 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Parsing of Engineering Drawings for Structured Information Extraction Using a Fine-tuned Document Understanding Transformer
May 02, 2025

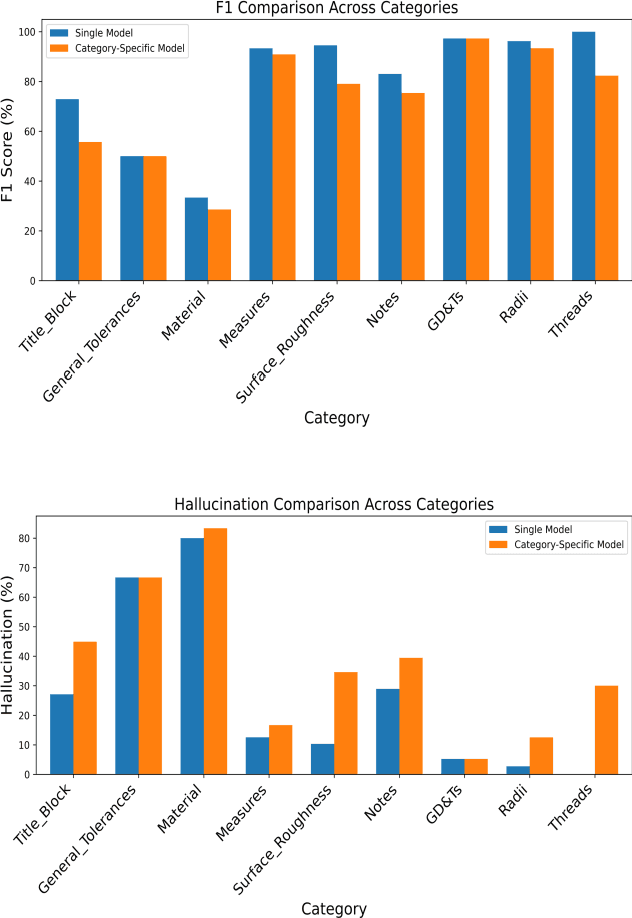
Accurate extraction of key information from 2D engineering drawings is crucial for high-precision manufacturing. Manual extraction is time-consuming and error-prone, while traditional Optical Character Recognition (OCR) techniques often struggle with complex layouts and overlapping symbols, resulting in unstructured outputs. To address these challenges, this paper proposes a novel hybrid deep learning framework for structured information extraction by integrating an oriented bounding box (OBB) detection model with a transformer-based document parsing model (Donut). An in-house annotated dataset is used to train YOLOv11 for detecting nine key categories: Geometric Dimensioning and Tolerancing (GD&T), General Tolerances, Measures, Materials, Notes, Radii, Surface Roughness, Threads, and Title Blocks. Detected OBBs are cropped into images and labeled to fine-tune Donut for structured JSON output. Fine-tuning strategies include a single model trained across all categories and category-specific models. Results show that the single model consistently outperforms category-specific ones across all evaluation metrics, achieving higher precision (94.77% for GD&T), recall (100% for most), and F1 score (97.3%), while reducing hallucination (5.23%). The proposed framework improves accuracy, reduces manual effort, and supports scalable deployment in precision-driven industries.
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Jan 02, 2025



Transformers, driven by attention mechanisms, form the foundation of large language models (LLMs). As these models scale up, efficient GPU attention kernels become essential for high-throughput and low-latency inference. Diverse LLM applications demand flexible and high-performance attention solutions. We present FlashInfer: a customizable and efficient attention engine for LLM serving. FlashInfer tackles KV-cache storage heterogeneity using block-sparse format and composable formats to optimize memory access and reduce redundancy. It also offers a customizable attention template, enabling adaptation to various settings through Just-In-Time (JIT) compilation. Additionally, FlashInfer's load-balanced scheduling algorithm adjusts to dynamism of user requests while maintaining compatibility with CUDAGraph which requires static configuration. FlashInfer have been integrated into leading LLM serving frameworks like SGLang, vLLM and MLC-Engine. Comprehensive kernel-level and end-to-end evaluations demonstrate FlashInfer's ability to significantly boost kernel performance across diverse inference scenarios: compared to state-of-the-art LLM serving solutions, FlashInfer achieve 29-69% inter-token-latency reduction compared to compiler backends for LLM serving benchmark, 28-30% latency reduction for long-context inference, and 13-17% speedup for LLM serving with parallel generation.
