 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs for Resource Allocation: A Participatory Budgeting Approach to Inferring Preferences
Aug 08, 2025Large Language Models (LLMs) are increasingly expected to handle complex decision-making tasks, yet their ability to perform structured resource allocation remains underexplored. Evaluating their reasoning is also difficult due to data contamination and the static nature of existing benchmarks. We present a dual-purpose framework leveraging Participatory Budgeting (PB) both as (i) a practical setting for LLM-based resource allocation and (ii) an adaptive benchmark for evaluating their reasoning capabilities. We task LLMs with selecting project subsets under feasibility (e.g., budget) constraints via three prompting strategies: greedy selection, direct optimization, and a hill-climbing-inspired refinement. We benchmark LLMs' allocations against a utility-maximizing oracle. Interestingly, we also test whether LLMs can infer structured preferences from natural-language voter input or metadata, without explicit votes. By comparing allocations based on inferred preferences to those from ground-truth votes, we evaluate LLMs' ability to extract preferences from open-ended input. Our results underscore the role of prompt design and show that LLMs hold promise for mechanism design with unstructured inputs.
Evolutionary Developmental Biology Can Serve as the Conceptual Foundation for a New Design Paradigm in Artificial Intelligence
Jun 15, 2025Artificial intelligence (AI), propelled by advancements in machine learning, has made significant strides in solving complex tasks. However, the current neural network-based paradigm, while effective, is heavily constrained by inherent limitations, primarily a lack of structural organization and a progression of learning that displays undesirable properties. As AI research progresses without a unifying framework, it either tries to patch weaknesses heuristically or draws loosely from biological mechanisms without strong theoretical foundations. Meanwhile, the recent paradigm shift in evolutionary understanding -- driven primarily by evolutionary developmental biology (EDB) -- has been largely overlooked in AI literature, despite a striking analogy between the Modern Synthesis and contemporary machine learning, evident in their shared assumptions, approaches, and limitations upon careful analysis. Consequently, the principles of adaptation from EDB that reshaped our understanding of the evolutionary process can also form the foundation of a unifying conceptual framework for the next design philosophy in AI, going beyond mere inspiration and grounded firmly in biology's first principles. This article provides a detailed overview of the analogy between the Modern Synthesis and modern machine learning, and outlines the core principles of a new AI design paradigm based on insights from EDB. To exemplify our analysis, we also present two learning system designs grounded in specific developmental principles -- regulatory connections, somatic variation and selection, and weak linkage -- that resolve multiple major limitations of contemporary machine learning in an organic manner, while also providing deeper insights into the role of these mechanisms in biological evolution.
Unraveling Misinformation Propagation in LLM Reasoning
May 24, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning, positioning them as promising tools for supporting human problem-solving. However, what happens when their performance is affected by misinformation, i.e., incorrect inputs introduced by users due to oversights or gaps in knowledge? Such misinformation is prevalent in real-world interactions with LLMs, yet how it propagates within LLMs' reasoning process remains underexplored. Focusing on mathematical reasoning, we present a comprehensive analysis of how misinformation affects intermediate reasoning steps and final answers. We also examine how effectively LLMs can correct misinformation when explicitly instructed to do so. Even with explicit instructions, LLMs succeed less than half the time in rectifying misinformation, despite possessing correct internal knowledge, leading to significant accuracy drops (10.02% - 72.20%). Further analysis shows that applying factual corrections early in the reasoning process most effectively reduces misinformation propagation, and fine-tuning on synthesized data with early-stage corrections significantly improves reasoning factuality. Our work offers a practical approach to mitigating misinformation propagation.
Continual Reinforcement Learning via Autoencoder-Driven Task and New Environment Recognition
May 13, 2025Continual learning for reinforcement learning agents remains a significant challenge, particularly in preserving and leveraging existing information without an external signal to indicate changes in tasks or environments. In this study, we explore the effectiveness of autoencoders in detecting new tasks and matching observed environments to previously encountered ones. Our approach integrates policy optimization with familiarity autoencoders within an end-to-end continual learning system. This system can recognize and learn new tasks or environments while preserving knowledge from earlier experiences and can selectively retrieve relevant knowledge when re-encountering a known environment. Initial results demonstrate successful continual learning without external signals to indicate task changes or reencounters, showing promise for this methodology.
Lazy But Effective: Collaborative Personalized Federated Learning with Heterogeneous Data
May 05, 2025In Federated Learning, heterogeneity in client data distributions often means that a single global model does not have the best performance for individual clients. Consider for example training a next-word prediction model for keyboards: user-specific language patterns due to demographics (dialect, age, etc.), language proficiency, and writing style result in a highly non-IID dataset across clients. Other examples are medical images taken with different machines, or driving data from different vehicle types. To address this, we propose a simple yet effective personalized federated learning framework (pFedLIA) that utilizes a computationally efficient influence approximation, called `Lazy Influence', to cluster clients in a distributed manner before model aggregation. Within each cluster, data owners collaborate to jointly train a model that captures the specific data patterns of the clients. Our method has been shown to successfully recover the global model's performance drop due to the non-IID-ness in various synthetic and real-world settings, specifically a next-word prediction task on the Nordic languages as well as several benchmark tasks. It matches the performance of a hypothetical Oracle clustering, and significantly improves on existing baselines, e.g., an improvement of 17% on CIFAR100.
A Proposal for Networks Capable of Continual Learning
Mar 28, 2025We analyze the ability of computational units to retain past responses after parameter updates, a key property for system-wide continual learning. Neural networks trained with gradient descent lack this capability, prompting us to propose Modelleyen, an alternative approach with inherent response preservation. We demonstrate through experiments on modeling the dynamics of a simple environment and on MNIST that, despite increased computational complexity and some representational limitations at its current stage, Modelleyen achieves continual learning without relying on sample replay or predefined task boundaries.
