 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM*: A Modular, Extensible, Serving System for Multimodal Models
Jun 10, 2026We are entering a new era of composite model architectures that integrate diverse components such as vision encoders, language backbones, diffusion and flow heads, audio codecs, action generators, and world-model predictors. Such architectures underpin a broad class of multimodal models, including unified multimodal models, omni models, speech-language models, vision-language-action policies, and world models. However, existing model serving frameworks were built on narrow assumptions about model structure, making them ill-suited to accommodate this new architectural diversity. Here we present M*, a universal serving system for efficient serving of composite AI models. M* represents models as dataflow graphs, processing requests spanning diverse modalities and tasks as traversals over these graphs. The core insight is a modular abstraction that supports arbitrary composition of model components, flexible placement onto a physical cluster, and model-agnostic optimizations within a distributed runtime. We call this abstraction the Walk Graph and show how it can concisely capture composite models from a broad range of families. We instantiate M* on representative models and find that it achieves, on average, 20% lower end-to-end latency than vLLM-Omni for text-to-image workloads on BAGEL, while delivering up to 2.9x lower real-time factor and 2.7x higher throughput for text-to-speech workloads on Qwen3-Omni. M* also outperforms the V-JEPA 2-AC rollout baseline for robotic planning by up to 12.5x. Thus, our work paves the road towards more efficient serving of complex models with minimal developer effort.
Ekka: Automated Diagnosis of Silent Errors in LLM Inference
Jun 03, 2026LLM serving frameworks are quickly evolving with a complex software stack and a vast number of optimizations. The rapid development process can introduce silent errors where output quality silently degrades without any explicit error signals. Diagnosing silent errors is notoriously difficult due to the substantial semantic gap between the high-level symptoms and the low-level root causes. We observe that diagnosis of silent errors can be effectively framed as a differential debugging problem by leveraging the existence of semantically correct reference implementations. We propose Ekka, an automated diagnosis system that identifies root causes by systematically aligning and comparing intermediate execution states between a target and a reference framework. We constructed a benchmark of real-world silent errors from popular serving frameworks, where Ekka shows 80% pass@1 diagnosis accuracy and 88% pass@5 diagnosis accuracy, outperforming state-of-the-art systems. Ekka also diagnoses 4 new silent errors from serving frameworks, all of which have been confirmed by the developers.
MURMUR: An Efficient Inference System for Long-Form ASR
May 31, 2026Long-form automatic speech recognition (ASR) requires both high accuracy and low latency, but existing systems force a trade-off between the two. Chunk-based pipelines process audio in parallel windows for low latency, but lose cross-chunk context and need brittle heuristics to align speakers and timestamps at boundaries. Long-context ASR models resolve everything in a single pass for better accuracy, but are an order of magnitude slower. We propose Murmur, an inference system that overcomes this trade-off by operating at two levels. At the inter-chunk level, we revisit the chunk-based pipeline for modern long-context ASR, treating chunk size as a tunable hyperparameter, and show that intermediate chunk sizes strike a good balance of accuracy and latency. At the intra-chunk level, we exploit attention sparsity through a sliding window KV cache eviction policy applied to both output and speech tokens. On AMI-IHM, Murmur matches single-pass accuracy while reducing latency by 4.2x, with further gains from token eviction at less than 1% relative tcpWER degradation. The code of Murmur is available at https://github.com/uw-syfi/Murmur.
VibeServe: Can AI Agents Build Bespoke LLM Serving Systems?
May 07, 2026For years, we have built LLM serving systems like any other critical infrastructure: a single general-purpose stack, hand-tuned over many engineer-years, meant to support every model and workload. In this paper, we take the opposite bet: a multi-agent loop that automatically synthesizes bespoke serving systems for different usage scenarios. We propose VibeServe, the first agentic loop that generates entire LLM serving stacks end-to-end. VibeServe uses an outer loop to plan and track the search over system designs, and an inner loop to implement candidates, check correctness, and measure performance on the target benchmark. In the standard deployment setting, where existing stacks are highly optimized, VibeServe remains competitive with vLLM, showing that generation-time specialization need not come at the cost of performance. More interestingly, in non-standard scenarios, VibeServe outperforms existing systems by exploiting opportunities that generic systems miss in six scenarios involving non-standard model architectures, workload knowledge, and hardware-specific optimizations. Together, these results suggest a different point in the design space for infrastructure software: generation-time specialization rather than runtime generality. Code is available at https://github.com/uw-syfi/vibe-serve.