Fine-Tuning Vision-Language Model for Automated Engineering Drawing Information Extraction
Nov 06, 2024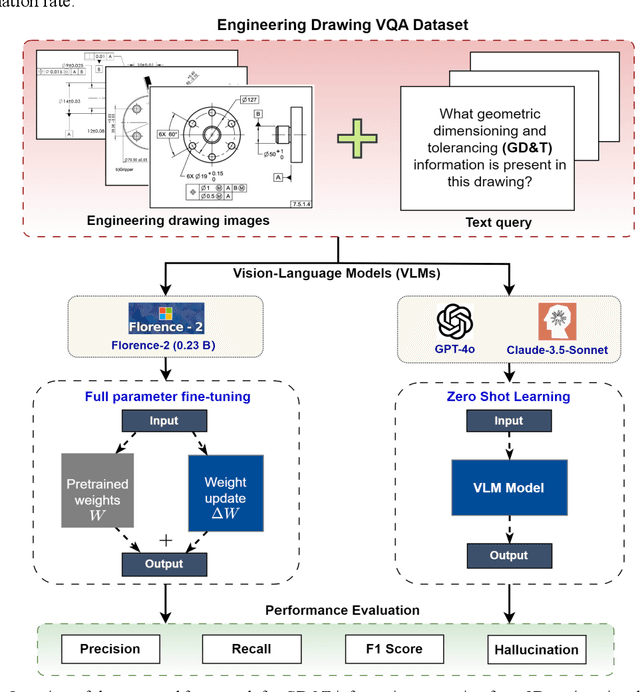
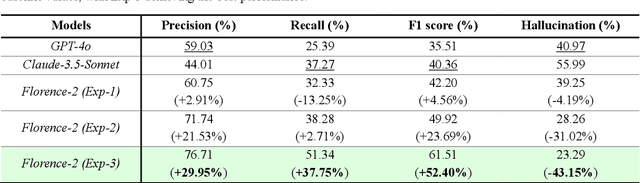
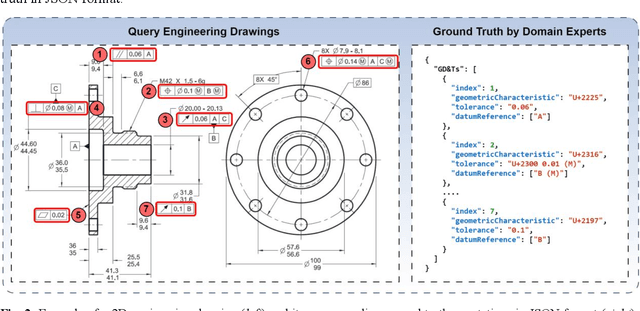
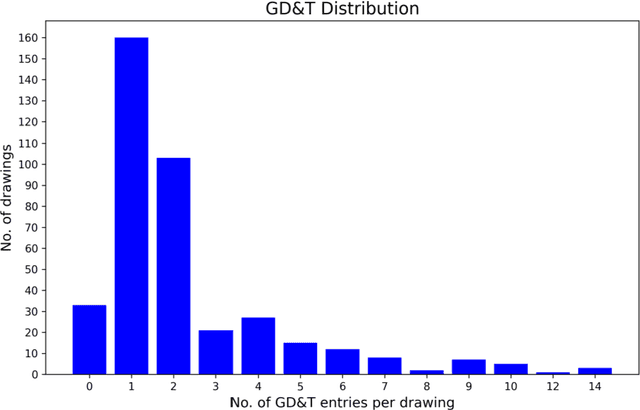
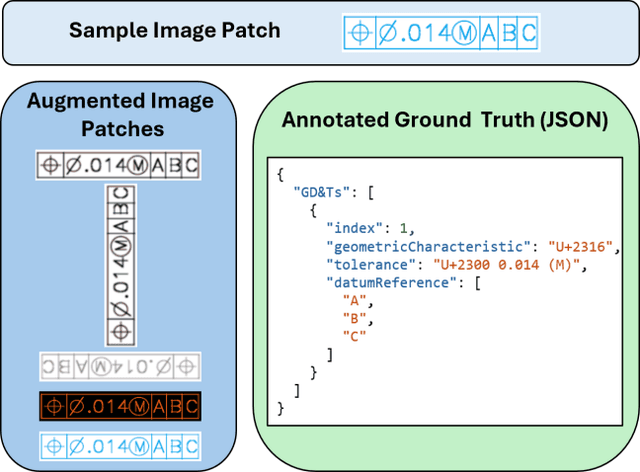
Geometric Dimensioning and Tolerancing (GD&T) plays a critical role in manufacturing by defining acceptable variations in part features to ensure component quality and functionality. However, extracting GD&T information from 2D engineering drawings is a time-consuming and labor-intensive task, often relying on manual efforts or semi-automated tools. To address these challenges, this study proposes an automated and computationally efficient GD&T extraction method by fine-tuning Florence-2, an open-source vision-language model (VLM). The model is trained on a dataset of 400 drawings with ground truth annotations provided by domain experts. For comparison, two state-of-the-art closed-source VLMs, GPT-4o and Claude-3.5-Sonnet, are evaluated on the same dataset. All models are assessed using precision, recall, F1-score, and hallucination metrics. Due to the computational cost and impracticality of fine-tuning large closed-source VLMs for domain-specific tasks, GPT-4o and Claude-3.5-Sonnet are evaluated in a zero-shot setting. In contrast, Florence-2, a