 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Apr 18, 2024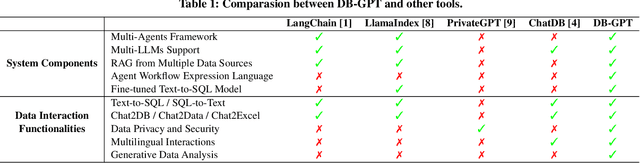
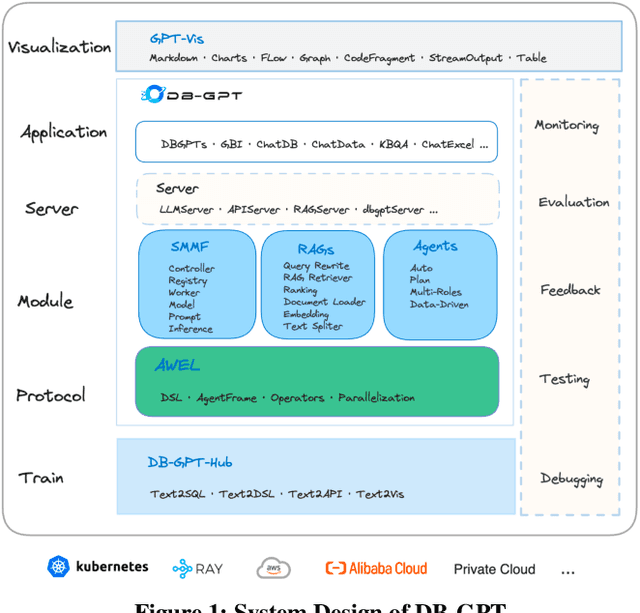

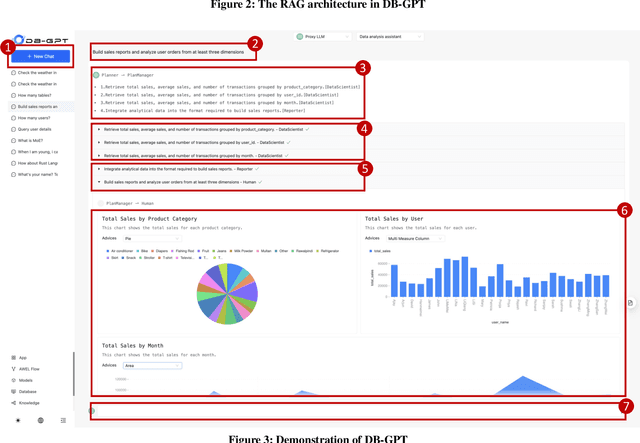
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
CleanAgent: Automating Data Standardization with LLM-based Agents
Mar 13, 2024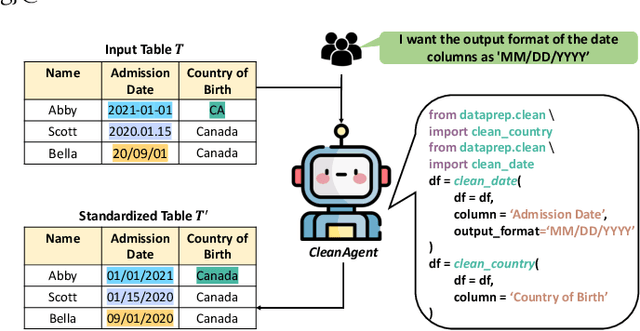
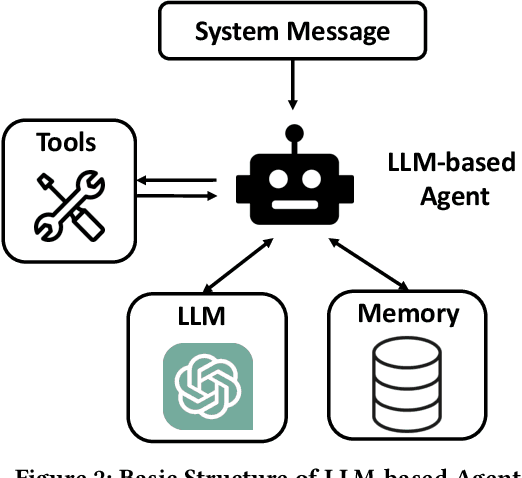
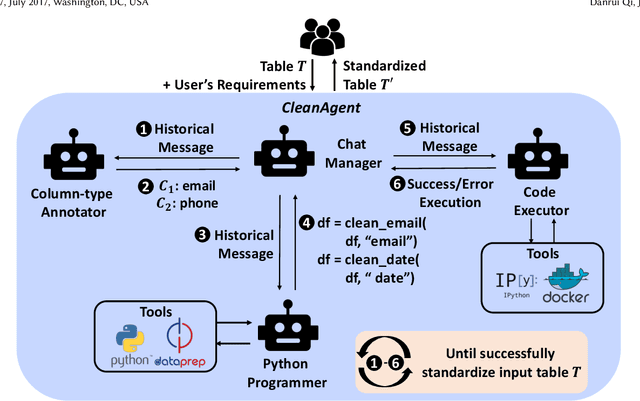
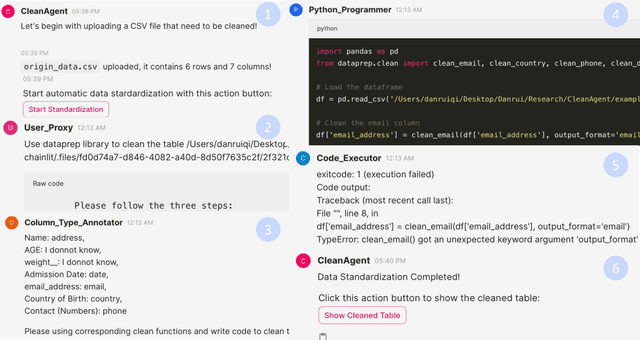
Data standardization is a crucial part in data science life cycle. While tools like Pandas offer robust functionalities, their complexity and the manual effort required for customizing code to diverse column types pose significant challenges. Although large language models (LLMs) like ChatGPT have shown promise in automating this process through natural language understanding and code generation, it still demands expert-level programming knowledge and continuous interaction for prompt refinement. To solve these challenges, our key idea is to propose a Python library with declarative, unified APIs for standardizing column types, simplifying the code generation of LLM with concise API calls. We first propose Dataprep.Clean which is written as a component of the Dataprep Library, offers a significant reduction in complexity by enabling the standardization of specific column types with a single line of code. Then we introduce the CleanAgent framework integrating Dataprep.Clean and LLM-based agents to automate the data standardization process. With CleanAgent, data scientists need only provide their requirements once, allowing for a hands-free, automatic standardization process.
FeatAug: Automatic Feature Augmentation From One-to-Many Relationship Tables
Mar 11, 2024Feature augmentation from one-to-many relationship tables is a critical but challenging problem in ML model development. To augment good features, data scientists need to come up with SQL queries manually, which is time-consuming. Featuretools [1] is a widely used tool by the data science community to automatically augment the training data by extracting new features from relevant tables. It represents each feature as a group-by aggregation SQL query on relevant tables and can automatically generate these SQL queries. However, it does not include predicates in these queries, which significantly limits its application in many real-world scenarios. To overcome this limitation, we propose FEATAUG, a new feature augmentation framework that automatically extracts predicate-aware SQL queries from one-to-many relationship tables. This extension is not trivial because considering predicates will exponentially increase the number of candidate queries. As a result, the original Featuretools framework, which materializes all candidate queries, will not work and needs to be redesigned. We formally define the problem and model it as a hyperparameter optimization problem. We discuss how the Bayesian Optimization can be applied here and propose a novel warm-up strategy to optimize it. To make our algorithm more practical, we also study how to identify promising attribute combinations for predicates. We show that how the beam search idea can partially solve the problem and propose several techniques to further optimize it. Our experiments on four real-world datasets demonstrate that FeatAug extracts more effective features compared to Featuretools and other baselines. The code is open-sourced at https://github.com/sfu-db/FeatAug
Auto-FP: An Experimental Study of Automated Feature Preprocessing for Tabular Data
Oct 04, 2023

