 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Generative Game Engine: Breaking the Resolution Wall via Hardware-Algorithm Co-Design
Jan 31, 2026Real-time generative game engines represent a paradigm shift in interactive simulation, promising to replace traditional graphics pipelines with neural world models. However, existing approaches are fundamentally constrained by the ``Memory Wall,'' restricting practical deployments to low resolutions (e.g., $64 \times 64$). This paper bridges the gap between generative models and high-resolution neural simulations by introducing a scalable \textit{Hardware-Algorithm Co-Design} framework. We identify that high-resolution generation suffers from a critical resource mismatch: the World Model is compute-bound while the Decoder is memory-bound. To address this, we propose a heterogeneous architecture that intelligently decouples these components across a cluster of AI accelerators. Our system features three core innovations: (1) an asymmetric resource allocation strategy that optimizes throughput under sequence parallelism constraints; (2) a memory-centric operator fusion scheme that minimizes off-chip bandwidth usage; and (3) a manifold-aware latent extrapolation mechanism that exploits temporal redundancy to mask latency. We validate our approach on a cluster of programmable AI accelerators, enabling real-time generation at $720 \times 480$ resolution -- a $50\times$ increase in pixel throughput over prior baselines. Evaluated on both continuous 3D racing and discrete 2D platformer benchmarks, our system delivers fluid 26.4 FPS and 48.3 FPS respectively, with an amortized effective latency of 2.7 ms. This work demonstrates that resolving the ``Memory Wall'' via architectural co-design is not merely an optimization, but a prerequisite for enabling high-fidelity, responsive neural gameplay.
Addressing the ID-Matching Challenge in Long Video Captioning
Oct 08, 2025Generating captions for long and complex videos is both critical and challenging, with significant implications for the growing fields of text-to-video generation and multi-modal understanding. One key challenge in long video captioning is accurately recognizing the same individuals who appear in different frames, which we refer to as the ID-Matching problem. Few prior works have focused on this important issue. Those that have, usually suffer from limited generalization and depend on point-wise matching, which limits their overall effectiveness. In this paper, unlike previous approaches, we build upon LVLMs to leverage their powerful priors. We aim to unlock the inherent ID-Matching capabilities within LVLMs themselves to enhance the ID-Matching performance of captions. Specifically, we first introduce a new benchmark for assessing the ID-Matching capabilities of video captions. Using this benchmark, we investigate LVLMs containing GPT-4o, revealing key insights that the performance of ID-Matching can be improved through two methods: 1) enhancing the usage of image information and 2) increasing the quantity of information of individual descriptions. Based on these insights, we propose a novel video captioning method called Recognizing Identities for Captioning Effectively (RICE). Extensive experiments including assessments of caption quality and ID-Matching performance, demonstrate the superiority of our approach. Notably, when implemented on GPT-4o, our RICE improves the precision of ID-Matching from 50% to 90% and improves the recall of ID-Matching from 15% to 80% compared to baseline. RICE makes it possible to continuously track different individuals in the captions of long videos.
CertDW: Towards Certified Dataset Ownership Verification via Conformal Prediction
Jun 16, 2025



Deep neural networks (DNNs) rely heavily on high-quality open-source datasets (e.g., ImageNet) for their success, making dataset ownership verification (DOV) crucial for protecting public dataset copyrights. In this paper, we find existing DOV methods (implicitly) assume that the verification process is faithful, where the suspicious model will directly verify ownership by using the verification samples as input and returning their results. However, this assumption may not necessarily hold in practice and their performance may degrade sharply when subjected to intentional or unintentional perturbations. To address this limitation, we propose the first certified dataset watermark (i.e., CertDW) and CertDW-based certified dataset ownership verification method that ensures reliable verification even under malicious attacks, under certain conditions (e.g., constrained pixel-level perturbation). Specifically, inspired by conformal prediction, we introduce two statistical measures, including principal probability (PP) and watermark robustness (WR), to assess model prediction stability on benign and watermarked samples under noise perturbations. We prove there exists a provable lower bound between PP and WR, enabling ownership verification when a suspicious model's WR value significantly exceeds the PP values of multiple benign models trained on watermark-free datasets. If the number of PP values smaller than WR exceeds a threshold, the suspicious model is regarded as having been trained on the protected dataset. Extensive experiments on benchmark datasets verify the effectiveness of our CertDW method and its resistance to potential adaptive attacks. Our codes are at \href{https://github.com/NcepuQiaoTing/CertDW}{GitHub}.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
RAIN: Real-time Animation of Infinite Video Stream
Dec 27, 2024



