 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescriptive Image-Text Matching with Graded Contextual Similarity
May 15, 2025Image-text matching aims to build correspondences between visual and textual data by learning their pairwise similarities. Most existing approaches have adopted sparse binary supervision, indicating whether a pair of images and sentences matches or not. However, such sparse supervision covers a limited subset of image-text relationships, neglecting their inherent many-to-many correspondences; an image can be described in numerous texts at different descriptive levels. Moreover, existing approaches overlook the implicit connections from general to specific descriptions, which form the underlying rationale for the many-to-many relationships between vision and language. In this work, we propose descriptive image-text matching, called DITM, to learn the graded contextual similarity between image and text by exploring the descriptive flexibility of language. We formulate the descriptiveness score of each sentence with cumulative term frequency-inverse document frequency (TF-IDF) to balance the pairwise similarity according to the keywords in the sentence. Our method leverages sentence descriptiveness to learn robust image-text matching in two key ways: (1) to refine the false negative labeling, dynamically relaxing the connectivity between positive and negative pairs, and (2) to build more precise matching, aligning a set of relevant sentences in a generic-to-specific order. By moving beyond rigid binary supervision, DITM enhances the discovery of both optimal matches and potential positive pairs. Extensive experiments on MS-COCO, Flickr30K, and CxC datasets demonstrate the effectiveness of our method in representing complex image-text relationships compared to state-of-the-art approaches. In addition, DITM enhances the hierarchical reasoning ability of the model, supported by the extensive analysis on HierarCaps benchmark.
Faster Parameter-Efficient Tuning with Token Redundancy Reduction
Mar 26, 2025



Parameter-efficient tuning (PET) aims to transfer pre-trained foundation models to downstream tasks by learning a small number of parameters. Compared to traditional fine-tuning, which updates the entire model, PET significantly reduces storage and transfer costs for each task regardless of exponentially increasing pre-trained model capacity. However, most PET methods inherit the inference latency of their large backbone models and often introduce additional computational overhead due to additional modules (e.g. adapters), limiting their practicality for compute-intensive applications. In this paper, we propose Faster Parameter-Efficient Tuning (FPET), a novel approach that enhances inference speed and training efficiency while maintaining high storage efficiency. Specifically, we introduce a plug-and-play token redundancy reduction module delicately designed for PET. This module refines tokens from the self-attention layer using an adapter to learn the accurate similarity between tokens and cuts off the tokens through a fully-differentiable token merging strategy, which uses a straight-through estimator for optimal token reduction. Experimental results prove that our FPET achieves faster inference and higher memory efficiency than the pre-trained backbone while keeping competitive performance on par with state-of-the-art PET methods.