smaller model with 0.23 billion parameters, is optimized through full-parameter fine-tuning across three distinct experiments, each utilizing datasets augmented to different levels. The results show that Florence-2 achieves a 29.95% increase in precision, a 37.75% increase in recall, a 52.40% improvement in F1-score, and a 43.15% reduction in hallucination rate compared to the best-performing closed-source model. These findings highlight the effectiveness of fine-tuning smaller, open-source VLMs like Florence-2, offering a practical and efficient solution for automated GD&T extraction to support downstream manufacturing tasks.
Automatic Feature Recognition and Dimensional Attributes Extraction From CAD Models for Hybrid Additive-Subtractive Manufacturing
Aug 14, 2024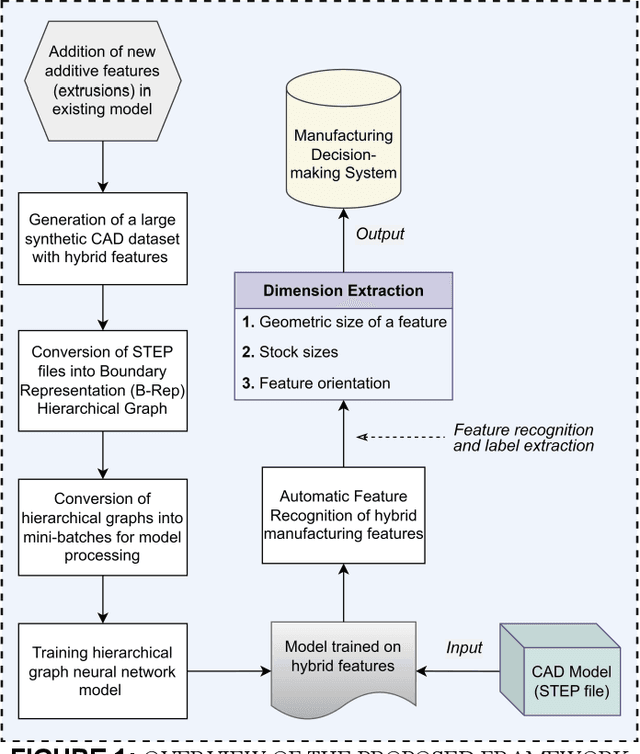
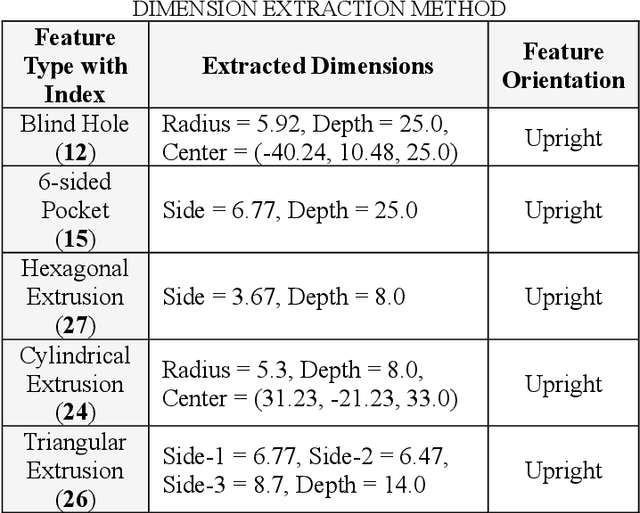

The integration of Computer-Aided Design (CAD), Computer-Aided Process Planning (CAPP), and Computer-Aided Manufacturing (CAM) plays a crucial role in modern manufacturing, facilitating seamless transitions from digital designs to physical products. However, a significant challenge within this integration is the Automatic Feature Recognition (AFR) of CAD models, especially in the context of hybrid manufacturing that combines subtractive and additive manufacturing processes. Traditional AFR methods, focused mainly on the identification of subtractive (machined) features including holes, fillets, chamfers, pockets, and slots, fail to recognize features pertinent to additive manufacturing. Furthermore, the traditional methods fall short in accurately extracting geometric dimensions and orientations, which are also key factors for effective manufacturing process planning. This paper presents a novel approach for creating a synthetic CAD dataset that encompasses features relevant to both additive and subtractive machining through Python Open Cascade. The Hierarchical Graph Convolutional Neural Network (HGCNN) model is implemented to accurately identify the composite additive-subtractive features within the synthetic CAD dataset. The key novelty and contribution of the proposed methodology lie in its ability to recognize a wide range of manufacturing features, and precisely extracting their dimensions, orientations, and stock sizes. The proposed model demonstrates remarkable feature recognition accuracy exceeding 97% and a dimension extraction accuracy of 100% for identified features. Therefore, the proposed methodology enhances the integration of CAD, CAPP, and CAM within hybrid manufacturing by providing precise feature recognition and dimension extraction. It facilitates improved manufacturing process planning, by enabling more informed decision-making.