Live animation has gained immense popularity for enhancing online engagement, yet achieving high-quality, real-time, and stable animation with diffusion models remains challenging, especially on consumer-grade GPUs. Existing methods struggle with generating long, consistent video streams efficiently, often being limited by latency issues and degraded visual quality over extended periods. In this paper, we introduce RAIN, a pipeline solution capable of animating infinite video streams in real-time with low latency using a single RTX 4090 GPU. The core idea of RAIN is to efficiently compute frame-token attention across different noise levels and long time-intervals while simultaneously denoising a significantly larger number of frame-tokens than previous stream-based methods. This design allows RAIN to generate video frames with much shorter latency and faster speed, while maintaining long-range attention over extended video streams, resulting in enhanced continuity and consistency. Consequently, a Stable Diffusion model fine-tuned with RAIN in just a few epochs can produce video streams in real-time and low latency without much compromise in quality or consistency, up to infinite long. Despite its advanced capabilities, the RAIN only introduces a few additional 1D attention blocks, imposing minimal additional burden. Experiments in benchmark datasets and generating super-long videos demonstrating that RAIN can animate characters in real-time with much better quality, accuracy, and consistency than competitors while costing less latency. All code and models will be made publicly available.
The Matrix: Infinite-Horizon World Generation with Real-Time Moving Control
Dec 04, 2024



We present The Matrix, the first foundational realistic world simulator capable of generating continuous 720p high-fidelity real-scene video streams with real-time, responsive control in both first- and third-person perspectives, enabling immersive exploration of richly dynamic environments. Trained on limited supervised data from AAA games like Forza Horizon 5 and Cyberpunk 2077, complemented by large-scale unsupervised footage from real-world settings like Tokyo streets, The Matrix allows users to traverse diverse terrains -- deserts, grasslands, water bodies, and urban landscapes -- in continuous, uncut hour-long sequences. Operating at 16 FPS, the system supports real-time interactivity and demonstrates zero-shot generalization, translating virtual game environments to real-world contexts where collecting continuous movement data is often infeasible. For example, The Matrix can simulate a BMW X3 driving through an office setting--an environment present in neither gaming data nor real-world sources. This approach showcases the potential of AAA game data to advance robust world models, bridging the gap between simulations and real-world applications in scenarios with limited data.
BACON: Supercharge Your VLM with Bag-of-Concept Graph to Mitigate Hallucinations
Jul 03, 2024



This paper presents Bag-of-Concept Graph (BACON) to gift models with limited linguistic abilities to taste the privilege of Vision Language Models (VLMs) and boost downstream tasks such as detection, visual question answering (VQA), and image generation. Since the visual scenes in physical worlds are structured with complex relations between objects, BACON breaks down annotations into basic minimum elements and presents them in a graph structure. Element-wise style enables easy understanding, and structural composition liberates difficult locating. Careful prompt design births the BACON captions with the help of public-available VLMs and segmentation methods. In this way, we gather a dataset with 100K annotated images, which endow VLMs with remarkable capabilities, such as accurately generating BACON, transforming prompts into BACON format, envisioning scenarios in the style of BACONr, and dynamically modifying elements within BACON through interactive dialogue and more. Wide representative experiments, including detection, VQA, and image generation tasks, tell BACON as a lifeline to achieve previous out-of-reach tasks or excel in their current cutting-edge solutions.
IBD-PSC: Input-level Backdoor Detection via Parameter-oriented Scaling Consistency
May 16, 2024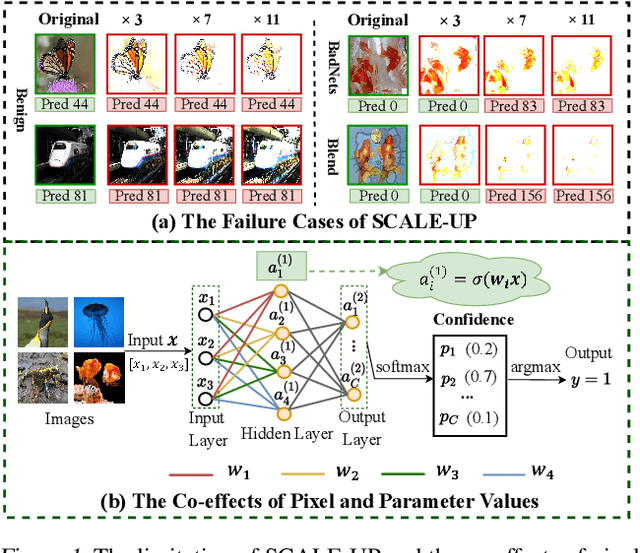
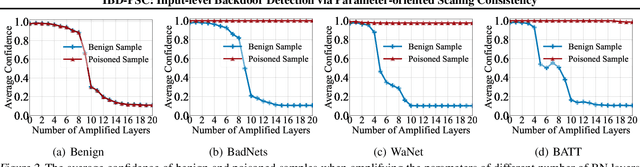
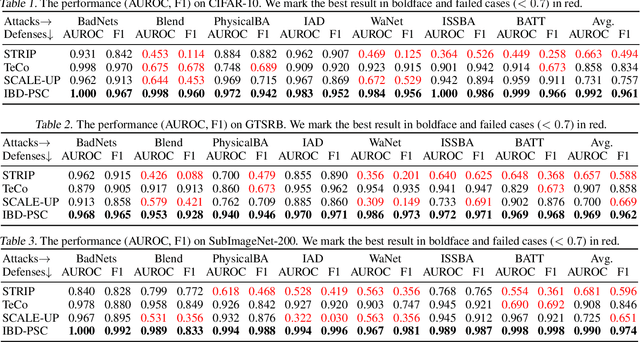
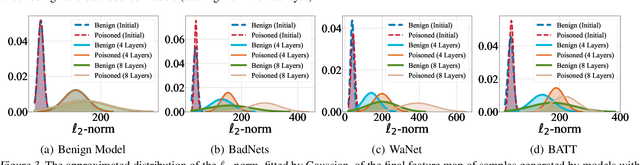
Deep neural networks (DNNs) are vulnerable to backdoor attacks, where adversaries can maliciously trigger model misclassifications by implanting a hidden backdoor during model training. This paper proposes a simple yet effective input-level backdoor detection (dubbed IBD-PSC) as a 'firewall' to filter out malicious testing images. Our method is motivated by an intriguing phenomenon, i.e., parameter-oriented scaling consistency (PSC), where the prediction confidences of poisoned samples are significantly more consistent than those of benign ones when amplifying model parameters. In particular, we provide theoretical analysis to safeguard the foundations of the PSC phenomenon. We also design an adaptive method to select BN layers to scale up for effective detection. Extensive experiments are conducted on benchmark datasets, verifying the effectiveness and efficiency of our IBD-PSC method and its resistance to adaptive attacks.
Regularized Mask Tuning: Uncovering Hidden Knowledge in Pre-trained Vision-Language Models
Aug 06, 2023