VoxServe: Streaming-Centric Serving System for Speech Language Models
Jan 30, 2026Deploying modern Speech Language Models (SpeechLMs) in streaming settings requires systems that provide low latency, high throughput, and strong guarantees of streamability. Existing systems fall short of supporting diverse models flexibly and efficiently. We present VoxServe, a unified serving system for SpeechLMs that optimizes streaming performance. VoxServe introduces a model-execution abstraction that decouples model architecture from system-level optimizations, thereby enabling support for diverse SpeechLM architectures within a single framework. Building on this abstraction, VoxServe implements streaming-aware scheduling and an asynchronous inference pipeline to improve end-to-end efficiency. Evaluations across multiple modern SpeechLMs show that VoxServe achieves 10-20x higher throughput than existing implementations at comparable latency while maintaining high streaming viability. The code of VoxServe is available at https://github.com/vox-serve/vox-serve.
Magneton: Optimizing Energy Efficiency of ML Systems via Differential Energy Debugging
Dec 09, 2025The training and deployment of machine learning (ML) models have become extremely energy-intensive. While existing optimization efforts focus primarily on hardware energy efficiency, a significant but overlooked source of inefficiency is software energy waste caused by poor software design. This often includes redundant or poorly designed operations that consume more energy without improving performance. These inefficiencies arise in widely used ML frameworks and applications, yet developers often lack the visibility and tools to detect and diagnose them. We propose differential energy debugging, a novel approach that leverages the observation that competing ML systems often implement similar functionality with vastly different energy consumption. Building on this insight, we design and implement Magneton, an energy profiler that compares energy consumption between similar ML systems at the operator level and automatically pinpoints code regions and configuration choices responsible for excessive energy use. Applied to 9 popular ML systems spanning LLM inference, general ML frameworks, and image generation, Magneton detects and diagnoses 16 known cases of software energy inefficiency and further discovers 8 previously unknown cases, 7 of which have been confirmed by developers.
Fake Runs, Real Fixes -- Analyzing xPU Performance Through Simulation
Mar 18, 2025



As models become larger, ML accelerators are a scarce resource whose performance must be continually optimized to improve efficiency. Existing performance analysis tools are coarse grained, and fail to capture model performance at the machine-code level. In addition, these tools often do not provide specific recommendations for optimizations. We present xPU-Shark, a fine-grained methodology for analyzing ML models at the machine-code level that provides actionable optimization suggestions. Our core insight is to use a hardware-level simulator, an artifact of the hardware design process that we can re-purpose for performance analysis. xPU-Shark captures traces from production deployments running on accelerators and replays them in a modified microarchitecture simulator to gain low-level insights into the model's performance. We implement xPU-Shark for our in-house accelerator and used it to analyze the performance of several of our production LLMs, revealing several previously-unknown microarchitecture inefficiencies. Leveraging these insights, we optimize a common communication collective by up to 15% and reduce token generation latency by up to 4.1%.