 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
MedAD-R1: Eliciting Consistent Reasoning in Interpretible Medical Anomaly Detection via Consistency-Reinforced Policy Optimization
Feb 01, 2026Medical Anomaly Detection (MedAD) presents a significant opportunity to enhance diagnostic accuracy using Large Multimodal Models (LMMs) to interpret and answer questions based on medical images. However, the reliance on Supervised Fine-Tuning (SFT) on simplistic and fragmented datasets has hindered the development of models capable of plausible reasoning and robust multimodal generalization. To overcome this, we introduce MedAD-38K, the first large-scale, multi-modal, and multi-center benchmark for MedAD featuring diagnostic Chain-of-Thought (CoT) annotations alongside structured Visual Question-Answering (VQA) pairs. On this foundation, we propose a two-stage training framework. The first stage, Cognitive Injection, uses SFT to instill foundational medical knowledge and align the model with a structured think-then-answer paradigm. Given that standard policy optimization can produce reasoning that is disconnected from the final answer, the second stage incorporates Consistency Group Relative Policy Optimization (Con-GRPO). This novel algorithm incorporates a crucial consistency reward to ensure the generated reasoning process is relevant and logically coherent with the final diagnosis. Our proposed model, MedAD-R1, achieves state-of-the-art (SOTA) performance on the MedAD-38K benchmark, outperforming strong baselines by more than 10\%. This superior performance stems from its ability to generate transparent and logically consistent reasoning pathways, offering a promising approach to enhancing the trustworthiness and interpretability of AI for clinical decision support.
Animate Any Character in Any World
Dec 18, 2025Recent advances in world models have greatly enhanced interactive environment simulation. Existing methods mainly fall into two categories: (1) static world generation models, which construct 3D environments without active agents, and (2) controllable-entity models, which allow a single entity to perform limited actions in an otherwise uncontrollable environment. In this work, we introduce AniX, leveraging the realism and structural grounding of static world generation while extending controllable-entity models to support user-specified characters capable of performing open-ended actions. Users can provide a 3DGS scene and a character, then direct the character through natural language to perform diverse behaviors from basic locomotion to object-centric interactions while freely exploring the environment. AniX synthesizes temporally coherent video clips that preserve visual fidelity with the provided scene and character, formulated as a conditional autoregressive video generation problem. Built upon a pre-trained video generator, our training strategy significantly enhances motion dynamics while maintaining generalization across actions and characters. Our evaluation covers a broad range of aspects, including visual quality, character consistency, action controllability, and long-horizon coherence.
Spatia: Video Generation with Updatable Spatial Memory
Dec 17, 2025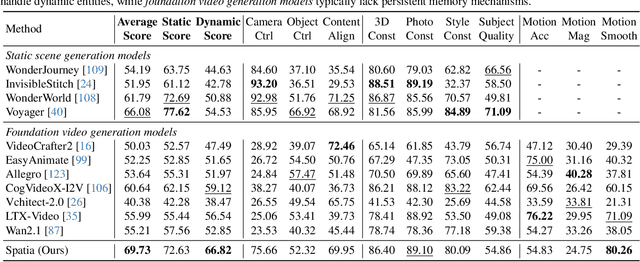
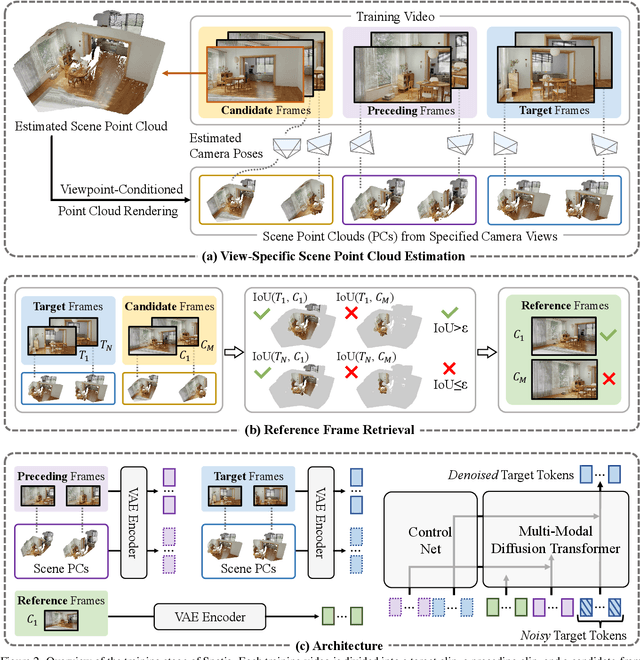

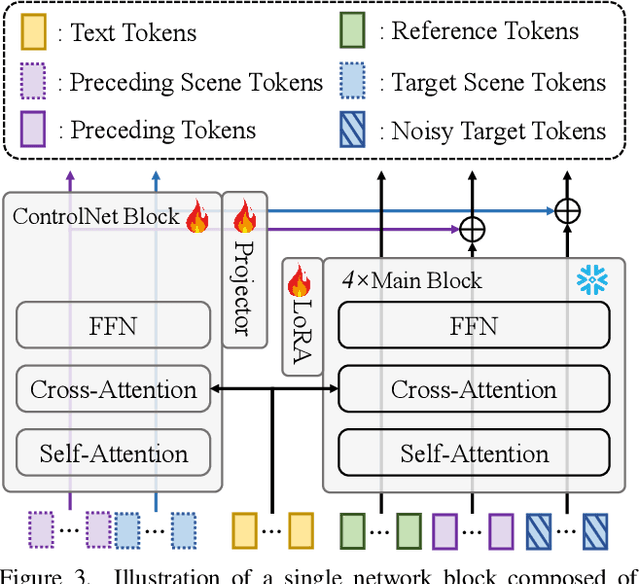
