 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Caption: Training-free improvement of multimodal large language model on referring expression comprehension
Feb 09, 2026Given a textual description, the task of referring expression comprehension (REC) involves the localisation of the referred object in an image. Multimodal large language models (MLLMs) have achieved high accuracy on REC benchmarks through scaling up the model size and training data. Moreover, the performance of MLLMs can be further improved using techniques such as Chain-of-Thought and tool use, which provides additional visual or textual context to the model. In this paper, we analyse the effect of various techniques for providing additional visual and textual context via tool use to the MLLM and its effect on the REC task. Furthermore, we propose a training-free framework named Chain-of-Caption to improve the REC performance of MLLMs. We perform experiments on RefCOCO/RefCOCOg/RefCOCO+ and Ref-L4 datasets and show that individual textual or visual context can improve the REC performance without any fine-tuning. By combining multiple contexts, our training-free framework shows between 5% to 30% performance gain over the baseline model on accuracy at various Intersection over Union (IoU) thresholds.
AutoMV: An Automatic Multi-Agent System for Music Video Generation
Dec 13, 2025Music-to-Video (M2V) generation for full-length songs faces significant challenges. Existing methods produce short, disjointed clips, failing to align visuals with musical structure, beats, or lyrics, and lack temporal consistency. We propose AutoMV, a multi-agent system that generates full music videos (MVs) directly from a song. AutoMV first applies music processing tools to extract musical attributes, such as structure, vocal tracks, and time-aligned lyrics, and constructs these features as contextual inputs for following agents. The screenwriter Agent and director Agent then use this information to design short script, define character profiles in a shared external bank, and specify camera instructions. Subsequently, these agents call the image generator for keyframes and different video generators for "story" or "singer" scenes. A Verifier Agent evaluates their output, enabling multi-agent collaboration to produce a coherent longform MV. To evaluate M2V generation, we further propose a benchmark with four high-level categories (Music Content, Technical, Post-production, Art) and twelve ine-grained criteria. This benchmark was applied to compare commercial products, AutoMV, and human-directed MVs with expert human raters: AutoMV outperforms current baselines significantly across all four categories, narrowing the gap to professional MVs. Finally, we investigate using large multimodal models as automatic MV judges; while promising, they still lag behind human expert, highlighting room for future work.
LaVA-Man: Learning Visual Action Representations for Robot Manipulation
Aug 26, 2025Visual-textual understanding is essential for language-guided robot manipulation. Recent works leverage pre-trained vision-language models to measure the similarity between encoded visual observations and textual instructions, and then train a model to map this similarity to robot actions. However, this two-step approach limits the model to capture the relationship between visual observations and textual instructions, leading to reduced precision in manipulation tasks. We propose to learn visual-textual associations through a self-supervised pretext task: reconstructing a masked goal image conditioned on an input image and textual instructions. This formulation allows the model to learn visual-action representations without robot action supervision. The learned representations can then be fine-tuned for manipulation tasks with only a few demonstrations. We also introduce the \textit{Omni-Object Pick-and-Place} dataset, which consists of annotated robot tabletop manipulation episodes, including 180 object classes and 3,200 instances with corresponding textual instructions. This dataset enables the model to acquire diverse object priors and allows for a more comprehensive evaluation of its generalisation capability across object instances. Experimental results on the five benchmarks, including both simulated and real-robot validations, demonstrate that our method outperforms prior art.
HanDrawer: Leveraging Spatial Information to Render Realistic Hands Using a Conditional Diffusion Model in Single Stage
Mar 03, 2025