Audio-visual cross-modality knowledge transfer for machine learning-based in-situ monitoring in laser additive manufacturing
Aug 09, 2024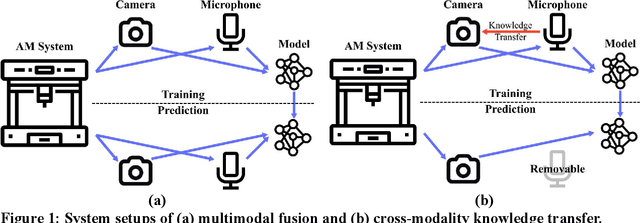
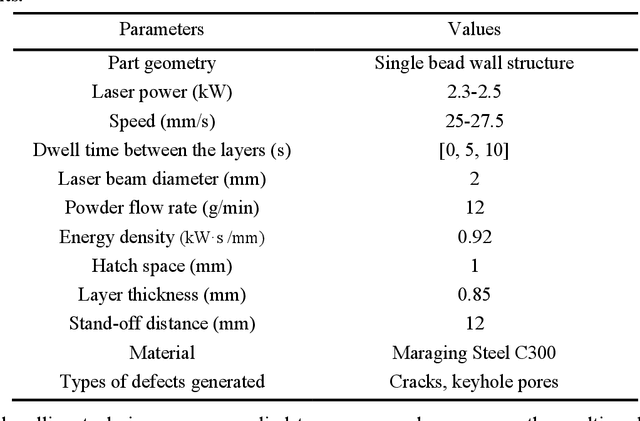
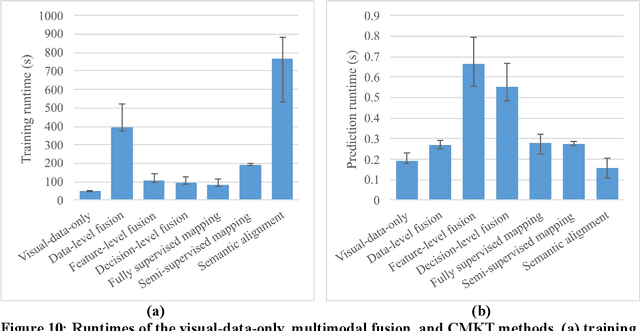
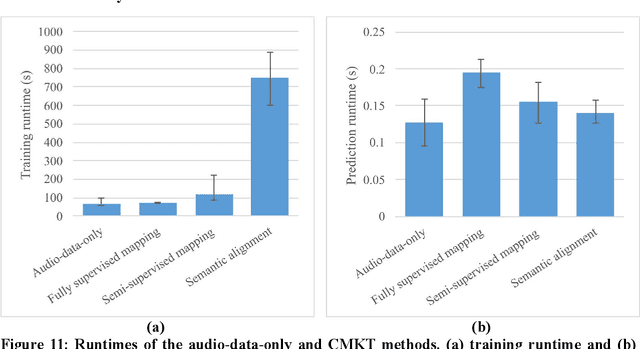
Various machine learning (ML)-based in-situ monitoring systems have been developed to detect laser additive manufacturing (LAM) process anomalies and defects. Multimodal fusion can improve in-situ monitoring performance by acquiring and integrating data from multiple modalities, including visual and audio data. However, multimodal fusion employs multiple sensors of different types, which leads to higher hardware, computational, and operational costs. This paper proposes a cross-modality knowledge transfer (CMKT) methodology that transfers knowledge from a source to a target modality for LAM in-situ monitoring. CMKT enhances the usefulness of the features extracted from the target modality during the training phase and removes the sensors of the source modality during the prediction phase. This paper proposes three CMKT methods: semantic alignment, fully supervised mapping, and semi-supervised mapping. Semantic alignment establishes a shared encoded space between modalities to facilitate knowledge transfer. It utilizes a semantic alignment loss to align the distributions of the same classes (e.g., visual defective and audio defective classes) and a separation loss to separate the distributions of different classes (e.g., visual defective and audio defect-free classes). The two mapping methods transfer knowledge by deriving the features of one modality from the other modality using fully supervised and semi-supervised learning. The proposed CMKT methods were implemented and compared with multimodal audio-visual fusion in an LAM in-situ anomaly detection case study. The semantic alignment method achieves a 98.4% accuracy while removing the audio modality during the prediction phase, which is comparable to the accuracy of multimodal fusion (98.2%).
