 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Quality Evaluation of Cervical Cytopathology Whole Slide Images Based on Content Analysis
May 20, 2025The ThinPrep Cytologic Test (TCT) is the most widely used method for cervical cancer screening, and the sample quality directly impacts the accuracy of the diagnosis. Traditional manual evaluation methods rely on the observation of pathologist under microscopes. These methods exhibit high subjectivity, high cost, long duration, and low reliability. With the development of computer-aided diagnosis (CAD), an automated quality assessment system that performs at the level of a professional pathologist is necessary. To address this need, we propose a fully automated quality assessment method for Cervical Cytopathology Whole Slide Images (WSIs) based on The Bethesda System (TBS) diagnostic standards, artificial intelligence algorithms, and the characteristics of clinical data. The method analysis the context of WSIs to quantify quality evaluation metrics which are focused by TBS such as staining quality, cell counts and cell mass proportion through multiple models including object detection, classification and segmentation. Subsequently, the XGBoost model is used to mine the attention paid by pathologists to different quality evaluation metrics when evaluating samples, thereby obtaining a comprehensive WSI sample score calculation model. Experimental results on 100 WSIs demonstrate that the proposed evaluation method has significant advantages in terms of speed and consistency.
MLKV: Efficiently Scaling up Large Embedding Model Training with Disk-based Key-Value Storage
Apr 02, 2025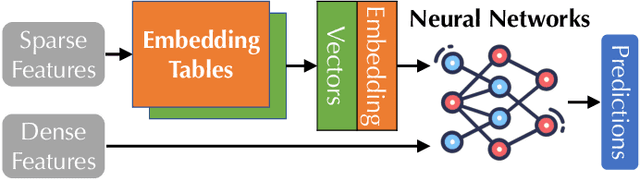
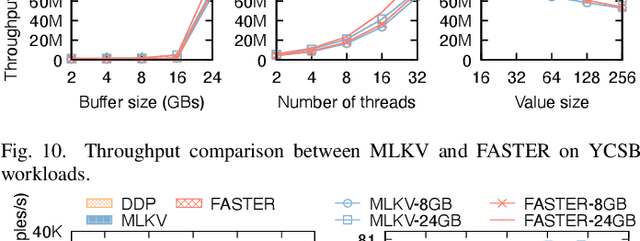
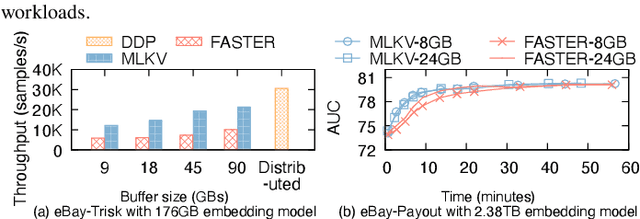

Many modern machine learning (ML) methods rely on embedding models to learn vector representations (embeddings) for a set of entities (embedding tables). As increasingly diverse ML applications utilize embedding models and embedding tables continue to grow in size and number, there has been a surge in the ad-hoc development of specialized frameworks targeted to train large embedding models for specific tasks. Although the scalability issues that arise in different embedding model training tasks are similar, each of