Existing video generation models struggle to maintain long-term spatial and temporal consistency due to the dense, high-dimensional nature of video signals. To overcome this limitation, we propose Spatia, a spatial memory-aware video generation framework that explicitly preserves a 3D scene point cloud as persistent spatial memory. Spatia iteratively generates video clips conditioned on this spatial memory and continuously updates it through visual SLAM. This dynamic-static disentanglement design enhances spatial consistency throughout the generation process while preserving the model's ability to produce realistic dynamic entities. Furthermore, Spatia enables applications such as explicit camera control and 3D-aware interactive editing, providing a geometrically grounded framework for scalable, memory-driven video generation.
From Virtual Games to Real-World Play
Jun 23, 2025



We introduce RealPlay, a neural network-based real-world game engine that enables interactive video generation from user control signals. Unlike prior works focused on game-style visuals, RealPlay aims to produce photorealistic, temporally consistent video sequences that resemble real-world footage. It operates in an interactive loop: users observe a generated scene, issue a control command, and receive a short video chunk in response. To enable such realistic and responsive generation, we address key challenges including iterative chunk-wise prediction for low-latency feedback, temporal consistency across iterations, and accurate control response. RealPlay is trained on a combination of labeled game data and unlabeled real-world videos, without requiring real-world action annotations. Notably, we observe two forms of generalization: (1) control transfer-RealPlay effectively maps control signals from virtual to real-world scenarios; and (2) entity transfer-although training labels originate solely from a car racing game, RealPlay generalizes to control diverse real-world entities, including bicycles and pedestrians, beyond vehicles. Project page can be found: https://wenqsun.github.io/RealPlay/
Prediction of Halo Coronal Mass Ejections Using SDO/HMI Vector Magnetic Data Products and a Transformer Model
Mar 05, 2025We present a transformer model, named DeepHalo, to predict the occurrence of halo coronal mass ejections (CMEs). Our model takes as input an active region (AR) and a profile, where the profile contains a time series of data samples in the AR that are collected 24 hours before the beginning of a day, and predicts whether the AR would produce a halo CME during that day. Each data sample contains physical parameters, or features, derived from photospheric vector magnetic field data taken by the Helioseismic and Magnetic Imager (HMI) on board the Solar Dynamics Observatory (SDO). We survey and match CME events in the Space Weather Database Of Notification, Knowledge, Information (DONKI) and Large Angle and Spectrometric Coronagraph (LASCO) CME Catalog, and compile a list of CMEs including halo CMEs and non-halo CMEs associated with ARs in the period between November 2010 and August 2023. We use the information gathered above to build the labels (positive versus negative) of the data samples and profiles at hand, where the labels are needed for machine learning. Experimental results show that DeepHalo with a true skill statistics (TSS) score of 0.907 outperforms a closely related long short-term memory network with a TSS score of 0.821. To our knowledge, this is the first time that the transformer model has been used for halo CME prediction.