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025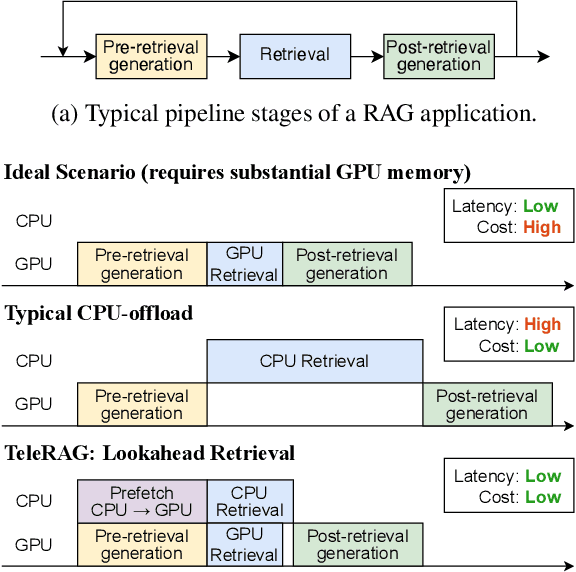



Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
LiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation
Feb 27, 2025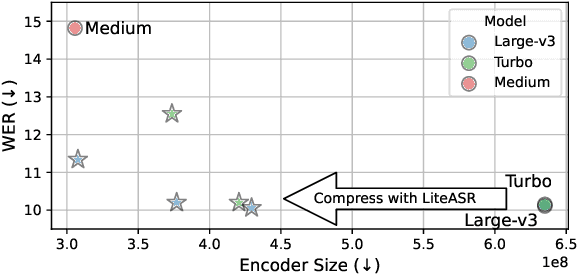
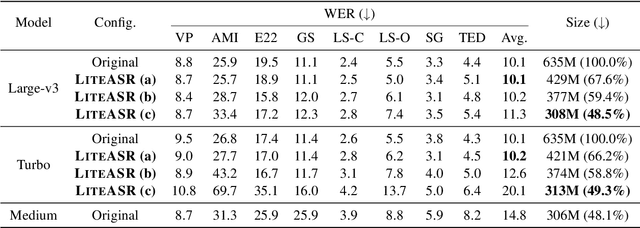
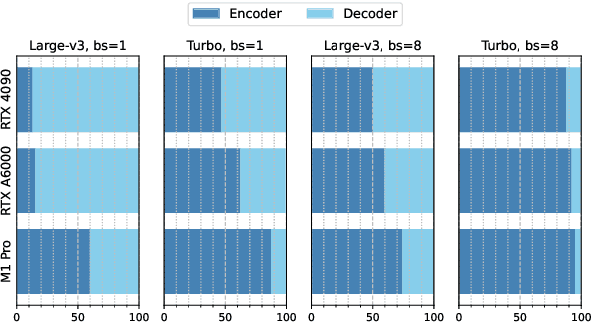
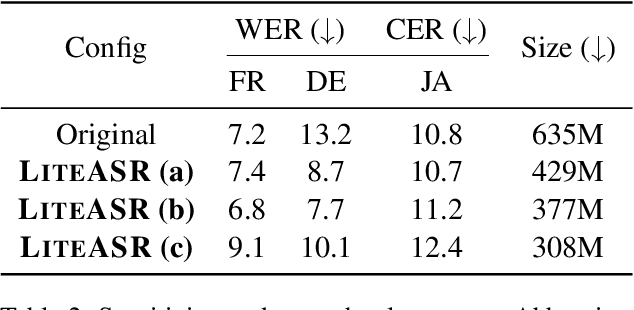
Modern automatic speech recognition (ASR) models, such as OpenAI's Whisper, rely on deep encoder-decoder architectures, and their encoders are a critical bottleneck for efficient deployment due to high computational intensity. We introduce LiteASR, a low-rank compression scheme for ASR encoders that significantly reduces inference costs while maintaining transcription accuracy. Our approach leverages the strong low-rank properties observed in intermediate activations: by applying principal component analysis (PCA) with a small calibration dataset, we approximate linear transformations with a chain of low-rank matrix multiplications, and further optimize self-attention to work in the reduced dimension. Evaluation results show that our method can compress Whisper large-v3's encoder size by over 50%, matching Whisper medium's size with better transcription accuracy, thereby establishing a new Pareto-optimal frontier of efficiency and performance. The code of LiteASR is available at https://github.com/efeslab/LiteASR.
Tactic: Adaptive Sparse Attention with Clustering and Distribution Fitting for Long-Context LLMs
Feb 17, 2025Long-context models are essential for many applications but face inefficiencies in loading large KV caches during decoding. Prior methods enforce fixed token budgets for sparse attention, assuming a set number of tokens can approximate full attention. However, these methods overlook variations in the importance of attention across heads, layers, and contexts. To address these limitations, we propose Tactic, a sparsity-adaptive and calibration-free sparse attention mechanism that dynamically selects tokens based on their cumulative attention scores rather than a fixed token budget. By setting a target fraction of total attention scores, Tactic ensures that token selection naturally adapts to variations in attention sparsity. To efficiently approximate this selection, Tactic leverages clustering-based sorting and distribution fitting, allowing it to accurately estimate token importance with minimal computational overhead. We show that Tactic outperforms existing sparse attention algorithms, achieving superior accuracy and up to 7.29x decode attention speedup. This improvement translates to an overall 1.58x end-to-end inference speedup, making Tactic a practical and effective solution for long-context LLM inference in accuracy-sensitive applications.