 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiteLLM: An Agentic Platform for Trustworthy Scientific Reference Discovery
Feb 26, 2026Large language models (LLMs) have created new opportunities to enhance the efficiency of scholarly activities; however, challenges persist in the ethical deployment of AI assistance, including (1) the trustworthiness of AI-generated content, (2) preservation of academic integrity and intellectual property, and (3) protection of information privacy. In this work, we present CiteLLM, a specialized agentic platform designed to enable trustworthy reference discovery for grounding author-drafted claims and statements. The system introduces a novel interaction paradigm by embedding LLM utilities directly within the LaTeX editor environment, ensuring a seamless user experience and no data transmission outside the local system. To guarantee hallucination-free references, we employ dynamic discipline-aware routing to retrieve candidates exclusively from trusted web-based academic repositories, while leveraging LLMs solely for generating context-aware search queries, ranking candidates by relevance, and validating and explaining support through paragraph-level semantic matching and an integrated chatbot. Evaluation results demonstrate the superior performance of the proposed system in returning valid and highly usable references.
MixAR: Mixture Autoregressive Image Generation
Nov 15, 2025Autoregressive (AR) approaches, which represent images as sequences of discrete tokens from a finite codebook, have achieved remarkable success in image generation. However, the quantization process and the limited codebook size inevitably discard fine-grained information, placing bottlenecks on fidelity. Motivated by this limitation, recent studies have explored autoregressive modeling in continuous latent spaces, which offers higher generation quality. Yet, unlike discrete tokens constrained by a fixed codebook, continuous representations lie in a vast and unstructured space, posing significant challenges for efficient autoregressive modeling. To address these challenges, we introduce MixAR, a novel framework that leverages mixture training paradigms to inject discrete tokens as prior guidance for continuous AR modeling. MixAR is a factorized formulation that leverages discrete tokens as prior guidance for continuous autoregressive prediction. We investigate several discrete-continuous mixture strategies, including self-attention (DC-SA), cross-attention (DC-CA), and a simple approach (DC-Mix) that replaces homogeneous mask tokens with informative discrete counterparts. Moreover, to bridge the gap between ground-truth training tokens and inference tokens produced by the pre-trained AR model, we propose Training-Inference Mixture (TI-Mix) to achieve consistent training and generation distributions. In our experiments, we demonstrate a favorable balance of the DC-Mix strategy between computational efficiency and generation fidelity, and consistent improvement of TI-Mix.
Chimera: Diagnosing Shortcut Learning in Visual-Language Understanding
Sep 26, 2025Diagrams convey symbolic information in a visual format rather than a linear stream of words, making them especially challenging for AI models to process. While recent evaluations suggest that vision-language models (VLMs) perform well on diagram-related benchmarks, their reliance on knowledge, reasoning, or modality shortcuts raises concerns about whether they genuinely understand and reason over diagrams. To address this gap, we introduce Chimera, a comprehensive test suite comprising 7,500 high-quality diagrams sourced from Wikipedia; each diagram is annotated with its symbolic content represented by semantic triples along with multi-level questions designed to assess four fundamental aspects of diagram comprehension: entity recognition, relation understanding, knowledge grounding, and visual reasoning. We use Chimera to measure the presence of three types of shortcuts in visual question answering: (1) the visual-memorization shortcut, where VLMs rely on memorized visual patterns; (2) the knowledge-recall shortcut, where models leverage memorized factual knowledge instead of interpreting the diagram; and (3) the Clever-Hans shortcut, where models exploit superficial language patterns or priors without true comprehension. We evaluate 15 open-source VLMs from 7 model families on Chimera and find that their seemingly strong performance largely stems from shortcut behaviors: visual-memorization shortcuts have slight impact, knowledge-recall shortcuts play a moderate role, and Clever-Hans shortcuts contribute significantly. These findings expose critical limitations in current VLMs and underscore the need for more robust evaluation protocols that benchmark genuine comprehension of complex visual inputs (e.g., diagrams) rather than question-answering shortcuts.