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Mar 03, 2025The sequential nature of modern LLMs makes them expensive and slow, and speculative sampling has proven to be an effective solution to this problem. Methods like EAGLE perform autoregression at the feature level, reusing top-layer features from the target model to achieve better results than vanilla speculative sampling. A growing trend in the LLM community is scaling up training data to improve model intelligence without increasing inference costs. However, we observe that scaling up data provides limited improvements for EAGLE. We identify that this limitation arises from EAGLE's feature prediction constraints. In this paper, we introduce EAGLE-3, which abandons feature prediction in favor of direct token prediction and replaces reliance on top-layer features with multi-layer feature fusion via a technique named training-time test. These improvements significantly enhance performance and enable the draft model to fully benefit from scaling up training data. Our experiments include both chat models and reasoning models, evaluated on five tasks. The results show that EAGLE-3 achieves a speedup ratio up to 6.5x, with about 1.4x improvement over EAGLE-2. The code is available at https://github.com/SafeAILab/EAGLE.
An Interpretable Machine Learning Approach to Understanding the Relationships between Solar Flares and Source Active Regions
Feb 20, 2025Solar flares are defined as outbursts on the surface of the Sun. They occur when energy accumulated in magnetic fields enclosing solar active regions (ARs) is abruptly expelled. Solar flares and associated coronal mass ejections are sources of space weather that adversely impact devices at or near Earth, including the obstruction of high-frequency radio waves utilized for communication and the deterioration of power grid operations. Tracking and delivering early and precise predictions of solar flares is essential for readiness and catastrophe risk mitigation. This paper employs the random forest (RF) model to address the binary classification task, analyzing the links between solar flares and their originating ARs with observational data gathered from 2011 to 2021 by SolarMonitor.org and the XRT flare database. We seek to identify the physical features of a source AR that significantly influence its potential to trigger >=C-class flares. We found that the features of AR_Type_Today, Hale_Class_Yesterday are the most and the least prepotent features, respectively. NoS_Difference has a remarkable effect in decision-making in both global and local interpretations.
Encrypted Large Model Inference: The Equivariant Encryption Paradigm
Feb 03, 2025Large scale deep learning model, such as modern language models and diffusion architectures, have revolutionized applications ranging from natural language processing to computer vision. However, their deployment in distributed or decentralized environments raises significant privacy concerns, as sensitive data may be exposed during inference. Traditional techniques like secure multi-party computation, homomorphic encryption, and differential privacy offer partial remedies but often incur substantial computational overhead, latency penalties, or limited compatibility with non-linear network operations. In this work, we introduce Equivariant Encryption (EE), a novel paradigm designed to enable secure, "blind" inference on encrypted data with near zero performance overhead. Unlike fully homomorphic approaches that encrypt the entire computational graph, EE selectively obfuscates critical internal representations within neural network layers while preserving the exact functionality of both linear and a prescribed set of non-linear operations. This targeted encryption ensures that raw inputs, intermediate activations, and outputs remain confidential, even when processed on untrusted infrastructure. We detail the theoretical foundations of EE, compare its performance and integration complexity against conventional privacy preserving techniques, and demonstrate its applicability across a range of architectures, from convolutional networks to large language models. Furthermore, our work provides a comprehensive threat analysis, outlining potential attack vectors and baseline strategies, and benchmarks EE against standard inference pipelines in decentralized settings. The results confirm that EE maintains high fidelity and throughput, effectively bridging the gap between robust data confidentiality and the stringent efficiency requirements of modern, large scale model inference.
The Matrix: Infinite-Horizon World Generation with Real-Time Moving Control
Dec 04, 2024



We present The Matrix, the first foundational realistic world simulator capable of generating continuous 720p high-fidelity real-scene video streams with real-time, responsive control in both first- and third-person perspectives, enabling immersive exploration of richly dynamic environments. Trained on limited supervised data from AAA games like Forza Horizon 5 and Cyberpunk 2077, complemented by large-scale unsupervised footage from real-world settings like Tokyo streets, The Matrix allows users to traverse diverse terrains -- deserts, grasslands, water bodies, and urban landscapes -- in continuous, uncut hour-long sequences. Operating at 16 FPS, the system supports real-time interactivity and demonstrates zero-shot generalization, translating virtual game environments to real-world contexts where collecting continuous movement data is often infeasible. For example, The Matrix can simulate a BMW X3 driving through an office setting--an environment present in neither gaming data nor real-world sources. This approach showcases the potential of AAA game data to advance robust world models, bridging the gap between simulations and real-world applications in scenarios with limited data.