these frameworks independently reinvents and customizes storage components for specific tasks, leading to substantial duplicated engineering efforts in both development and deployment. This paper presents MLKV, an efficient, extensible, and reusable data storage framework designed to address the scalability challenges in embedding model training, specifically data stall and staleness. MLKV augments disk-based key-value storage by democratizing optimizations that were previously exclusive to individual specialized frameworks and provides easy-to-use interfaces for embedding model training tasks. Extensive experiments on open-source workloads, as well as applications in eBay's payment transaction risk detection and seller payment risk detection, show that MLKV outperforms offloading strategies built on top of industrial-strength key-value stores by 1.6-12.6x. MLKV is open-source at https://github.com/llm-db/MLKV.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
Contrastive Loss Based Frame-wise Feature disentanglement for Polyphonic Sound Event Detection
Jan 11, 2024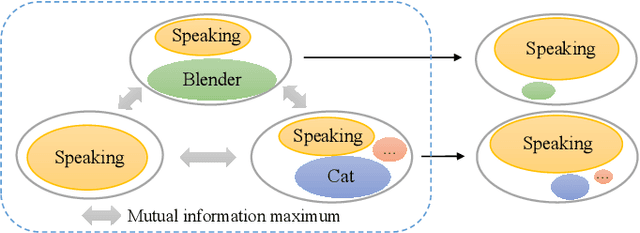
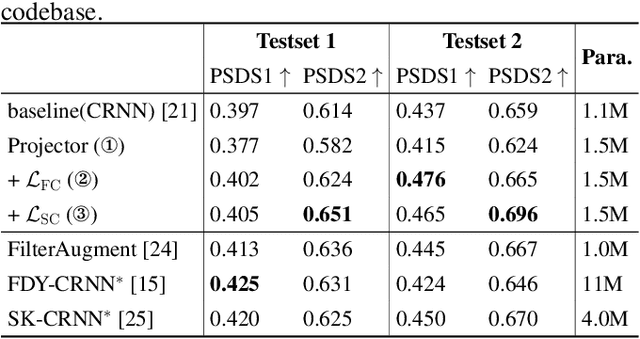
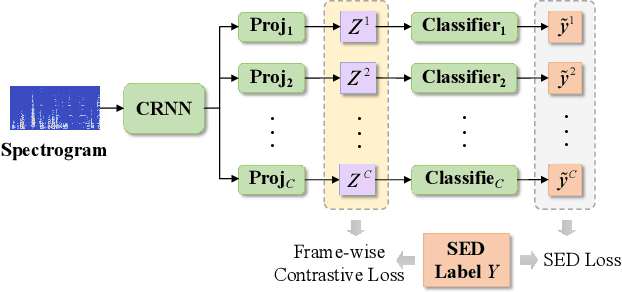
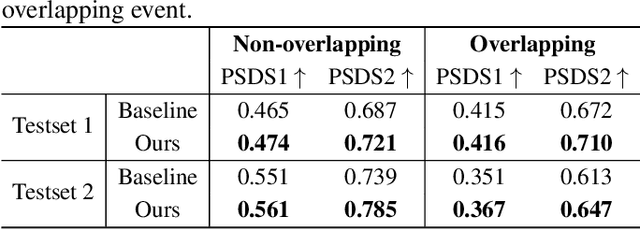
Overlapping sound events are ubiquitous in real-world environments, but existing end-to-end sound event detection (SED) methods still struggle to detect them effectively. A critical reason is that these methods represent overlapping events using shared and entangled frame-wise features, which degrades the feature discrimination. To solve the problem, we propose a disentangled feature learning framework to learn a category-specific representation. Specifically, we employ different projectors to learn the frame-wise features for each category. To ensure that these feature does not contain information of other categories, we maximize the common information between frame-wise features within the same category and propose a frame-wise contrastive loss. In addition, considering that the labeled data used by the proposed method is limited, we propose a semi-supervised frame-wise contrastive loss that can leverage large amounts of unlabeled data to achieve feature disentanglement. The experimental results demonstrate the effectiveness of our method.