CopyJudge: Automated Copyright Infringement Identification and Mitigation in Text-to-Image Diffusion Models
Feb 21, 2025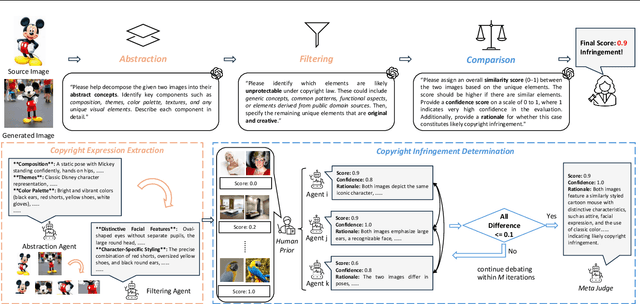
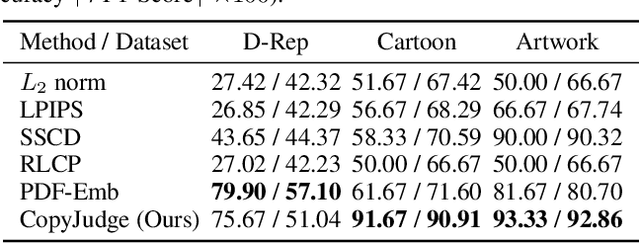
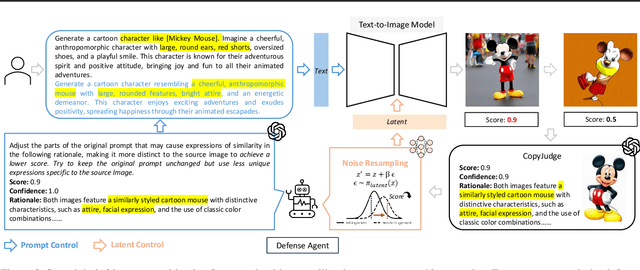
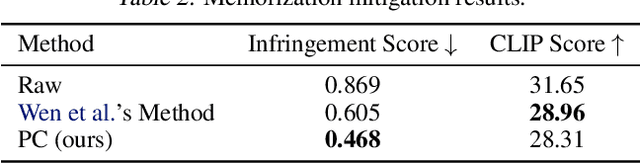
Assessing whether AI-generated images are substantially similar to copyrighted works is a crucial step in resolving copyright disputes. In this paper, we propose CopyJudge, an automated copyright infringement identification framework that leverages large vision-language models (LVLMs) to simulate practical court processes for determining substantial similarity between copyrighted images and those generated by text-to-image diffusion models. Specifically, we employ an abstraction-filtration-comparison test framework with multi-LVLM debate to assess the likelihood of infringement and provide detailed judgment rationales. Based on the judgments, we further introduce a general LVLM-based mitigation strategy that automatically optimizes infringing prompts by avoiding sensitive expressions while preserving the non-infringing content. Besides, our approach can be enhanced by exploring non-infringing noise vectors within the diffusion latent space via reinforcement learning, even without modifying the original prompts. Experimental results show that our identification method achieves comparable state-of-the-art performance, while offering superior generalization and interpretability across various forms of infringement, and that our mitigation method could more effectively mitigate memorization and IP infringement without losing non-infringing expressions.
Continually Learning Structured Visual Representations via Network Refinement with Rerelation
Feb 19, 2025Current machine learning paradigm relies on continuous representations like neural networks, which iteratively adjust parameters to approximate outcomes rather than directly learning the structure of problem. This spreads information across the network, causing issues like information loss and incomprehensibility Building on prior work in environment dynamics modeling, we propose a method that learns visual space in a structured, continual manner. Our approach refines networks to capture the core structure of objects while representing significant subvariants in structure efficiently. We demonstrate this with 2D shape detection, showing incremental learning on MNIST without overwriting knowledge and creating compact, comprehensible representations. These results offer a promising step toward a transparent, continually learning alternative to traditional neural networks for visual processing.
Agential AI for Integrated Continual Learning, Deliberative Behavior, and Comprehensible Models
Jan 28, 2025



Contemporary machine learning paradigm excels in statistical data analysis, solving problems that classical AI couldn't. However, it faces key limitations, such as a lack of integration with planning, incomprehensible internal structure, and inability to learn continually. We present the initial design for an AI system, Agential AI (AAI), in principle operating independently or on top of statistical methods, designed to overcome these issues. AAI's core is a learning method that models temporal dynamics with guarantees of completeness, minimality, and continual learning, using component-level variation and selection to learn the structure of the environment. It integrates this with a behavior algorithm that plans on a learned model and encapsulates high-level behavior patterns. Preliminary experiments on a simple environment show AAI's effectiveness and potential.
Directed Structural Adaptation to Overcome Statistical Conflicts and Enable Continual Learning
Dec 05, 2024Adaptive networks today rely on overparameterized fixed topologies that cannot break through the statistical conflicts they encounter in the data they are exposed to, and are prone to "catastrophic forgetting" as the network attempts to reuse the existing structures to learn new task. We propose a structural adaptation method, DIRAD, that can complexify as needed and in a directed manner without being limited by statistical conflicts within a dataset. We then extend this method and present the PREVAL framework, designed to prevent "catastrophic forgetting" in continual learning by detection of new data and assigning encountered data to suitable models adapted to process them, without needing task labels anywhere in the workflow. We show the reliability of the DIRAD in growing a network with high performance and orders-of-magnitude simpler than fixed topology networks; and demonstrate the proof-of-concept operation of PREVAL, in which continual adaptation to new tasks is observed while being able to detect and discern previously-encountered tasks.