 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Nuance Matters: Probing Epistemic Consistency in Causal Reasoning
Aug 27, 2024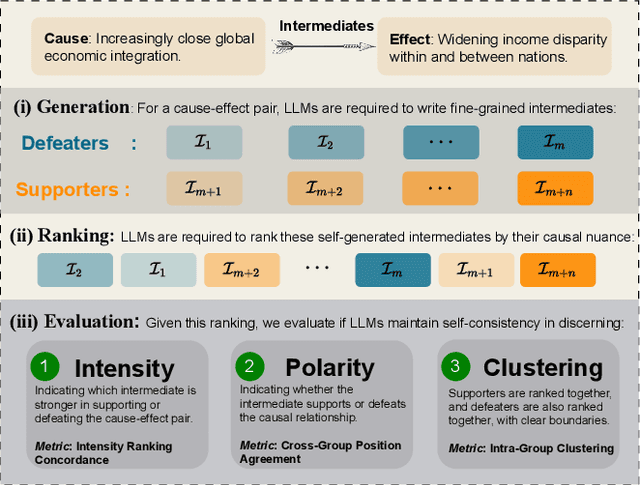
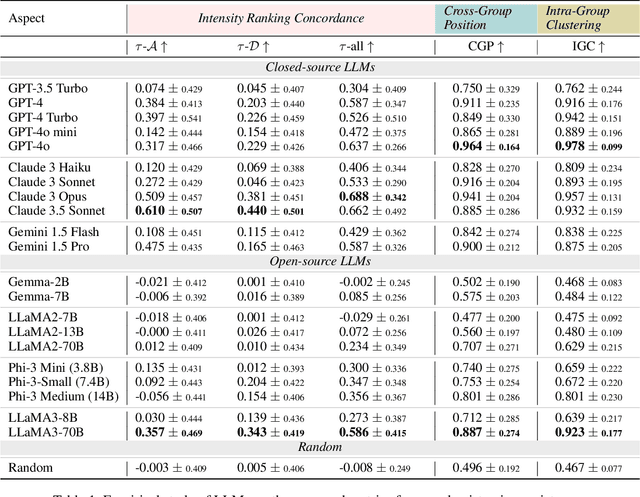
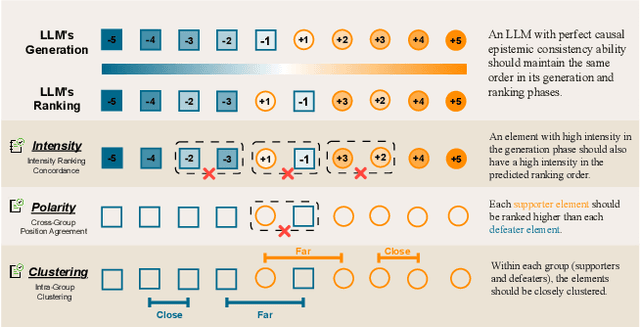
To address this gap, our study introduces the concept of causal epistemic consistency, which focuses on the self-consistency of Large Language Models (LLMs) in differentiating intermediates with nuanced differences in causal reasoning. We propose a suite of novel metrics -- intensity ranking concordance, cross-group position agreement, and intra-group clustering -- to evaluate LLMs on this front. Through extensive empirical studies on 21 high-profile LLMs, including GPT-4, Claude3, and LLaMA3-70B, we have favoring evidence that current models struggle to maintain epistemic consistency in identifying the polarity and intensity of intermediates in causal reasoning. Additionally, we explore the potential of using internal token probabilities as an auxiliary tool to maintain causal epistemic consistency. In summary, our study bridges a critical gap in AI research by investigating the self-consistency over fine-grained intermediates involved in causal reasoning.