Auto-FP: An Experimental Study of Automated Feature Preprocessing for Tabular Data
Oct 04, 2023

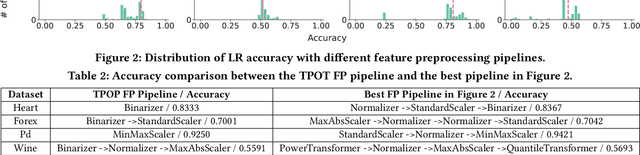

Classical machine learning models, such as linear models and tree-based models, are widely used in industry. These models are sensitive to data distribution, thus feature preprocessing, which transforms features from one distribution to another, is a crucial step to ensure good model quality. Manually constructing a feature preprocessing pipeline is challenging because data scientists need to make difficult decisions about which preprocessors to select and in which order to compose them. In this paper, we study how to automate feature preprocessing (Auto-FP) for tabular data. Due to the large search space, a brute-force solution is prohibitively expensive. To address this challenge, we interestingly observe that Auto-FP can be modelled as either a hyperparameter optimization (HPO) or a neural architecture search (NAS) problem. This observation enables us to extend a variety of HPO and NAS algorithms to solve the Auto-FP problem. We conduct a comprehensive evaluation and analysis of 15 algorithms on 45 public ML datasets. Overall, evolution-based algorithms show the leading average ranking. Surprisingly, the random search turns out to be a strong baseline. Many surrogate-model-based and bandit-based search algorithms, which achieve good performance for HPO and NAS, do not outperform random search for Auto-FP. We analyze the reasons for our findings and conduct a bottleneck analysis to identify the opportunities to improve these algorithms. Furthermore, we explore how to extend Auto-FP to support parameter search and compare two ways to achieve this goal. In the end, we evaluate Auto-FP in an AutoML context and discuss the limitations of popular AutoML tools. To the best of our knowledge, this is the first study on automated feature preprocessing. We hope our work can inspire researchers to develop new algorithms tailored for Auto-FP.
BenchTemp: A General Benchmark for Evaluating Temporal Graph Neural Networks
Aug 31, 2023To handle graphs in which features or connectivities are evolving over time, a series of temporal graph neural networks (TGNNs) have been proposed. Despite the success of these TGNNs, the previous TGNN evaluations reveal several limitations regarding four critical issues: 1) inconsistent datasets, 2) inconsistent evaluation pipelines, 3) lacking workload diversity, and 4) lacking efficient comparison. Overall, there lacks an empirical study that puts TGNN models onto the same ground and compares them comprehensively. To this end, we propose BenchTemp, a general benchmark for evaluating TGNN models on various workloads. BenchTemp provides a set of benchmark datasets so that different TGNN models can be fairly compared. Further, BenchTemp engineers a standard pipeline that unifies the TGNN evaluation. With BenchTemp, we extensively compare the representative TGNN models on different tasks (e.g., link prediction and node classification) and settings (transductive and inductive), w.r.t. both effectiveness and efficiency metrics. We have made BenchTemp publicly available at https://github.com/qianghuangwhu/benchtemp.
Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees
Jun 02, 2022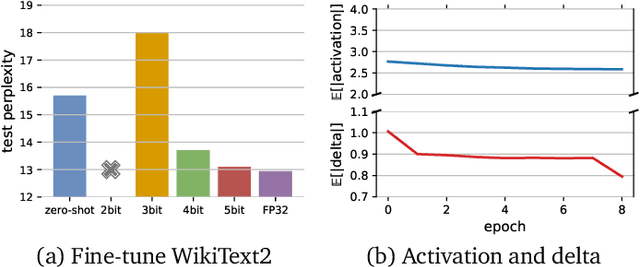

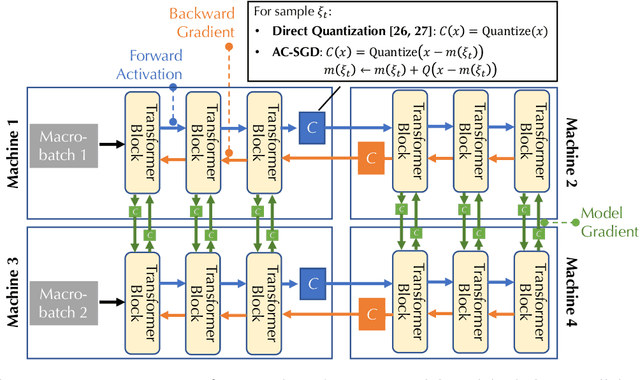