Bootstrap Your Own Views: Masked Ego-Exo Modeling for Fine-grained View-invariant Video Representations
Mar 25, 2025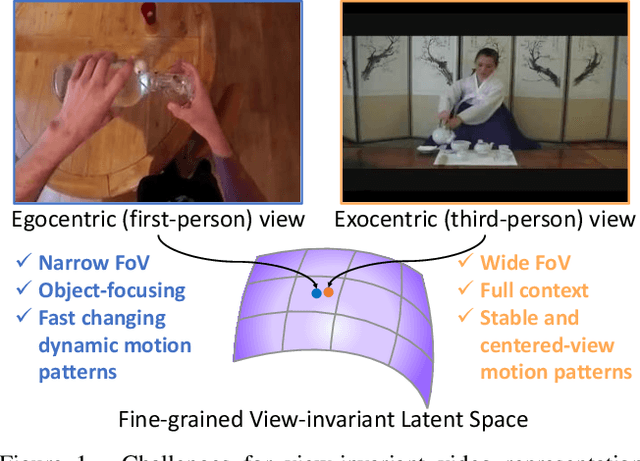
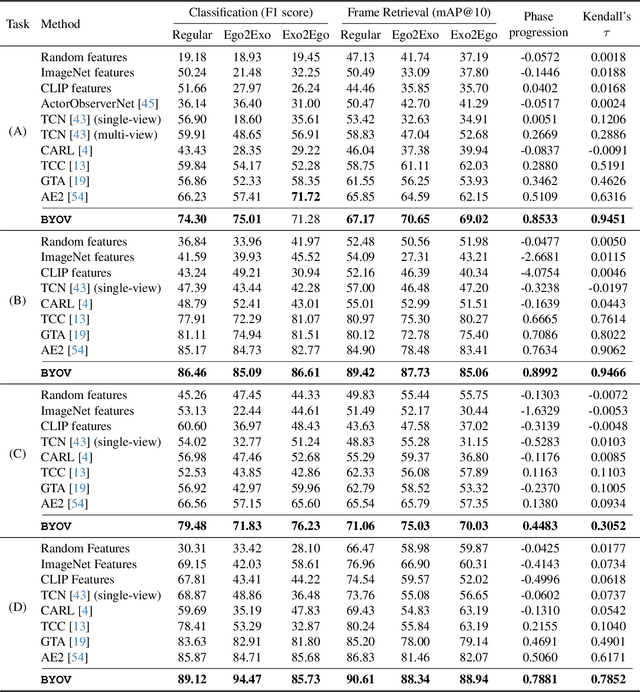
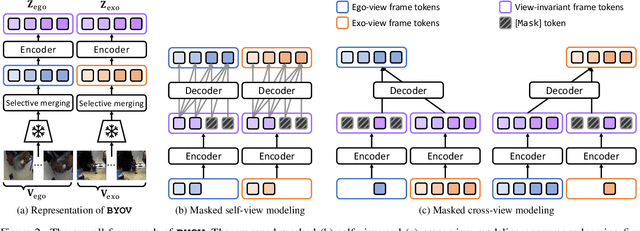

View-invariant representation learning from egocentric (first-person, ego) and exocentric (third-person, exo) videos is a promising approach toward generalizing video understanding systems across multiple viewpoints. However, this area has been underexplored due to the substantial differences in perspective, motion patterns, and context between ego and exo views. In this paper, we propose a novel masked ego-exo modeling that promotes both causal temporal dynamics and cross-view alignment, called Bootstrap Your Own Views (BYOV), for fine-grained view-invariant video representation learning from unpaired ego-exo videos. We highlight the importance of capturing the compositional nature of human actions as a basis for robust cross-view understanding. Specifically, self-view masking and cross-view masking predictions are designed to learn view-invariant and powerful representations concurrently. Experimental results demonstrate that our BYOV significantly surpasses existing approaches with notable gains across all metrics in four downstream ego-exo video tasks. The code is available at https://github.com/park-jungin/byov.
EBDM: Exemplar-guided Image Translation with Brownian-bridge Diffusion Models
Oct 13, 2024Exemplar-guided image translation, synthesizing photo-realistic images that conform to both structural control and style exemplars, is attracting attention due to its ability to enhance user control over style manipulation. Previous methodologies have predominantly depended on establishing dense correspondences across cross-domain inputs. Despite these efforts, they incur quadratic memory and computational costs for establishing dense correspondence, resulting in limited versatility and performance degradation. In this paper, we propose a novel approach termed Exemplar-guided Image Translation with Brownian-Bridge Diffusion Models (EBDM). Our method formulates the task as a stochastic Brownian bridge process, a diffusion process with a fixed initial point as structure control and translates into the corresponding photo-realistic image while being conditioned solely on the given exemplar image. To efficiently guide the diffusion process toward the style of exemplar, we delineate three pivotal components: the Global Encoder, the Exemplar Network, and the Exemplar Attention Module to incorporate global and detailed texture information from exemplar images. Leveraging Bridge diffusion, the network can translate images from structure control while exclusively conditioned on the exemplar style, leading to more robust training and inference processes. We illustrate the superiority of our method over competing approaches through comprehensive benchmark evaluations and visual results.
