
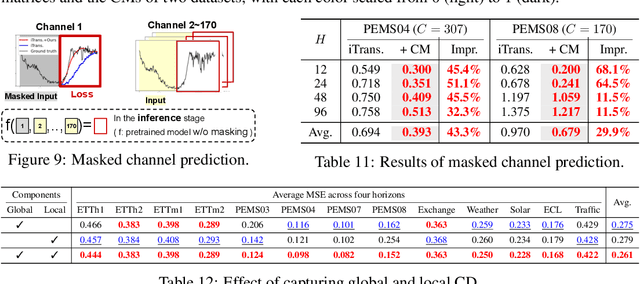
Recent advancements in foundation models have been successfully extended to the time series (TS) domain, facilitated by the emergence of large-scale TS datasets. However, previous efforts have primarily focused on designing model architectures to address explicit heterogeneity among datasets such as various numbers of channels, while often overlooking implicit heterogeneity such as varying dependencies between channels. In this work, we introduce the concept of partial channel dependence (PCD), which enables a more sophisticated adjustment of channel dependencies based on dataset-specific information. To achieve PCD, we propose a channel mask that captures the relationships between channels within a dataset using two key components: 1) a correlation matrix that encodes relative dependencies between channels, and 2) domain parameters that learn the absolute dependencies specific to each dataset, refining the correlation matrix. We validate the effectiveness of PCD across four tasks in TS including forecasting, classification, imputation, and anomaly detection, under diverse settings, including few-shot and zero-shot scenarios with both TS foundation models and single-task models. Code is available at https://github.com/seunghan96/CM.
Sequential Order-Robust Mamba for Time Series Forecasting
Oct 30, 2024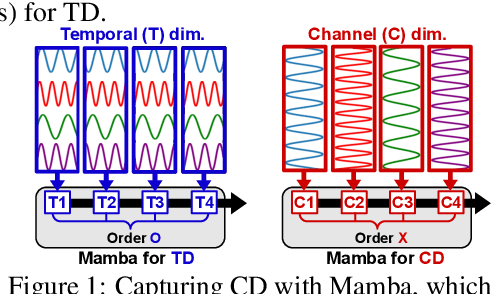
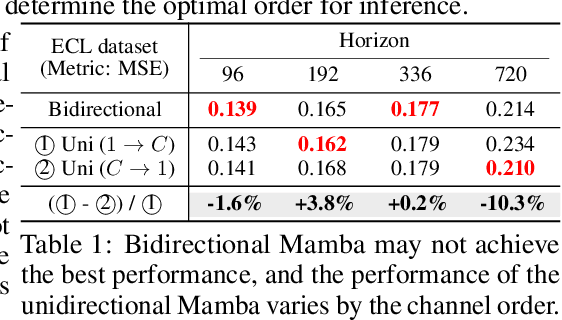
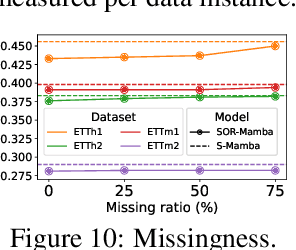
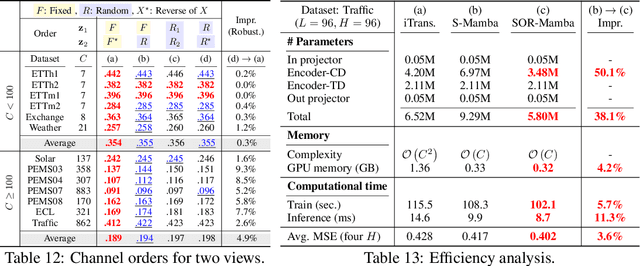
Mamba has recently emerged as a promising alternative to Transformers, offering near-linear complexity in processing sequential data. However, while channels in time series (TS) data have no specific order in general, recent studies have adopted Mamba to capture channel dependencies (CD) in TS, introducing a sequential order bias. To address this issue, we propose SOR-Mamba, a TS forecasting method that 1) incorporates a regularization strategy to minimize the discrepancy between two embedding vectors generated from data with reversed channel orders, thereby enhancing robustness to channel order, and 2) eliminates the 1D-convolution originally designed to capture local information in sequential data. Furthermore, we introduce channel correlation modeling (CCM), a pretraining task aimed at preserving correlations between channels from the data space to the latent space in order to enhance the ability to capture CD. Extensive experiments demonstrate the efficacy of the proposed method across standard and transfer learning scenarios. Code is available at https://github.com/seunghan96/SOR-Mamba.