Unraveling Misinformation Propagation in LLM Reasoning
May 24, 2025



Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning, positioning them as promising tools for supporting human problem-solving. However, what happens when their performance is affected by misinformation, i.e., incorrect inputs introduced by users due to oversights or gaps in knowledge? Such misinformation is prevalent in real-world interactions with LLMs, yet how it propagates within LLMs' reasoning process remains underexplored. Focusing on mathematical reasoning, we present a comprehensive analysis of how misinformation affects intermediate reasoning steps and final answers. We also examine how effectively LLMs can correct misinformation when explicitly instructed to do so. Even with explicit instructions, LLMs succeed less than half the time in rectifying misinformation, despite possessing correct internal knowledge, leading to significant accuracy drops (10.02% - 72.20%). Further analysis shows that applying factual corrections early in the reasoning process most effectively reduces misinformation propagation, and fine-tuning on synthesized data with early-stage corrections significantly improves reasoning factuality. Our work offers a practical approach to mitigating misinformation propagation.
Nuance Matters: Probing Epistemic Consistency in Causal Reasoning
Aug 27, 2024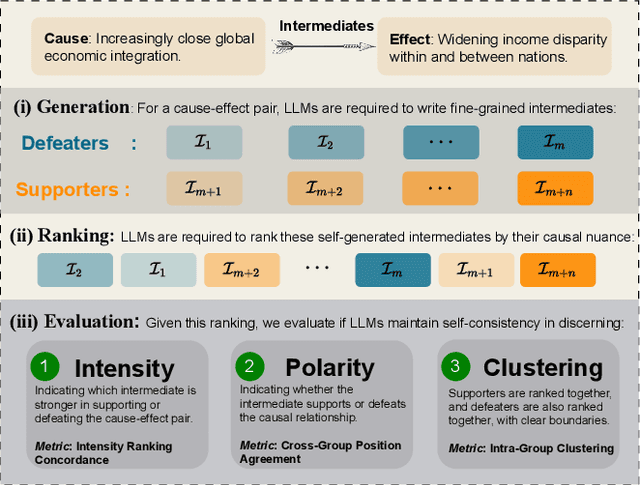
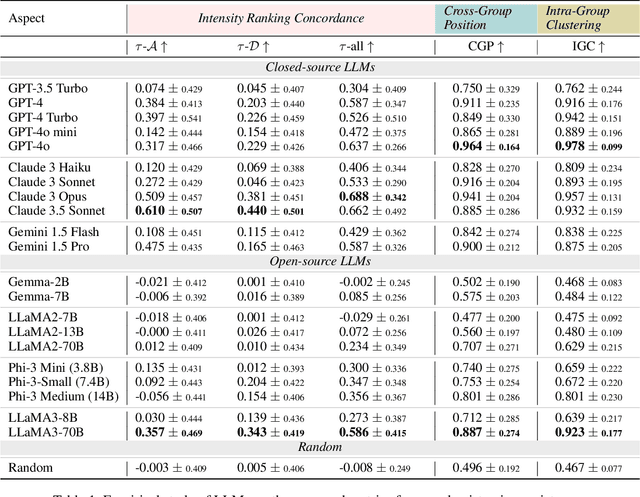
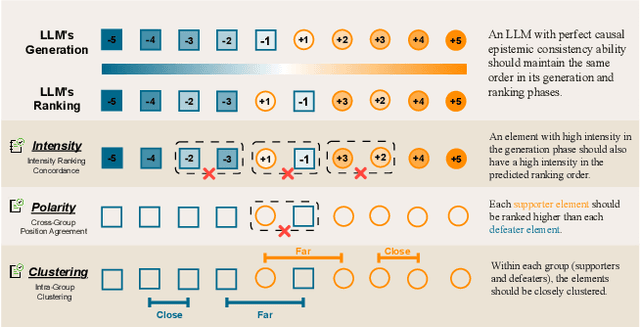
To address this gap, our study introduces the concept of causal epistemic consistency, which focuses on the self-consistency of Large Language Models (LLMs) in differentiating intermediates with nuanced differences in causal reasoning. We propose a suite of novel metrics -- intensity ranking concordance, cross-group position agreement, and intra-group clustering -- to evaluate LLMs on this front. Through extensive empirical studies on 21 high-profile LLMs, including GPT-4, Claude3, and LLaMA3-70B, we have favoring evidence that current models struggle to maintain epistemic consistency in identifying the polarity and intensity of intermediates in causal reasoning. Additionally, we explore the potential of using internal token probabilities as an auxiliary tool to maintain causal epistemic consistency. In summary, our study bridges a critical gap in AI research by investigating the self-consistency over fine-grained intermediates involved in causal reasoning.