Enhancing Source-Free Domain Adaptive Object Detection with Low-confidence Pseudo Label Distillation
Jul 18, 2024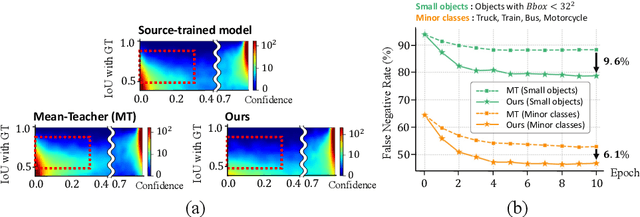
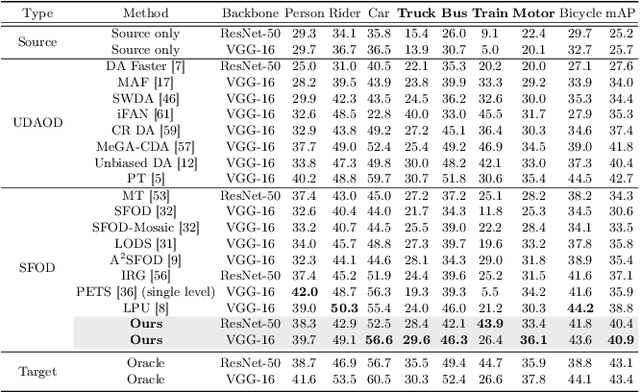
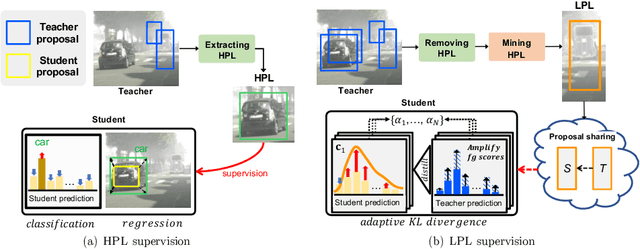
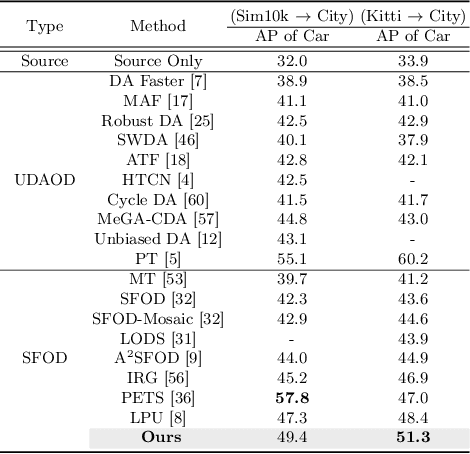
Source-Free domain adaptive Object Detection (SFOD) is a promising strategy for deploying trained detectors to new, unlabeled domains without accessing source data, addressing significant concerns around data privacy and efficiency. Most SFOD methods leverage a Mean-Teacher (MT) self-training paradigm relying heavily on High-confidence Pseudo Labels (HPL). However, these HPL often overlook small instances that undergo significant appearance changes with domain shifts. Additionally, HPL ignore instances with low confidence due to the scarcity of training samples, resulting in biased adaptation toward familiar instances from the source domain. To address this limitation, we introduce the Low-confidence Pseudo Label Distillation (LPLD) loss within the Mean-Teacher based SFOD framework. This novel approach is designed to leverage the proposals from Region Proposal Network (RPN), which potentially encompasses hard-to-detect objects in unfamiliar domains. Initially, we extract HPL using a standard pseudo-labeling technique and mine a set of Low-confidence Pseudo Labels (LPL) from proposals generated by RPN, leaving those that do not overlap significantly with HPL. These LPL are further refined by leveraging class-relation information and reducing the effect of inherent noise for the LPLD loss calculation. Furthermore, we use feature distance to adaptively weight the LPLD loss to focus on LPL containing a larger foreground area. Our method outperforms previous SFOD methods on four cross-domain object detection benchmarks. Extensive experiments demonstrate that our LPLD loss leads to effective adaptation by reducing false negatives and facilitating the use of domain-invariant knowledge from the source model. Code is available at https://github.com/junia3/LPLD.