Prompt tuning and adapter tuning have shown great potential in transferring pre-trained vision-language models (VLMs) to various downstream tasks. In this work, we design a new type of tuning method, termed as regularized mask tuning, which masks the network parameters through a learnable selection. Inspired by neural pathways, we argue that the knowledge required by a downstream task already exists in the pre-trained weights but just gets concealed in the upstream pre-training stage. To bring the useful knowledge back into light, we first identify a set of parameters that are important to a given downstream task, then attach a binary mask to each parameter, and finally optimize these masks on the downstream data with the parameters frozen. When updating the mask, we introduce a novel gradient dropout strategy to regularize the parameter selection, in order to prevent the model from forgetting old knowledge and overfitting the downstream data. Experimental results on 11 datasets demonstrate the consistent superiority of our method over previous alternatives. It is noteworthy that we manage to deliver 18.73% performance improvement compared to the zero-shot CLIP via masking an average of only 2.56% parameters. Furthermore, our method is synergistic with most existing parameter-efficient tuning methods and can boost the performance on top of them. Project page can be found here (https://wuw2019.github.io/R-AMT/).
Eliminating Lipschitz Singularities in Diffusion Models
Jun 20, 2023Diffusion models, which employ stochastic differential equations to sample images through integrals, have emerged as a dominant class of generative models. However, the rationality of the diffusion process itself receives limited attention, leaving the question of whether the problem is well-posed and well-conditioned. In this paper, we uncover a vexing propensity of diffusion models: they frequently exhibit the infinite Lipschitz near the zero point of timesteps. This poses a threat to the stability and accuracy of the diffusion process, which relies on integral operations. We provide a comprehensive evaluation of the issue from both theoretical and empirical perspectives. To address this challenge, we propose a novel approach, dubbed E-TSDM, which eliminates the Lipschitz singularity of the diffusion model near zero. Remarkably, our technique yields a substantial improvement in performance, e.g., on the high-resolution FFHQ dataset ($256\times256$). Moreover, as a byproduct of our method, we manage to achieve a dramatic reduction in the Frechet Inception Distance of other acceleration methods relying on network Lipschitz, including DDIM and DPM-Solver, by over 33$\%$. We conduct extensive experiments on diverse datasets to validate our theory and method. Our work not only advances the understanding of the general diffusion process, but also provides insights for the design of diffusion models.