In-situ process monitoring and adaptive quality enhancement in laser additive manufacturing: a critical review
Apr 21, 2024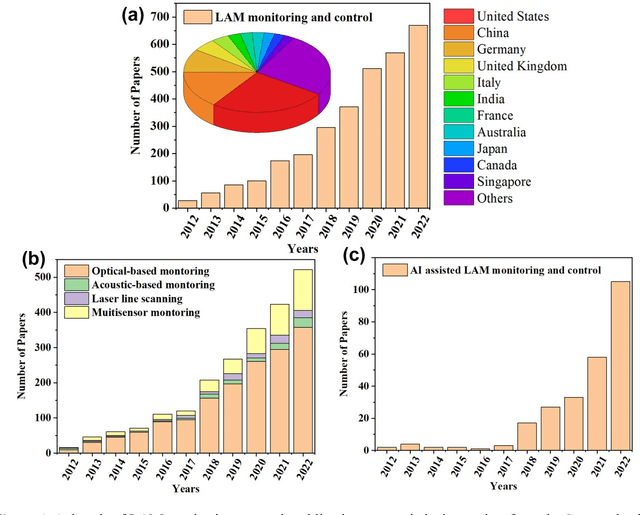
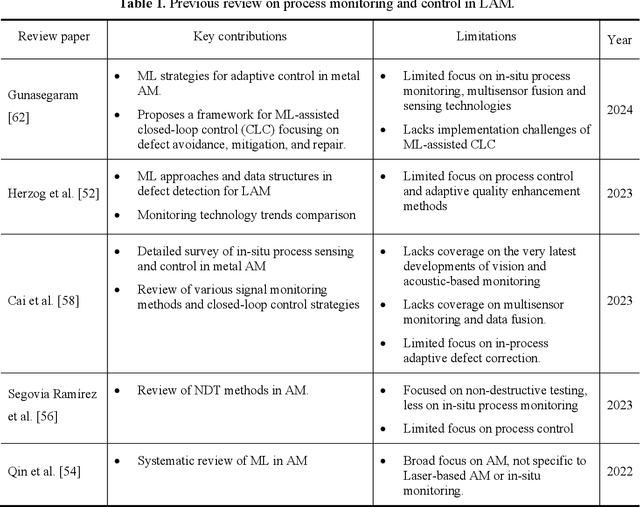
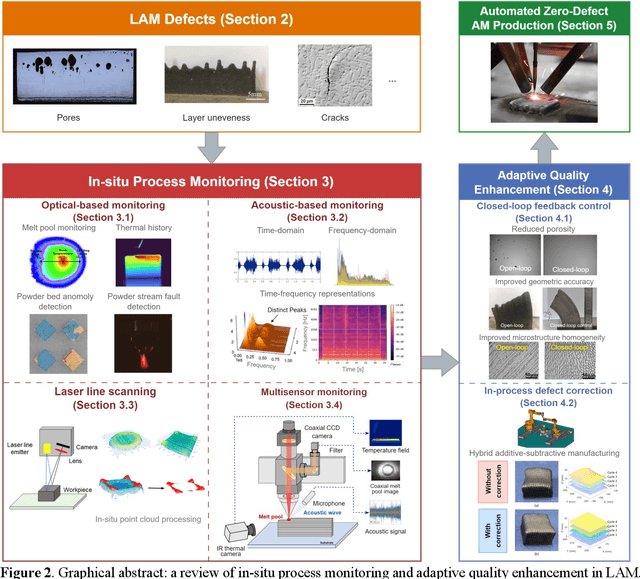
Laser Additive Manufacturing (LAM) presents unparalleled opportunities for fabricating complex, high-performance structures and components with unique material properties. Despite these advancements, achieving consistent part quality and process repeatability remains challenging. This paper provides a comprehensive review of various state-of-the-art in-situ process monitoring techniques, including optical-based monitoring, acoustic-based sensing, laser line scanning, and operando X-ray monitoring. These techniques are evaluated for their capabilities and limitations in detecting defects within Laser Powder Bed Fusion (LPBF) and Laser Directed Energy Deposition (LDED) processes. Furthermore, the review discusses emerging multisensor monitoring and machine learning (ML)-assisted defect detection methods, benchmarking ML models tailored for in-situ defect detection. The paper also discusses in-situ adaptive defect remediation strategies that advance LAM towards zero-defect autonomous operations, focusing on real-time closed-loop feedback control and defect correction methods. Research gaps such as the need for standardization, improved reliability and sensitivity, and decision-making strategies beyond early stopping are highlighted. Future directions are proposed, with an emphasis on multimodal sensor fusion for multiscale defect prediction and fault diagnosis, ultimately enabling self-adaptation in LAM processes. This paper aims to equip researchers and industry professionals with a holistic understanding of the current capabilities, limitations, and future directions in in-situ process monitoring and adaptive quality enhancement in LAM.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
