 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Winning Solutions of 2025 Low Power Computer Vision Challenge
Apr 22, 2026The IEEE Low-Power Computer Vision Challenge (LPCVC) aims to promote the development of efficient vision models for edge devices, balancing accuracy with constraints such as latency, memory capacity, and energy use. The 2025 challenge featured three tracks: (1) Image classification under various lighting conditions and styles, (2) Open-Vocabulary Segmentation with Text Prompt, and (3) Monocular Depth Estimation. This paper presents the design of LPCVC 2025, including its competition structure and evaluation framework, which integrates the Qualcomm AI Hub for consistent and reproducible benchmarking. The paper also introduces the top-performing solutions from each track and outlines key trends and observations. The paper concludes with suggestions for future computer vision competitions.
Event Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
AVO: Agentic Variation Operators for Autonomous Evolutionary Search
Mar 25, 2026Agentic Variation Operators (AVO) are a new family of evolutionary variation operators that replace the fixed mutation, crossover, and hand-designed heuristics of classical evolutionary search with autonomous coding agents. Rather than confining a language model to candidate generation within a prescribed pipeline, AVO instantiates variation as a self-directed agent loop that can consult the current lineage, a domain-specific knowledge base, and execution feedback to propose, repair, critique, and verify implementation edits. We evaluate AVO on attention, among the most aggressively optimized kernel targets in AI, on NVIDIA Blackwell (B200) GPUs. Over 7 days of continuous autonomous evolution on multi-head attention, AVO discovers kernels that outperform cuDNN by up to 3.5% and FlashAttention-4 by up to 10.5% across the evaluated configurations. The discovered optimizations transfer readily to grouped-query attention, requiring only 30 minutes of additional autonomous adaptation and yielding gains of up to 7.0% over cuDNN and 9.3% over FlashAttention-4. Together, these results show that agentic variation operators move beyond prior LLM-in-the-loop evolutionary pipelines by elevating the agent from candidate generator to variation operator, and can discover performance-critical micro-architectural optimizations that produce kernels surpassing state-of-the-art expert-engineered attention implementations on today's most advanced GPU hardware.
SOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
Axe: A Simple Unified Layout Abstraction for Machine Learning Compilers
Jan 27, 2026Scaling modern deep learning workloads demands coordinated placement of data and compute across device meshes, memory hierarchies, and heterogeneous accelerators. We present Axe Layout, a hardware-aware abstraction that maps logical tensor coordinates to a multi-axis physical space via named axes. Axe unifies tiling, sharding, replication, and offsets across inter-device distribution and on-device layouts, enabling collective primitives to be expressed consistently from device meshes to threads. Building on Axe, we design a multi-granularity, distribution-aware DSL and compiler that composes thread-local control with collective operators in a single kernel. Experiments show that our unified approach can bring performance close to hand-tuned kernels on across latest GPU devices and multi-device environments and accelerator backends.
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems
Jan 01, 2026Recent advances show that large language models (LLMs) can act as autonomous agents capable of generating GPU kernels, but integrating these AI-generated kernels into real-world inference systems remains challenging. FlashInfer-Bench addresses this gap by establishing a standardized, closed-loop framework that connects kernel generation, benchmarking, and deployment. At its core, FlashInfer Trace provides a unified schema describing kernel definitions, workloads, implementations, and evaluations, enabling consistent communication between agents and systems. Built on real serving traces, FlashInfer-Bench includes a curated dataset, a robust correctness- and performance-aware benchmarking framework, a public leaderboard to track LLM agents' GPU programming capabilities, and a dynamic substitution mechanism (apply()) that seamlessly injects the best-performing kernels into production LLM engines such as SGLang and vLLM. Using FlashInfer-Bench, we further evaluate the performance and limitations of LLM agents, compare the trade-offs among different GPU programming languages, and provide insights for future agent design. FlashInfer-Bench thus establishes a practical, reproducible pathway for continuously improving AI-generated kernels and deploying them into large-scale LLM inference.
Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs
Dec 22, 2025We introduce Mirage Persistent Kernel (MPK), the first compiler and runtime system that automatically transforms multi-GPU model inference into a single high-performance megakernel. MPK introduces an SM-level graph representation that captures data dependencies at the granularity of individual streaming multiprocessors (SMs), enabling cross-operator software pipelining, fine-grained kernel overlap, and other previously infeasible GPU optimizations. The MPK compiler lowers tensor programs into highly optimized SM-level task graphs and generates optimized CUDA implementations for all tasks, while the MPK in-kernel parallel runtime executes these tasks within a single mega-kernel using decentralized scheduling across SMs. Together, these components provide end-to-end kernel fusion with minimal developer effort, while preserving the flexibility of existing programming models. Our evaluation shows that MPK significantly outperforms existing kernel-per-operator LLM serving systems by reducing end-to-end inference latency by up to 1.7x, pushing LLM inference performance close to hardware limits. MPK is publicly available at https://github.com/mirage-project/mirage.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025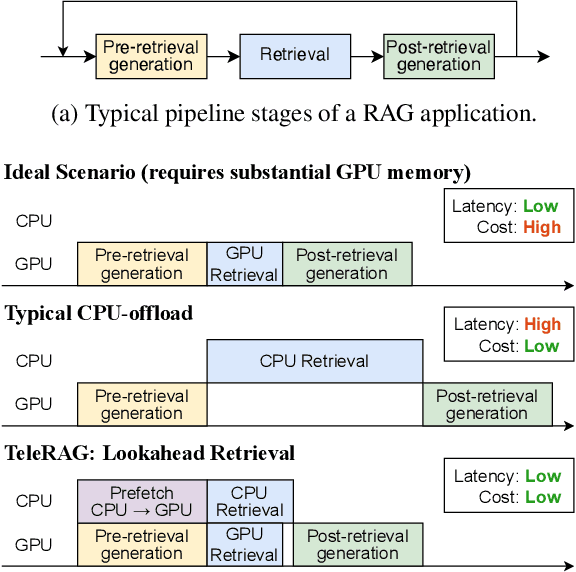



Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Jan 02, 2025



Transformers, driven by attention mechanisms, form the foundation of large language models (LLMs). As these models scale up, efficient GPU attention kernels become essential for high-throughput and low-latency inference. Diverse LLM applications demand flexible and high-performance attention solutions. We present FlashInfer: a customizable and efficient attention engine for LLM serving. FlashInfer tackles KV-cache storage heterogeneity using block-sparse format and composable formats to optimize memory access and reduce redundancy. It also offers a customizable attention template, enabling adaptation to various settings through Just-In-Time (JIT) compilation. Additionally, FlashInfer's load-balanced scheduling algorithm adjusts to dynamism of user requests while maintaining compatibility with CUDAGraph which requires static configuration. FlashInfer have been integrated into leading LLM serving frameworks like SGLang, vLLM and MLC-Engine. Comprehensive kernel-level and end-to-end evaluations demonstrate FlashInfer's ability to significantly boost kernel performance across diverse inference scenarios: compared to state-of-the-art LLM serving solutions, FlashInfer achieve 29-69% inter-token-latency reduction compared to compiler backends for LLM serving benchmark, 28-30% latency reduction for long-context inference, and 13-17% speedup for LLM serving with parallel generation.
MagicPIG: LSH Sampling for Efficient LLM Generation
Oct 21, 2024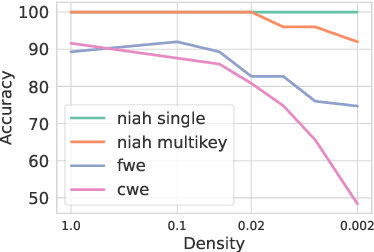
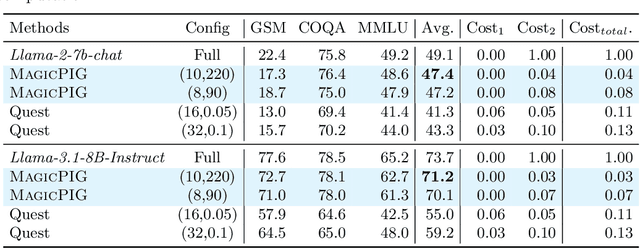
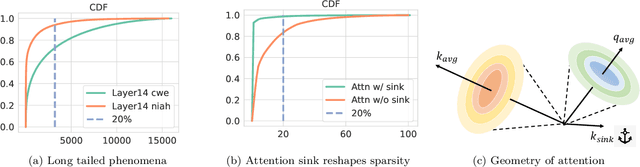
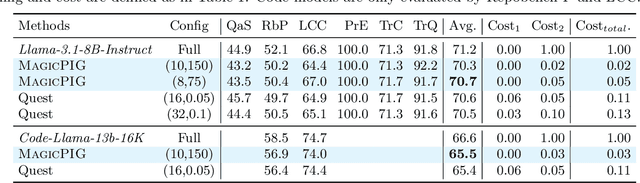
Large language models (LLMs) with long context windows have gained significant attention. However, the KV cache, stored to avoid re-computation, becomes a bottleneck. Various dynamic sparse or TopK-based attention approximation methods have been proposed to leverage the common insight that attention is sparse. In this paper, we first show that TopK attention itself suffers from quality degradation in certain downstream tasks because attention is not always as sparse as expected. Rather than selecting the keys and values with the highest attention scores, sampling with theoretical guarantees can provide a better estimation for attention output. To make the sampling-based approximation practical in LLM generation, we propose MagicPIG, a heterogeneous system based on Locality Sensitive Hashing (LSH). MagicPIG significantly reduces the workload of attention computation while preserving high accuracy for diverse tasks. MagicPIG stores the LSH hash tables and runs the attention computation on the CPU, which allows it to serve longer contexts and larger batch sizes with high approximation accuracy. MagicPIG can improve decoding throughput by $1.9\sim3.9\times$ across various GPU hardware and achieve 110ms decoding latency on a single RTX 4090 for Llama-3.1-8B-Instruct model with a context of 96k tokens. The code is available at \url{https://github.com/Infini-AI-Lab/MagicPIG}.