A Logical Fallacy-Informed Framework for Argument Generation
Aug 07, 2024

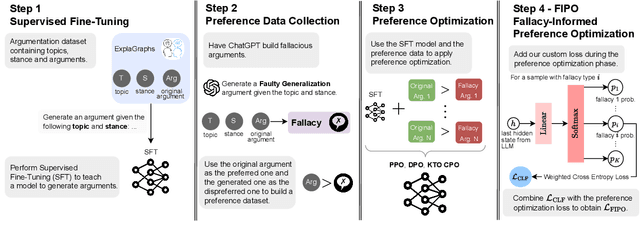
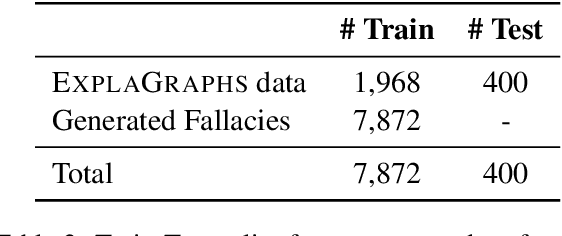
Despite the remarkable performance of Large Language Models (LLMs), they still struggle with generating logically sound arguments, resulting in potential risks such as spreading misinformation. An important factor contributing to LLMs' suboptimal performance in generating coherent arguments is their oversight of logical fallacies. To address this issue, we introduce FIPO, a fallacy-informed framework that leverages preference optimization methods to steer LLMs toward logically sound arguments. FIPO includes a classification loss, to capture the fine-grained information on fallacy categories. Our results on argumentation datasets show that our method reduces the fallacy errors by up to 17.5%. Furthermore, our human evaluation results indicate that the quality of the generated arguments by our method significantly outperforms the fine-tuned baselines, as well as prior preference optimization methods, such as DPO. These findings highlight the importance of ensuring models are aware of logical fallacies for effective argument generation.
Understanding Revision Behavior in Adaptive Writing Support Systems for Education
Jun 17, 2023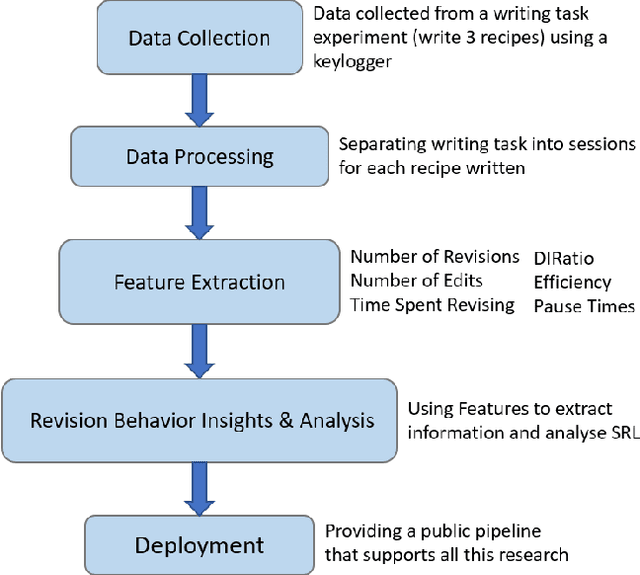



Revision behavior in adaptive writing support systems is an important and relatively new area of research that can improve the design and effectiveness of these tools, and promote students' self-regulated learning (SRL). Understanding how these tools are used is key to improving them to better support learners in their writing and learning processes. In this paper, we present a novel pipeline with insights into the revision behavior of students at scale. We leverage a data set of two groups using an adaptive writing support tool in an educational setting. With our novel pipeline, we show that the tool was effective in promoting revision among the learners. Depending on the writing feedback, we were able to analyze different strategies of learners when revising their texts, we found that users of the exemplary case improved over time and that females tend to be more efficient. Our research contributes a pipeline for measuring SRL behaviors at scale in writing tasks (i.e., engagement or revision behavior) and informs the design of future adaptive writing support systems for education, with the goal of enhancing their effectiveness in supporting student writing. The source code is available at https://github.com/lucamouchel/Understanding-Revision-Behavior.