Although diffusion methods excel in text-to-image generation, generating accurate hand gestures remains a major challenge, resulting in severe artifacts, such as incorrect number of fingers or unnatural gestures. To enable the diffusion model to learn spatial information to improve the quality of the hands generated, we propose HanDrawer, a module to condition the hand generation process. Specifically, we apply graph convolutional layers to extract the endogenous spatial structure and physical constraints implicit in MANO hand mesh vertices. We then align and fuse these spatial features with other modalities via cross-attention. The spatially fused features are used to guide a single stage diffusion model denoising process for high quality generation of the hand region. To improve the accuracy of spatial feature fusion, we propose a Position-Preserving Zero Padding (PPZP) fusion strategy, which ensures that the features extracted by HanDrawer are fused into the region of interest in the relevant layers of the diffusion model. HanDrawer learns the entire image features while paying special attention to the hand region thanks to an additional hand reconstruction loss combined with the denoising loss. To accurately train and evaluate our approach, we perform careful cleansing and relabeling of the widely used HaGRID hand gesture dataset and obtain high quality multimodal data. Quantitative and qualitative analyses demonstrate the state-of-the-art performance of our method on the HaGRID dataset through multiple evaluation metrics. Source code and our enhanced dataset will be released publicly if the paper is accepted.
Stereo Hand-Object Reconstruction for Human-to-Robot Handover
Dec 10, 2024



Jointly estimating hand and object shape ensures the success of the robot grasp in human-to-robot handovers. However, relying on hand-crafted prior knowledge about the geometric structure of the object fails when generalising to unseen objects, and depth sensors fail to detect transparent objects such as drinking glasses. In this work, we propose a stereo-based method for hand-object reconstruction that combines single-view reconstructions probabilistically to form a coherent stereo reconstruction. We learn 3D shape priors from a large synthetic hand-object dataset to ensure that our method is generalisable, and use RGB inputs instead of depth as RGB can better capture transparent objects. We show that our method achieves a lower object Chamfer distance compared to existing RGB based hand-object reconstruction methods on single view and stereo settings. We process the reconstructed hand-object shape with a projection-based outlier removal step and use the output to guide a human-to-robot handover pipeline with wide-baseline stereo RGB cameras. Our hand-object reconstruction enables a robot to successfully receive a diverse range of household objects from the human.
Adaptive Multi-Modal Control of Digital Human Hand Synthesis Using a Region-Aware Cycle Loss
Sep 13, 2024



Diffusion models have shown their remarkable ability to synthesize images, including the generation of humans in specific poses. However, current models face challenges in adequately expressing conditional control for detailed hand pose generation, leading to significant distortion in the hand regions. To tackle this problem, we first curate the How2Sign dataset to provide richer and more accurate hand pose annotations. In addition, we introduce adaptive, multi-modal fusion to integrate characters' physical features expressed in different modalities such as skeleton, depth, and surface normal. Furthermore, we propose a novel Region-Aware Cycle Loss (RACL) that enables the diffusion model training to focus on improving the hand region, resulting in improved quality of generated hand gestures. More specifically, the proposed RACL computes a weighted keypoint distance between the full-body pose keypoints from the generated image and the ground truth, to generate higher-quality hand poses while balancing overall pose accuracy. Moreover, we use two hand region metrics, named hand-PSNR and hand-Distance for hand pose generation evaluations. Our experimental evaluations demonstrate the effectiveness of our proposed approach in improving the quality of digital human pose generation using diffusion models, especially the quality of the hand region. The source code is available at https://github.com/fuqifan/Region-Aware-Cycle-Loss.
Improving Image De-raining Using Reference-Guided Transformers
Aug 01, 2024



Image de-raining is a critical task in computer vision to improve visibility and enhance the robustness of outdoor vision systems. While recent advances in de-raining methods have achieved remarkable performance, the challenge remains to produce high-quality and visually pleasing de-rained results. In this paper, we present a reference-guided de-raining filter, a transformer network that enhances de-raining results using a reference clean image as guidance. We leverage the capabilities of the proposed module to further refine the images de-rained by existing methods. We validate our method on three datasets and show that our module can improve the performance of existing prior-based, CNN-based, and transformer-based approaches.
High-resolution open-vocabulary object 6D pose estimation
Jun 24, 2024



