 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShell-Supervised Gaussian Splatting for Urban Real-to-Sim Reconstruction
Jun 29, 2026Real-to-sim reconstruction for embodied AI requires geometry that is useful for collision reasoning, navigation, and agent-environment interaction, not only photorealistic novel-view synthesis. However, close-range urban facades are difficult for video-to-3D reconstruction: glass, reflections, repeated windows, and weak texture can produce visually plausible renderings with unstable surface geometry. We introduce shell-supervised Gaussian Splatting, a reconstruction-stage framework that uses an external facade structural shell as lightweight geometric supervision for video-driven Gaussian reconstruction. The method aligns an exterior shell to the video reconstruction frame, renders per-view depth, camera-space normal, and valid-mask maps, and applies these cues through mask-gated losses during Gaussian optimization. This design preserves RGB-driven appearance while regularizing only visible shell-supported facade regions. Experiments on anonymized close-range urban facade scenes show improved facade orientation and visible-surface point-cloud consistency over photo-only, monocular-cue, and surface-oriented Gaussian baselines, while maintaining comparable held-out rendering quality.
Concordia: JIT-Compiled Persistent-Kernel Checkpointing for Fault-Tolerant LLM Inference
Jun 22, 2026Long-running LLM agents keep valuable state resident on GPUs: KV caches, request schedulers, communication state, and sometimes online adapters. Losing this state after a GPU or communicator failure can discard minutes to hours of work, yet existing recovery mechanisms either restart the whole serving stack or require application-specific checkpoint logic inside every attention and runtime component. This paper argues that fault tolerance for such workloads needs a GPU-resident execution context: checkpoint hooks must run at device synchronization points, observe binary kernels that frameworks and libraries actually execute, and recover without putting the host CPU on the critical path. We present Concordia, a runtime that uses a device-resident persistent kernel as the substrate for fault-tolerant LLM inference. Concordia interposes on GPU module loading and supports PTX- and SASS-level instrumentation, allowing checkpoint and pause hooks to be inserted below framework code and library boundaries. For each registered LLM state region, Concordia JIT-compiles a specialized delta-checkpoint handler -- for example, a KV-block scanner, adapter-page scanner, or recovery applier -- and hot-swaps it into the persistent kernel's operator table. The persistent kernel consumes a lock-free ring buffer of compute, checkpoint, append-log, and recovery tasks, so the same always-on executor triggers dirty-page detection, stages deltas, and appends committed records to a CPU-visible log in CXL memory or host DRAM.
SurGE: Surrogate Gradient-guided Evolution for Co-design of Legged Robots with Parallel Elasticity
Jun 20, 2026Co-design of legged robots with elastic elements is challenging due to the non-differentiability of contact dynamics and mechanism engagement. This paper presents SurGE, a framework that computes surrogate gradients of the design objective through a differentiable pipeline consisting of a kinodynamic single-rigid-body (Kino-SRB) model and a design-aware control policy, and injects them into CMA-ES via mean shift with cosine-annealed step decay. On a 4-DOF design space of a hopping robot with unidirectional parallel spring, SurGE achieves 6 times lower cross-seed standard deviation and 18% tighter population concentration compared to vanilla CMA-ES, while matching or improving the best objective. Hardware experiments on a 2D design subspace show that, starting from a hand-tuned initial design, SurGE reduces the design objective by 37.65% on hardware, with the improvement trend identified in simulation transferring consistently to the physical system. SurGE provides the potential to accelerate non-differentiable co-design problems in legged robots via surrogate model gradients.
Transferable Physical-World Adversarial Patches Against Object Detection in Autonomous Driving
Apr 25, 2026Deep learning drives major advances in autonomous driving (AD), where object detectors are central to perception. However, adversarial attacks pose significant threats to the reliability and safety of these systems, with physical adversarial patches representing a particularly potent form of attack. Physical adversarial patch attacks pose severe risks but are usually crafted for a single model, yielding poor transferability to unseen detectors. We propose AdvAD, a transfer-based physical attack against object detection in autonomous driving. Instead of targeting a specific detector, AdvAD optimizes adversarial patches over multiple detection models in a unified framework, encouraging the learned perturbations to capture shared vulnerabilities across architectures. The optimization process adaptively balances model contributions and enforces robustness to physical variations. It further employs data augmentation and geometric transformations to maintain patch effectiveness under diverse physical conditions. Experiments in both digital and real-world settings show that AdvAD consistently outperforms state-of-the-art (SOTA) attacks in performance and transferability.
