 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Backdoor Detection for Object Detection Models
Mar 19, 2025Object detection models are vulnerable to backdoor attacks, where attackers poison a small subset of training samples by embedding a predefined trigger to manipulate prediction. Detecting poisoned samples (i.e., those containing triggers) at test time can prevent backdoor activation. However, unlike image classification tasks, the unique characteristics of object detection -- particularly its output of numerous objects -- pose fresh challenges for backdoor detection. The complex attack effects (e.g., "ghost" object emergence or "vanishing" object) further render current defenses fundamentally inadequate. To this end, we design TRAnsformation Consistency Evaluation (TRACE), a brand-new method for detecting poisoned samples at test time in object detection. Our journey begins with two intriguing observations: (1) poisoned samples exhibit significantly more consistent detection results than clean ones across varied backgrounds. (2) clean samples show higher detection consistency when introduced to different focal information. Based on these phenomena, TRACE applies foreground and background transformations to each test sample, then assesses transformation consistency by calculating the variance in objects confidences. TRACE achieves black-box, universal backdoor detection, with extensive experiments showing a 30% improvement in AUROC over state-of-the-art defenses and resistance to adaptive attacks.
FLARE: Towards Universal Dataset Purification against Backdoor Attacks
Nov 29, 2024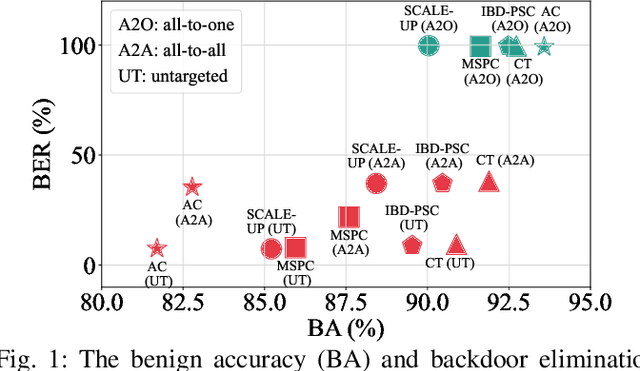
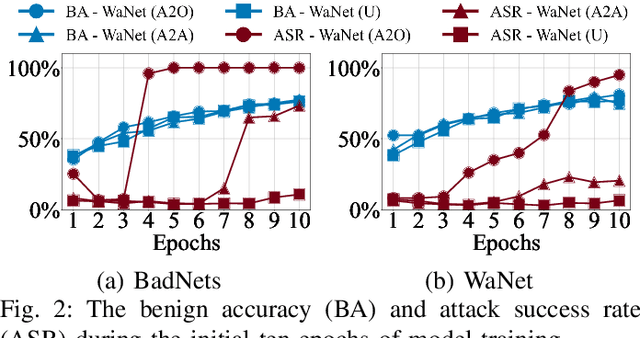
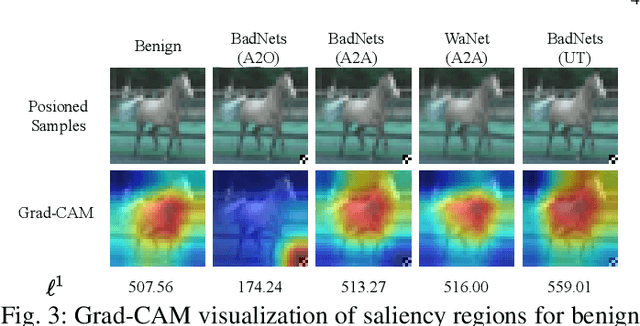
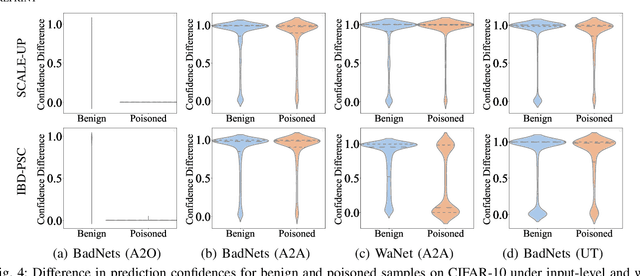
Deep neural networks (DNNs) are susceptible to backdoor attacks, where adversaries poison datasets with adversary-specified triggers to implant hidden backdoors, enabling malicious manipulation of model predictions. Dataset purification serves as a proactive defense by removing malicious training samples to prevent backdoor injection at its source. We first reveal that the current advanced purification methods rely on a latent assumption that the backdoor connections between triggers and target labels in backdoor attacks are simpler to learn than the benign features. We demonstrate that this assumption, however, does not always hold, especially in all-to-all (A2A) and untargeted (UT) attacks. As a result, purification methods that analyze the separation between the poisoned and benign samples in the input-output space or the final hidden layer space are less effective. We observe that this separability is not confined to a single layer but varies across different hidden layers. Motivated by this understanding, we propose FLARE, a universal purification method to counter various backdoor attacks. FLARE aggregates abnormal activations from all hidden layers to construct representations for clustering. To enhance separation, FLARE develops an adaptive subspace selection algorithm to isolate the optimal space for dividing an entire dataset into two clusters. FLARE assesses the stability of each cluster and identifies the cluster with higher stability as poisoned. Extensive evaluations on benchmark datasets demonstrate the effectiveness of FLARE against 22 representative backdoor attacks, including all-to-one (A2O), all-to-all (A2A), and untargeted (UT) attacks, and its robustness to adaptive attacks.