Rethinking Open-World Semi-Supervised Learning: Distribution Mismatch and Inductive Inference
May 31, 2024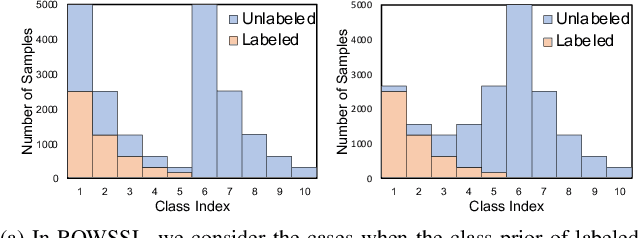
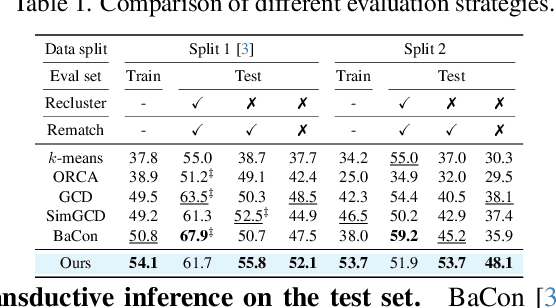
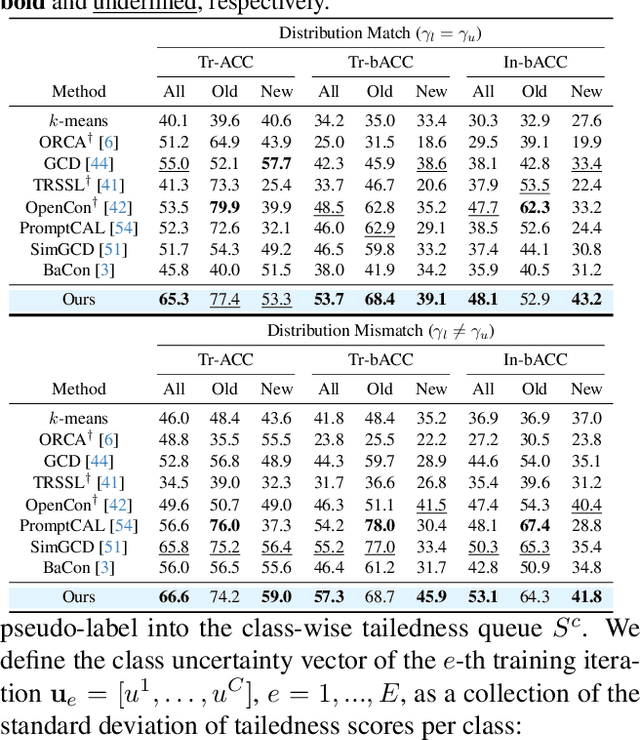
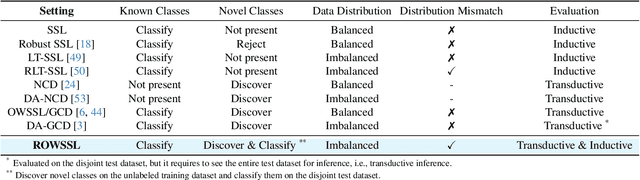
Open-world semi-supervised learning (OWSSL) extends conventional semi-supervised learning to open-world scenarios by taking account of novel categories in unlabeled datasets. Despite the recent advancements in OWSSL, the success often relies on the assumptions that 1) labeled and unlabeled datasets share the same balanced class prior distribution, which does not generally hold in real-world applications, and 2) unlabeled training datasets are utilized for evaluation, where such transductive inference might not adequately address challenges in the wild. In this paper, we aim to generalize OWSSL by addressing them. Our work suggests that practical OWSSL may require different training settings, evaluation methods, and learning strategies compared to those prevalent in the existing literature.
Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
May 07, 2024
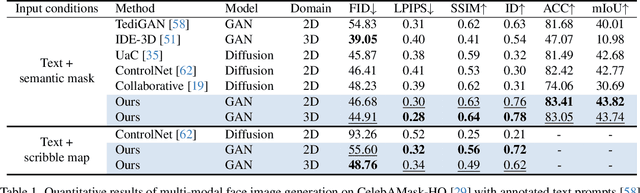
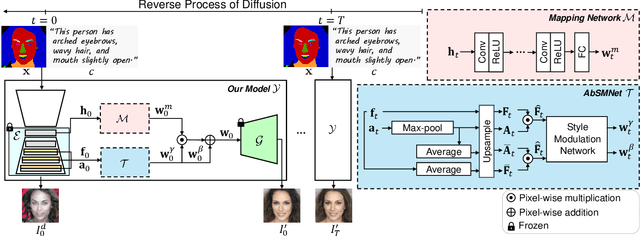
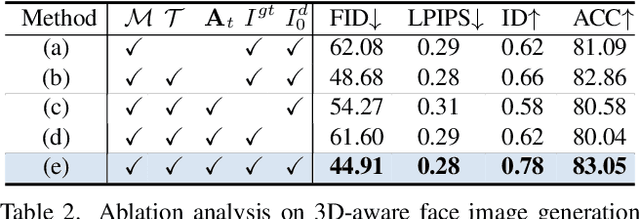
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
Bridging Vision and Language Spaces with Assignment Prediction
Apr 15, 2024
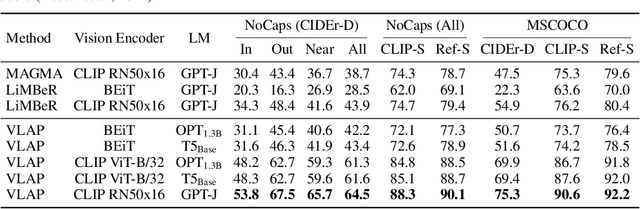


This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
Improving Visual Recognition with Hyperbolical Visual Hierarchy Mapping
Apr 01, 2024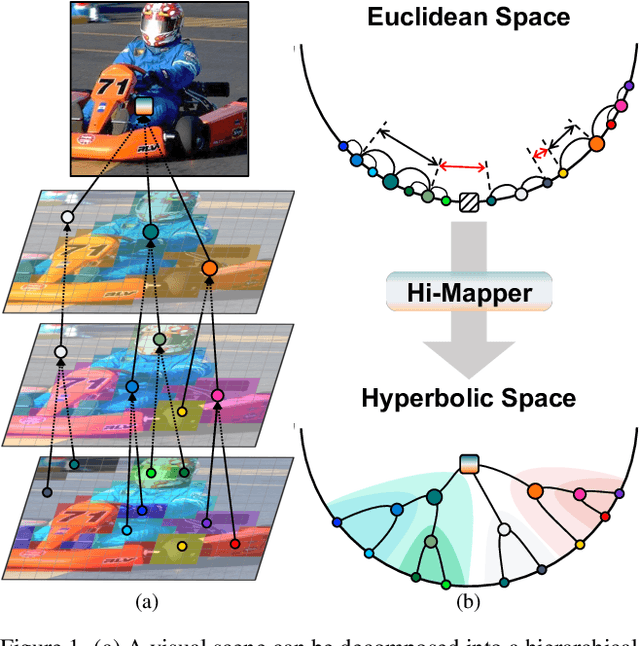
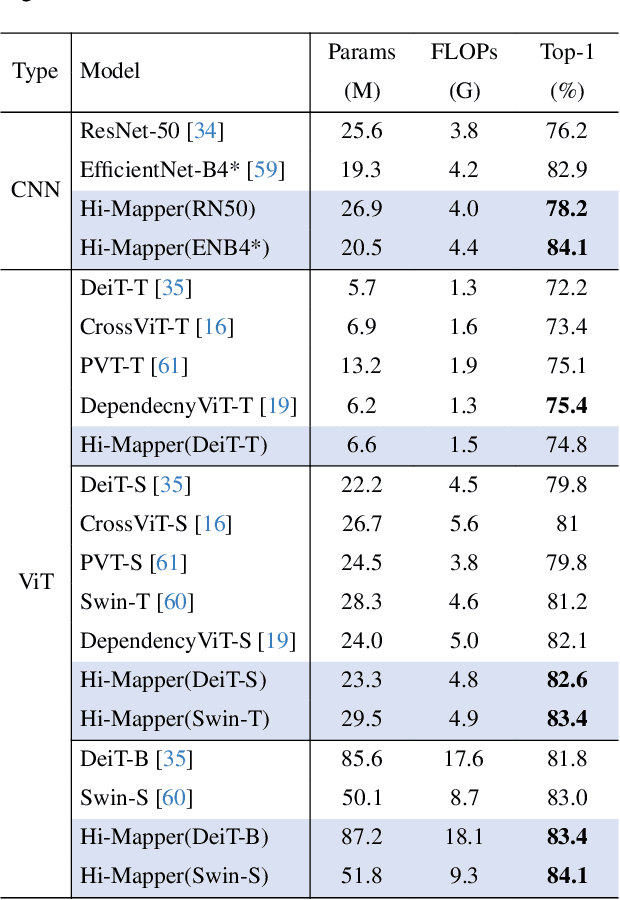
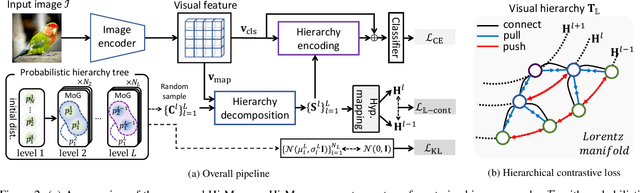
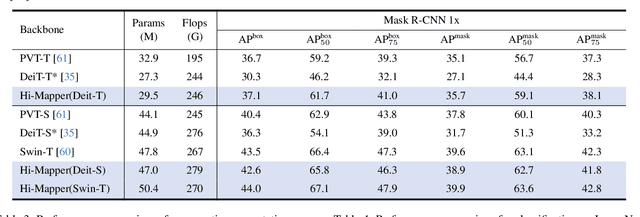
Visual scenes are naturally organized in a hierarchy, where a coarse semantic is recursively comprised of several fine details. Exploring such a visual hierarchy is crucial to recognize the complex relations of visual elements, leading to a comprehensive scene understanding. In this paper, we propose a Visual Hierarchy Mapper (Hi-Mapper), a novel approach for enhancing the structured understanding of the pre-trained Deep Neural Networks (DNNs). Hi-Mapper investigates the hierarchical organization of the visual scene by 1) pre-defining a hierarchy tree through the encapsulation of probability densities; and 2) learning the hierarchical relations in hyperbolic space with a novel hierarchical contrastive loss. The pre-defined hierarchy tree recursively interacts with the visual features of the pre-trained DNNs through hierarchy decomposition and encoding procedures, thereby effectively identifying the visual hierarchy and enhancing the recognition of an entire scene. Extensive experiments demonstrate that Hi-Mapper significantly enhances the representation capability of DNNs, leading to an improved performance on various tasks, including image classification and dense prediction tasks.