sleep2vec: Unified Cross-Modal Alignment for Heterogeneous Nocturnal Biosignals
Feb 14, 2026Tasks ranging from sleep staging to clinical diagnosis traditionally rely on standard polysomnography (PSG) devices, bedside monitors and wearable devices, which capture diverse nocturnal biosignals (e.g., EEG, EOG, ECG, SpO$_2$). However, heterogeneity across devices and frequent sensor dropout pose significant challenges for unified modelling of these multimodal signals. We present \texttt{sleep2vec}, a foundation model for diverse and incomplete nocturnal biosignals that learns a shared representation via cross-modal alignment. \texttt{sleep2vec} is contrastively pre-trained on 42,249 overnight recordings spanning nine modalities using a \textit{Demography, Age, Site \& History-aware InfoNCE} objective that incorporates physiological and acquisition metadata (\textit{e.g.}, age, gender, recording site) to dynamically weight negatives and mitigate cohort-specific shortcuts. On downstream sleep staging and clinical outcome assessment, \texttt{sleep2vec} consistently outperforms strong baselines and remains robust to any subset of available modalities and sensor dropout. We further characterize, to our knowledge for the first time, scaling laws for nocturnal biosignals with respect to modality diversity and model capacity. Together, these results show that unified cross-modal alignment, coupled with principled scaling, enables label-efficient, general-purpose modelling of real-world nocturnal biosignals.
Channel-Aware Conditional Diffusion Model for Secure MU-MISO Communications
Feb 03, 2026While information securityis a fundamental requirement for wireless communications, conventional optimization based approaches often struggle with real-time implementation, and deep models, typically discriminative in nature, may lack the ability to cope with unforeseen scenarios. To address this challenge, this paper investigates the design of legitimate beamforming and artificial noise (AN) to achieve physical layer security by exploiting the conditional diffusion model. Specifically, we reformulate the security optimization as a conditional generative process, using a diffusion model to learn the inherent distribution of near-optimal joint beamforming and AN strategies. We employ a U-Net architecture with cross-attention to integrate channel state information, as the basis for the generative process. Moreover, we fine-tune the trained model using an objective incorporating the sum secrecy rate such that the security performance is further enhanced. Finally, simulation results validate the learning process convergence and demonstrate that the proposed generative method achieves superior secrecy performance across various scenarios as compared with the baselines.
Towards Efficient 3D Object Detection for Vehicle-Infrastructure Collaboration via Risk-Intent Selection
Jan 06, 2026Vehicle-Infrastructure Collaborative Perception (VICP) is pivotal for resolving occlusion in autonomous driving, yet the trade-off between communication bandwidth and feature redundancy remains a critical bottleneck. While intermediate fusion mitigates data volume compared to raw sharing, existing frameworks typically rely on spatial compression or static confidence maps, which inefficiently transmit spatially redundant features from non-critical background regions. To address this, we propose Risk-intent Selective detection (RiSe), an interaction-aware framework that shifts the paradigm from identifying visible regions to prioritizing risk-critical ones. Specifically, we introduce a Potential Field-Trajectory Correlation Model (PTCM) grounded in potential field theory to quantitatively assess kinematic risks. Complementing this, an Intention-Driven Area Prediction Module (IDAPM) leverages ego-motion priors to proactively predict and filter key Bird's-Eye-View (BEV) areas essential for decision-making. By integrating these components, RiSe implements a semantic-selective fusion scheme that transmits high-fidelity features only from high-interaction regions, effectively acting as a feature denoiser. Extensive experiments on the DeepAccident dataset demonstrate that our method reduces communication volume to 0.71\% of full feature sharing while maintaining state-of-the-art detection accuracy, establishing a competitive Pareto frontier between bandwidth efficiency and perception performance.