IBD-PSC: Input-level Backdoor Detection via Parameter-oriented Scaling Consistency
May 16, 2024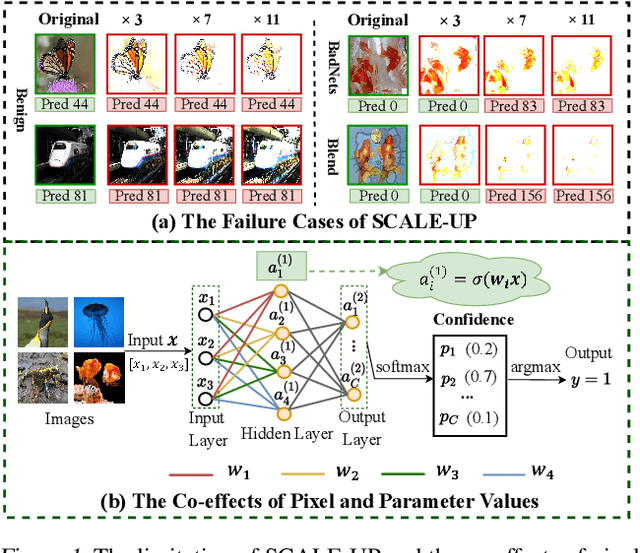
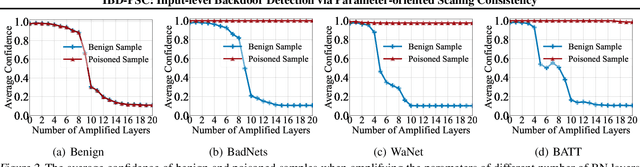
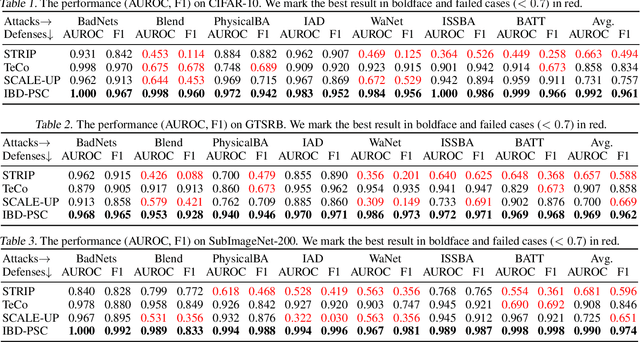
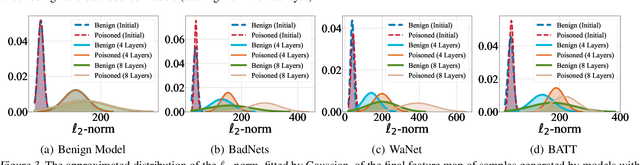
Deep neural networks (DNNs) are vulnerable to backdoor attacks, where adversaries can maliciously trigger model misclassifications by implanting a hidden backdoor during model training. This paper proposes a simple yet effective input-level backdoor detection (dubbed IBD-PSC) as a 'firewall' to filter out malicious testing images. Our method is motivated by an intriguing phenomenon, i.e., parameter-oriented scaling consistency (PSC), where the prediction confidences of poisoned samples are significantly more consistent than those of benign ones when amplifying model parameters. In particular, we provide theoretical analysis to safeguard the foundations of the PSC phenomenon. We also design an adaptive method to select BN layers to scale up for effective detection. Extensive experiments are conducted on benchmark datasets, verifying the effectiveness and efficiency of our IBD-PSC method and its resistance to adaptive attacks.