The generalisation to unseen objects in the 6D pose estimation task is very challenging. While Vision-Language Models (VLMs) enable using natural language descriptions to support 6D pose estimation of unseen objects, these solutions underperform compared to model-based methods. In this work we present Horyon, an open-vocabulary VLM-based architecture that addresses relative pose estimation between two scenes of an unseen object, described by a textual prompt only. We use the textual prompt to identify the unseen object in the scenes and then obtain high-resolution multi-scale features. These features are used to extract cross-scene matches for registration. We evaluate our model on a benchmark with a large variety of unseen objects across four datasets, namely REAL275, Toyota-Light, Linemod, and YCB-Video. Our method achieves state-of-the-art performance on all datasets, outperforming by 12.6 in Average Recall the previous best-performing approach.
Diffusion-driven GAN Inversion for Multi-Modal Face Image Generation
May 07, 2024
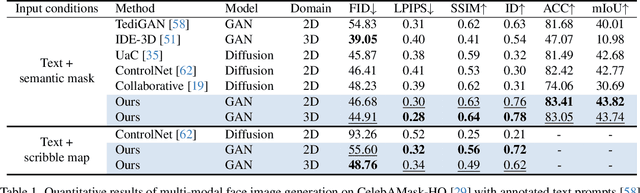
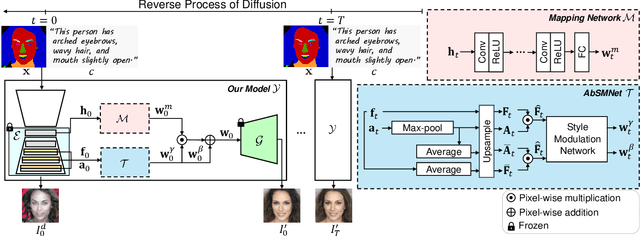
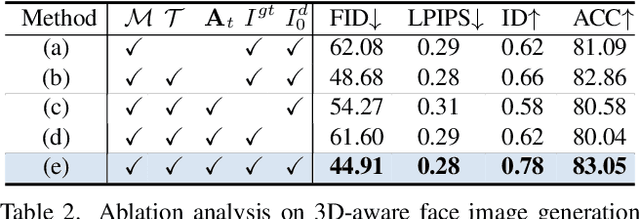
We present a new multi-modal face image generation method that converts a text prompt and a visual input, such as a semantic mask or scribble map, into a photo-realistic face image. To do this, we combine the strengths of Generative Adversarial networks (GANs) and diffusion models (DMs) by employing the multi-modal features in the DM into the latent space of the pre-trained GANs. We present a simple mapping and a style modulation network to link two models and convert meaningful representations in feature maps and attention maps into latent codes. With GAN inversion, the estimated latent codes can be used to generate 2D or 3D-aware facial images. We further present a multi-step training strategy that reflects textual and structural representations into the generated image. Our proposed network produces realistic 2D, multi-view, and stylized face images, which align well with inputs. We validate our method by using pre-trained 2D and 3D GANs, and our results outperform existing methods. Our project page is available at https://github.com/1211sh/Diffusion-driven_GAN-Inversion/.
Sparse multi-view hand-object reconstruction for unseen environments
May 02, 2024



Recent works in hand-object reconstruction mainly focus on the single-view and dense multi-view settings. On the one hand, single-view methods can leverage learned shape priors to generalise to unseen objects but are prone to inaccuracies due to occlusions. On the other hand, dense multi-view methods are very accurate but cannot easily adapt to unseen objects without further data collection. In contrast, sparse multi-view methods can take advantage of the additional views to tackle occlusion, while keeping the computational cost low compared to dense multi-view methods. In this paper, we consider the problem of hand-object reconstruction with unseen objects in the sparse multi-view setting. Given multiple RGB images of the hand and object captured at the same time, our model SVHO combines the predictions from each view into a unified reconstruction without optimisation across views. We train our model on a synthetic hand-object dataset and evaluate directly on a real world recorded hand-object dataset with unseen objects. We show that while reconstruction of unseen hands and objects from RGB is challenging, additional views can help improve the reconstruction quality.