Optimizing Diversity and Quality through Base-Aligned Model Collaboration
Nov 07, 2025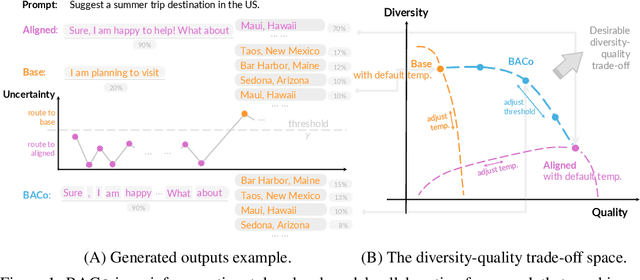
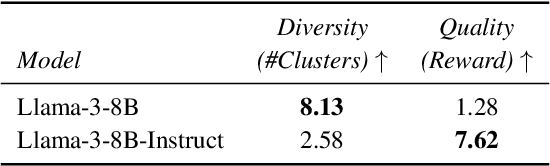
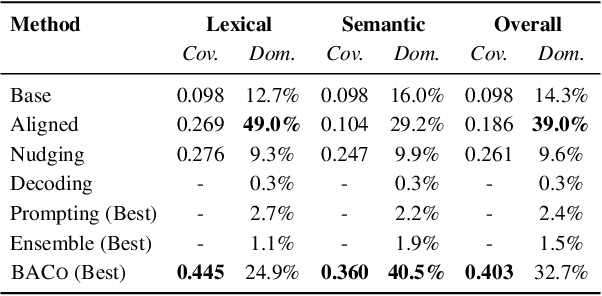
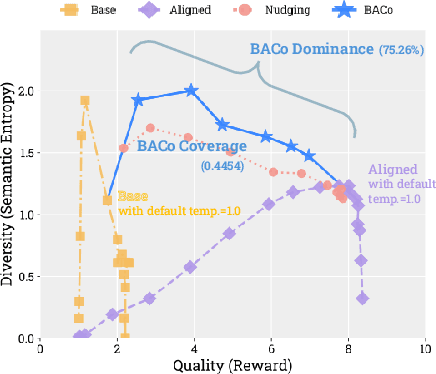
Alignment has greatly improved large language models (LLMs)' output quality at the cost of diversity, yielding highly similar outputs across generations. We propose Base-Aligned Model Collaboration (BACo), an inference-time token-level model collaboration framework that dynamically combines a base LLM with its aligned counterpart to optimize diversity and quality. Inspired by prior work (Fei et al., 2025), BACo employs routing strategies that determine, at each token, from which model to decode based on next-token prediction uncertainty and predicted contents' semantic role. Prior diversity-promoting methods, such as retraining, prompt engineering, and multi-sampling methods, improve diversity but often degrade quality or require costly decoding or post-training. In contrast, BACo achieves both high diversity and quality post hoc within a single pass, while offering strong controllability. We explore a family of routing strategies, across three open-ended generation tasks and 13 metrics covering diversity and quality, BACo consistently surpasses state-of-the-art inference-time baselines. With our best router, BACo achieves a 21.3% joint improvement in diversity and quality. Human evaluations also mirror these improvements. The results suggest that collaboration between base and aligned models can optimize and control diversity and quality.
Early GVHD Prediction in Liver Transplantation via Multi-Modal Deep Learning on Imbalanced EHR Data
Nov 06, 2025Graft-versus-host disease (GVHD) is a rare but often fatal complication in liver transplantation, with a very high mortality rate. By harnessing multi-modal deep learning methods to integrate heterogeneous and imbalanced electronic health records (EHR), we aim to advance early prediction of GVHD, paving the way for timely intervention and improved patient outcomes. In this study, we analyzed pre-transplant electronic health records (EHR) spanning the period before surgery for 2,100 liver transplantation patients, including 42 cases of graft-versus-host disease (GVHD), from a cohort treated at Mayo Clinic between 1992 and 2025. The dataset comprised four major modalities: patient demographics, laboratory tests, diagnoses, and medications. We developed a multi-modal deep learning framework that dynamically fuses these modalities, handles irregular records with missing values, and addresses extreme class imbalance through AUC-based optimization. The developed framework outperforms all single-modal and multi-modal machine learning baselines, achieving an AUC of 0.836, an AUPRC of 0.157, a recall of 0.768, and a specificity of 0.803. It also demonstrates the effectiveness of our approach in capturing complementary information from different modalities, leading to improved performance. Our multi-modal deep learning framework substantially improves existing approaches for early GVHD prediction. By effectively addressing the challenges of heterogeneity and extreme class imbalance in real-world EHR, it achieves accurate early prediction. Our proposed multi-modal deep learning method demonstrates promising results for early prediction of a GVHD in liver transplantation, despite the challenge of extremely imbalanced EHR data.
Unraveling Misinformation Propagation in LLM Reasoning
May 24, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning, positioning them as promising tools for supporting human problem-solving. However, what happens when their performance is affected by misinformation, i.e., incorrect inputs introduced by users due to oversights or gaps in knowledge? Such misinformation is prevalent in real-world interactions with LLMs, yet how it propagates within LLMs' reasoning process remains underexplored. Focusing on mathematical reasoning, we present a comprehensive analysis of how misinformation affects intermediate reasoning steps and final answers. We also examine how effectively LLMs can correct misinformation when explicitly instructed to do so. Even with explicit instructions, LLMs succeed less than half the time in rectifying misinformation, despite possessing correct internal knowledge, leading to significant accuracy drops (10.02% - 72.20%). Further analysis shows that applying factual corrections early in the reasoning process most effectively reduces misinformation propagation, and fine-tuning on synthesized data with early-stage corrections significantly improves reasoning factuality. Our work offers a practical approach to mitigating misinformation propagation.