Layer-wise Auto-Weighting for Non-Stationary Test-Time Adaptation
Nov 26, 2023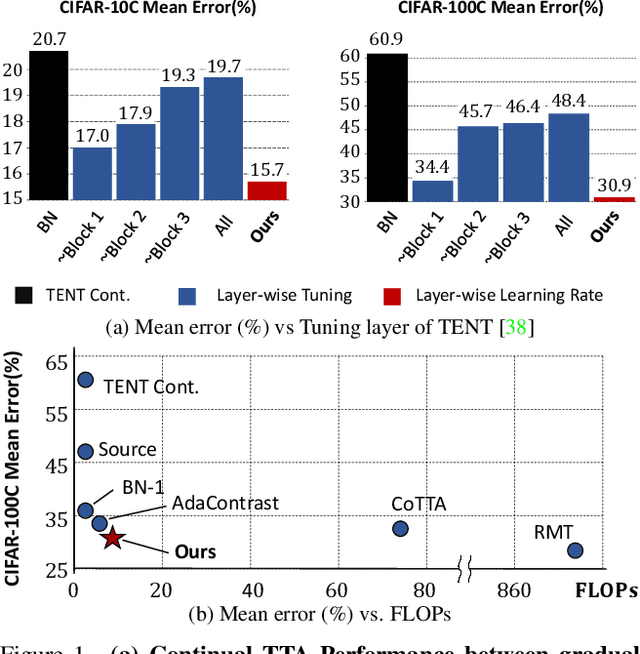
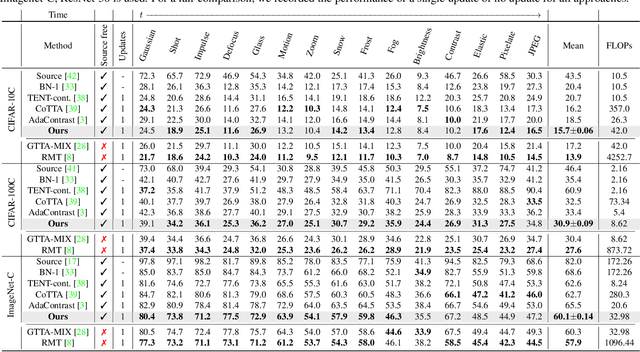
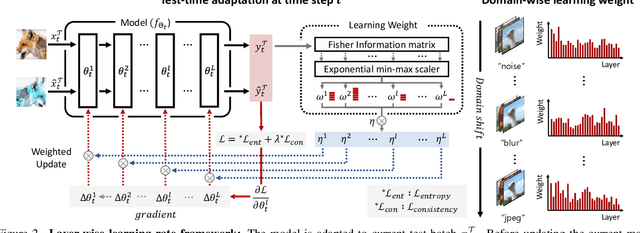
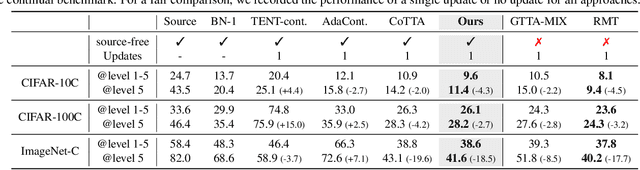
Given the inevitability of domain shifts during inference in real-world applications, test-time adaptation (TTA) is essential for model adaptation after deployment. However, the real-world scenario of continuously changing target distributions presents challenges including catastrophic forgetting and error accumulation. Existing TTA methods for non-stationary domain shifts, while effective, incur excessive computational load, making them impractical for on-device settings. In this paper, we introduce a layer-wise auto-weighting algorithm for continual and gradual TTA that autonomously identifies layers for preservation or concentrated adaptation. By leveraging the Fisher Information Matrix (FIM), we first design the learning weight to selectively focus on layers associated with log-likelihood changes while preserving unrelated ones. Then, we further propose an exponential min-max scaler to make certain layers nearly frozen while mitigating outliers. This minimizes forgetting and error accumulation, leading to efficient adaptation to non-stationary target distribution. Experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C show our method outperforms conventional continual and gradual TTA approaches while significantly reducing computational load, highlighting the importance of FIM-based learning weight in adapting to continuously or gradually shifting target domains.