ANT: Adaptive Noise Schedule for Time Series Diffusion Models
Oct 18, 2024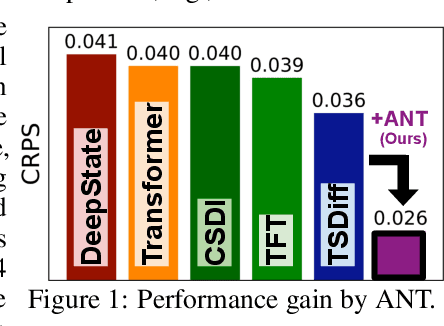
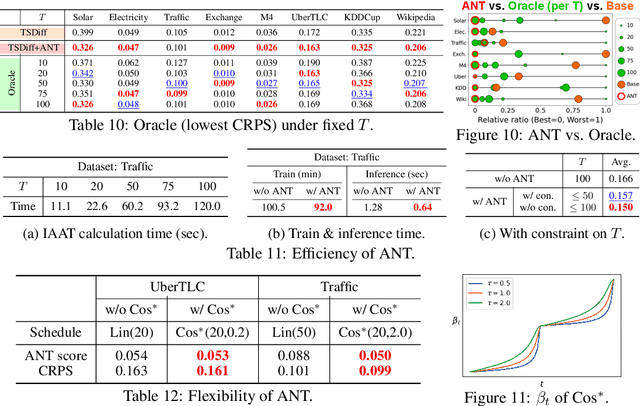
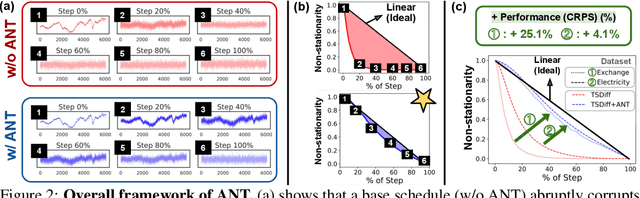
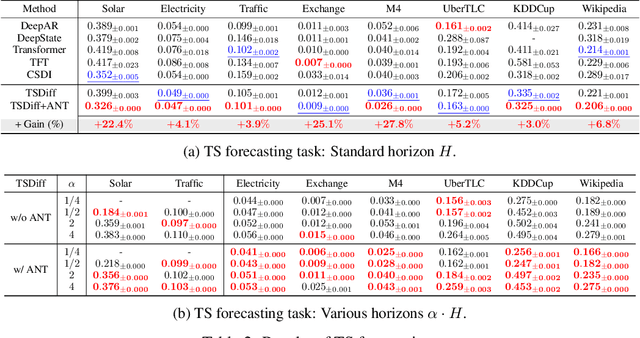
Advances in diffusion models for generative artificial intelligence have recently propagated to the time series (TS) domain, demonstrating state-of-the-art performance on various tasks. However, prior works on TS diffusion models often borrow the framework of existing works proposed in other domains without considering the characteristics of TS data, leading to suboptimal performance. In this work, we propose Adaptive Noise schedule for Time series diffusion models (ANT), which automatically predetermines proper noise schedules for given TS datasets based on their statistics representing non-stationarity. Our intuition is that an optimal noise schedule should satisfy the following desiderata: 1) It linearly reduces the non-stationarity of TS data so that all diffusion steps are equally meaningful, 2) the data is corrupted to the random noise at the final step, and 3) the number of steps is sufficiently large. The proposed method is practical for use in that it eliminates the necessity of finding the optimal noise schedule with a small additional cost to compute the statistics for given datasets, which can be done offline before training. We validate the effectiveness of our method across various tasks, including TS forecasting, refinement, and generation, on datasets from diverse domains. Code is available at this repository: https://github.com/seunghan96/ANT.
On the Effectiveness of Supervision in Asymmetric Non-Contrastive Learning
Jun 16, 2024Supervised contrastive representation learning has been shown to be effective in various transfer learning scenarios. However, while asymmetric non-contrastive learning (ANCL) often outperforms its contrastive learning counterpart in self-supervised representation learning, the extension of ANCL to supervised scenarios is less explored. To bridge the gap, we study ANCL for supervised representation learning, coined SupSiam and SupBYOL, leveraging labels in ANCL to achieve better representations. The proposed supervised ANCL framework improves representation learning while avoiding collapse. Our analysis reveals that providing supervision to ANCL reduces intra-class variance, and the contribution of supervision should be adjusted to achieve the best performance. Experiments demonstrate the superiority of supervised ANCL across various datasets and tasks. The code is available at: https://github.com/JH-Oh-23/Sup-ANCL.