 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-FP: An Experimental Study of Automated Feature Preprocessing for Tabular Data
Paper and Code


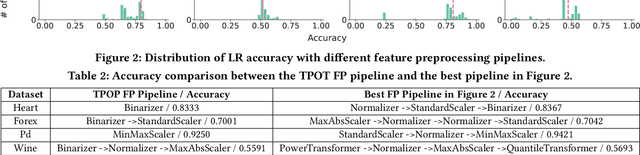

Classical machine learning models, such as linear models and tree-based models, are widely used in industry. These models are sensitive to data distribution, thus feature preprocessing, which transforms features from one distribution to another, is a crucial step to ensure good model quality. Manually constructing a feature preprocessing pipeline is challenging because data scientists need to make difficult decisions about which preprocessors to select and in which order to compose them. In this paper, we study how to automate feature preprocessing (Auto-FP) for tabular data. Due to the large search space, a brute-force solution is prohibitively expensive. To address this challenge, we interestingly observe that Auto-FP can be modelled as either a hyperparameter optimization (HPO) or a neural architecture search (NAS) problem. This observation enables us to extend a variety of HPO and NAS algorithms to solve the Auto-FP problem. We conduct a comprehensive evaluation and analysis of 15 algorithms on 45 public ML datasets. Overall, evolution-based algorithms show the leading average ranking. Surprisingly, the random search turns out to be a strong baseline. Many surrogate-model-based and bandit-based search algorithms, which achieve good performance for HPO and NAS, do not outperform random search for Auto-FP. We analyze the reasons for our findings and conduct a bottleneck analysis to identify the opportunities to improve these algorithms. Furthermore, we explore how to extend Auto-FP to support parameter search and compare two ways to achieve this goal. In the end, we evaluate Auto-FP in an AutoML context and discuss the limitations of popular AutoML tools. To the best of our knowledge, this is the first study on automated feature preprocessing. We hope our work can inspire researchers to develop new algorithms tailored for Auto-FP.