Communication compression is a crucial technique for modern distributed learning systems to alleviate their communication bottlenecks over slower networks. Despite recent intensive studies of gradient compression for data parallel-style training, compressing the activations for models trained with pipeline parallelism is still an open problem. In this paper, we propose AC-SGD, a novel activation compression algorithm for communication-efficient pipeline parallelism training over slow networks. Different from previous efforts in activation compression, instead of compressing activation values directly, AC-SGD compresses the changes of the activations. This allows us to show, to the best of our knowledge for the first time, that one can still achieve $O(1/\sqrt{T})$ convergence rate for non-convex objectives under activation compression, without making assumptions on gradient unbiasedness that do not hold for deep learning models with non-linear activation functions.We then show that AC-SGD can be optimized and implemented efficiently, without additional end-to-end runtime overhead.We evaluated AC-SGD to fine-tune language models with up to 1.5 billion parameters, compressing activations to 2-4 bits.AC-SGD provides up to 4.3X end-to-end speed-up in slower networks, without sacrificing model quality. Moreover, we also show that AC-SGD can be combined with state-of-the-art gradient compression algorithms to enable "end-to-end communication compression: All communications between machines, including model gradients, forward activations, and backward gradients are compressed into lower precision.This provides up to 4.9X end-to-end speed-up, without sacrificing model quality.
Decentralized Training of Foundation Models in Heterogeneous Environments
Jun 02, 2022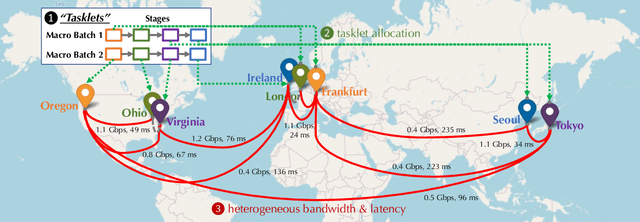
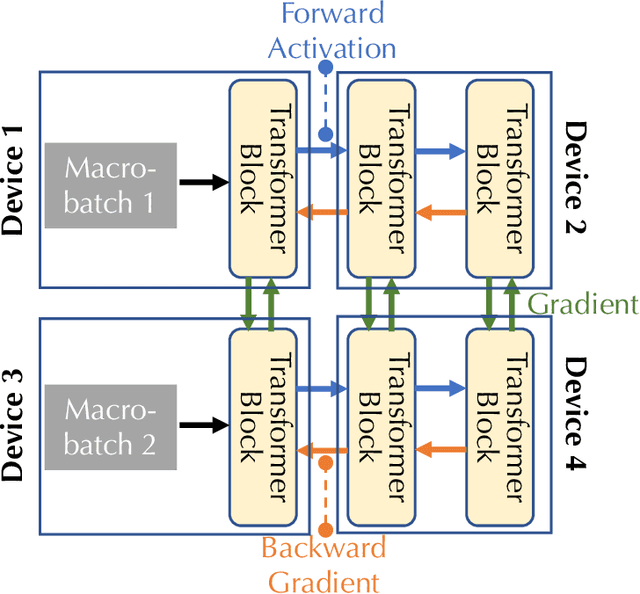
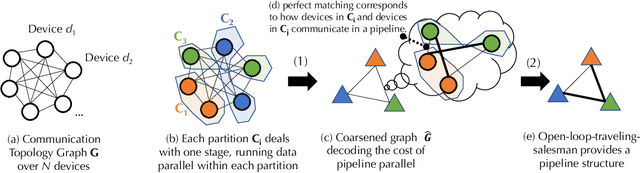

Training foundation models, such as GPT-3 and PaLM, can be extremely expensive, often involving tens of thousands of GPUs running continuously for months. These models are typically trained in specialized clusters featuring fast, homogeneous interconnects and using carefully designed software systems that support both data parallelism and model/pipeline parallelism. Such dedicated clusters can be costly and difficult to obtain. Can we instead leverage the much greater amount of decentralized, heterogeneous, and lower-bandwidth interconnected compute? Previous works examining the heterogeneous, decentralized setting focus on relatively small models that can be trained in a purely data parallel manner. State-of-the-art schemes for model parallel foundation model training, such as Megatron, only consider the homogeneous data center setting. In this paper, we present the first study of training large foundation models with model parallelism in a decentralized regime over a heterogeneous network. Our key technical contribution is a scheduling algorithm that allocates different computational "tasklets" in the training of foundation models to a group of decentralized GPU devices connected by a slow heterogeneous network. We provide a formal cost model and further propose an efficient evolutionary algorithm to find the optimal allocation strategy. We conduct extensive experiments that represent different scenarios for learning over geo-distributed devices simulated using real-world network measurements. In the most extreme case, across 8 different cities spanning 3 continents, our approach is 4.8X faster than prior state-of-the-art training systems (Megatron).