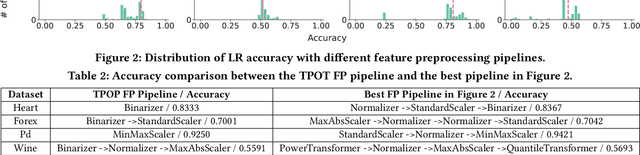

Classical machine learning models, such as linear models and tree-based models, are widely used in industry. These models are sensitive to data distribution, thus feature preprocessing, which transforms features from one distribution to another, is a crucial step to ensure good model quality. Manually constructing a feature preprocessing pipeline is challenging because data scientists need to make difficult decisions about which preprocessors to select and in which order to compose them. In this paper, we study how to automate feature preprocessing (Auto-FP) for tabular data. Due to the large search space, a brute-force solution is prohibitively expensive. To address this challenge, we interestingly observe that Auto-FP can be modelled as either a hyperparameter optimization (HPO) or a neural architecture search (NAS) problem. This observation enables us to extend a variety of HPO and NAS algorithms to solve the Auto-FP problem. We conduct a comprehensive evaluation and analysis of 15 algorithms on 45 public ML datasets. Overall, evolution-based algorithms show the leading average ranking. Surprisingly, the random search turns out to be a strong baseline. Many surrogate-model-based and bandit-based search algorithms, which achieve good performance for HPO and NAS, do not outperform random search for Auto-FP. We analyze the reasons for our findings and conduct a bottleneck analysis to identify the opportunities to improve these algorithms. Furthermore, we explore how to extend Auto-FP to support parameter search and compare two ways to achieve this goal. In the end, we evaluate Auto-FP in an AutoML context and discuss the limitations of popular AutoML tools. To the best of our knowledge, this is the first study on automated feature preprocessing. We hope our work can inspire researchers to develop new algorithms tailored for Auto-FP.