Nov 07, 2023



The growing demand for Large Language Models (LLMs) in applications such as content generation, intelligent chatbots, and sentiment analysis poses considerable challenges for LLM service providers. To efficiently use GPU resources and boost throughput, batching multiple requests has emerged as a popular paradigm; to further speed up batching, LLM quantization techniques reduce memory consumption and increase computing capacity. However, prevalent quantization schemes (e.g., 8-bit weight-activation quantization) cannot fully leverage the capabilities of modern GPUs, such as 4-bit integer operators, resulting in sub-optimal performance. To maximize LLMs' serving throughput, we introduce Atom, a low-bit quantization method that achieves high throughput improvements with negligible accuracy loss. Atom significantly boosts serving throughput by using low-bit operators and considerably reduces memory consumption via low-bit quantization. It attains high accuracy by applying a novel mixed-precision and fine-grained quantization process. We evaluate Atom on 4-bit weight-activation quantization setups in the serving context. Atom improves end-to-end throughput by up to $7.73\times$ compared to the FP16 and by $2.53\times$ compared to INT8 quantization, while maintaining the same latency target.
Punica: Multi-Tenant LoRA Serving
Oct 28, 2023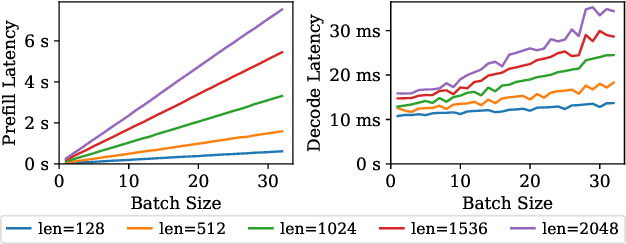
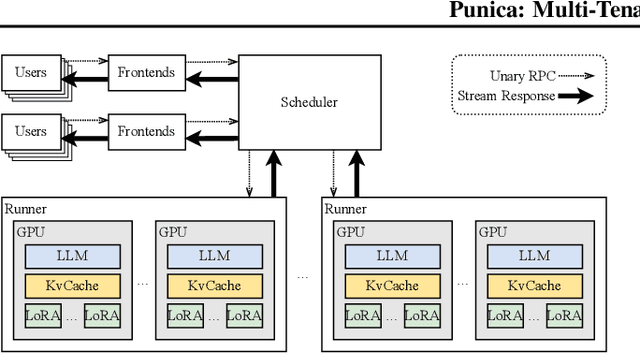
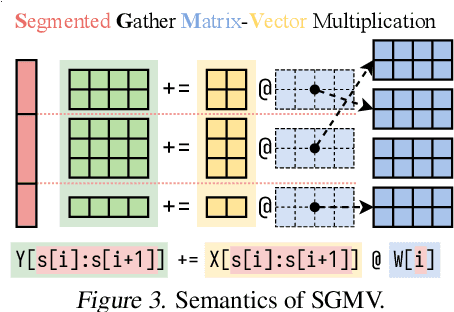
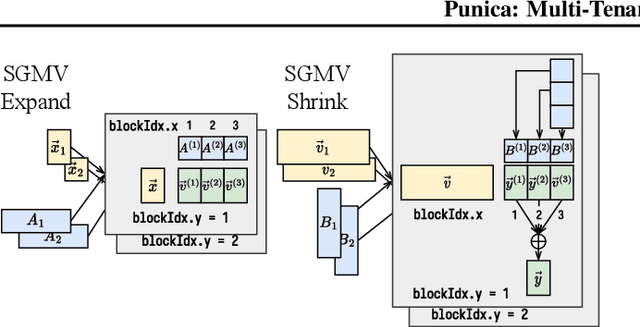