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021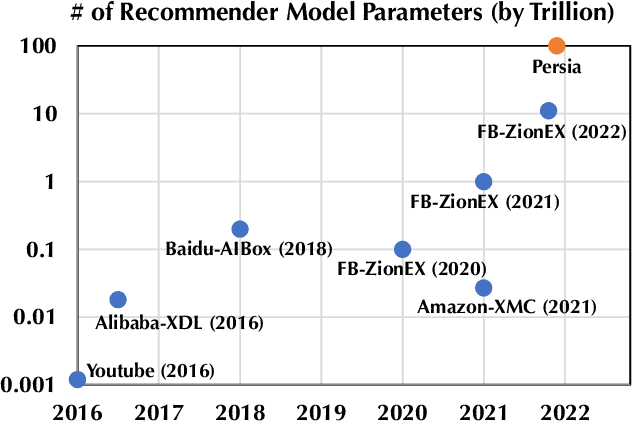
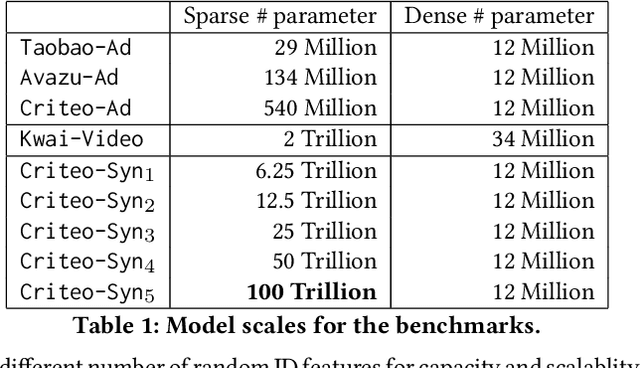
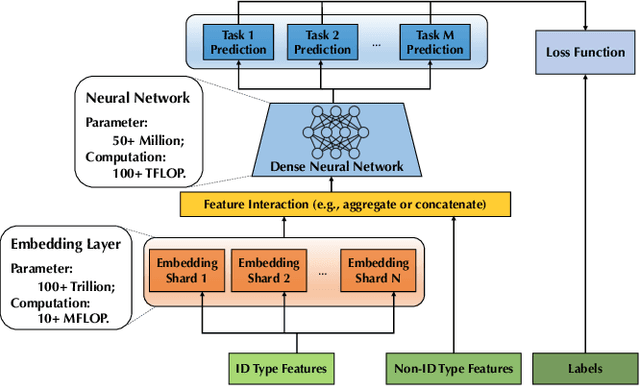
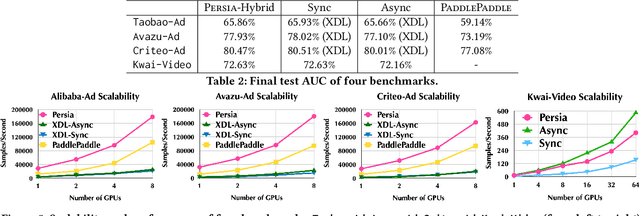
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.