 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-driven GAN Inversion for Multi-Modal Face Image Generation
Paper and Code

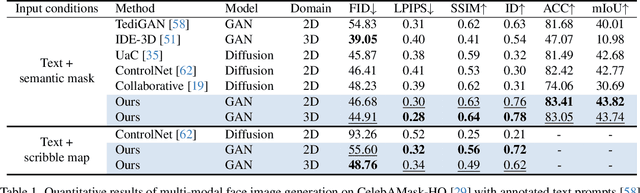
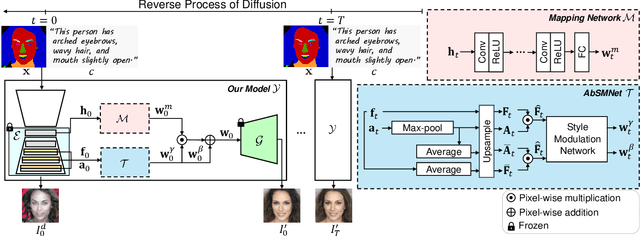
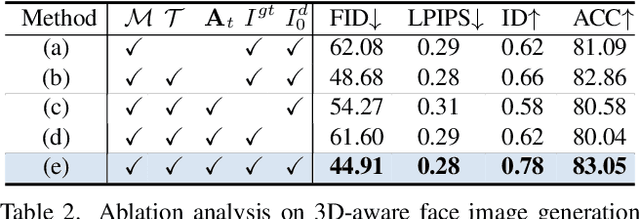
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.