Low-rank adaptation (LoRA) has become an important and popular method to adapt pre-trained models to specific domains. We present Punica, a system to serve multiple LoRA models in a shared GPU cluster. Punica contains a new CUDA kernel design that allows batching of GPU operations for different LoRA models. This allows a GPU to hold only a single copy of the underlying pre-trained model when serving multiple, different LoRA models, significantly enhancing GPU efficiency in terms of both memory and computation. Our scheduler consolidates multi-tenant LoRA serving workloads in a shared GPU cluster. With a fixed-sized GPU cluster, our evaluations show that Punica achieves 12x higher throughput in serving multiple LoRA models compared to state-of-the-art LLM serving systems while only adding 2ms latency per token. Punica is open source at https://github.com/punica-ai/punica .
Symphony: Optimized Model Serving using Centralized Orchestration
Aug 14, 2023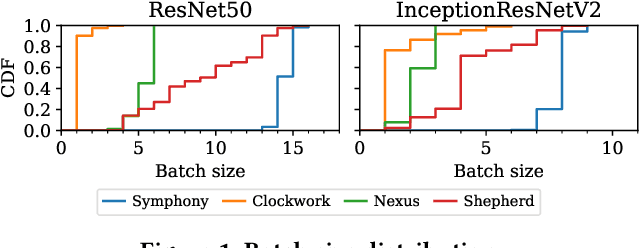
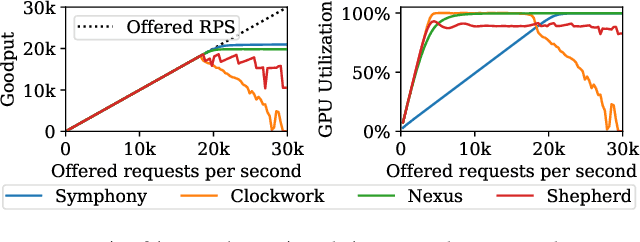
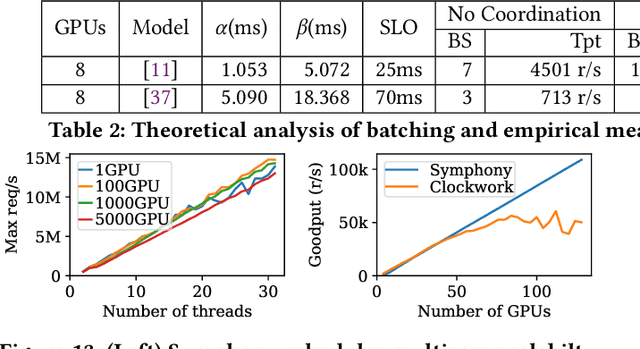
The orchestration of deep neural network (DNN) model inference on GPU clusters presents two significant challenges: achieving high accelerator efficiency given the batching properties of model inference while meeting latency service level objectives (SLOs), and adapting to workload changes both in terms of short-term fluctuations and long-term resource allocation. To address these challenges, we propose Symphony, a centralized scheduling system that can scale to millions of requests per second and coordinate tens of thousands of GPUs. Our system utilizes a non-work-conserving scheduling algorithm capable of achieving high batch efficiency while also enabling robust autoscaling. Additionally, we developed an epoch-scale algorithm that allocates models to sub-clusters based on the compute and memory needs of the models. Through extensive experiments, we demonstrate that Symphony outperforms prior systems by up to 4.7x higher goodput.