A Logical Fallacy-Informed Framework for Argument Generation
Aug 07, 2024

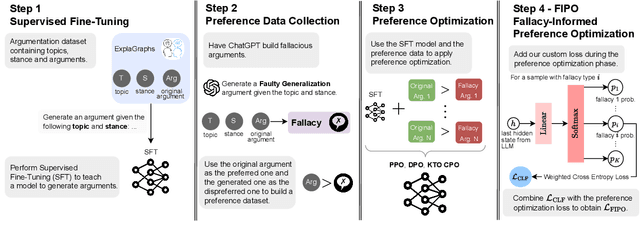
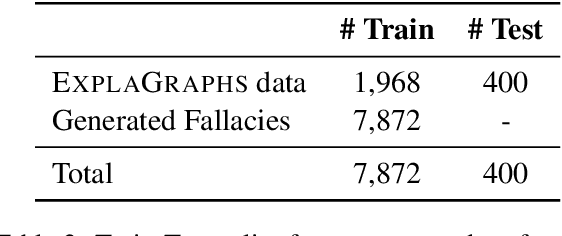
Despite the remarkable performance of Large Language Models (LLMs), they still struggle with generating logically sound arguments, resulting in potential risks such as spreading misinformation. An important factor contributing to LLMs' suboptimal performance in generating coherent arguments is their oversight of logical fallacies. To address this issue, we introduce FIPO, a fallacy-informed framework that leverages preference optimization methods to steer LLMs toward logically sound arguments. FIPO includes a classification loss, to capture the fine-grained information on fallacy categories. Our results on argumentation datasets show that our method reduces the fallacy errors by up to 17.5%. Furthermore, our human evaluation results indicate that the quality of the generated arguments by our method significantly outperforms the fine-tuned baselines, as well as prior preference optimization methods, such as DPO. These findings highlight the importance of ensuring models are aware of logical fallacies for effective argument generation.
The Odyssey of Commonsense Causality: From Foundational Benchmarks to Cutting-Edge Reasoning
Jun 27, 2024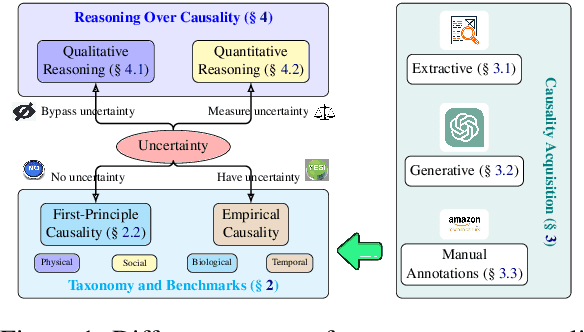
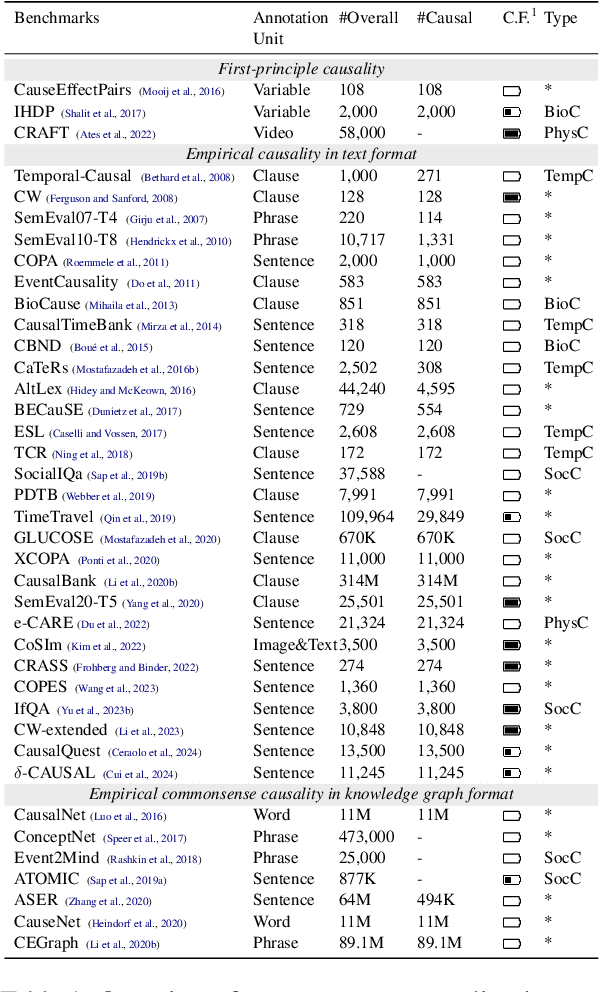
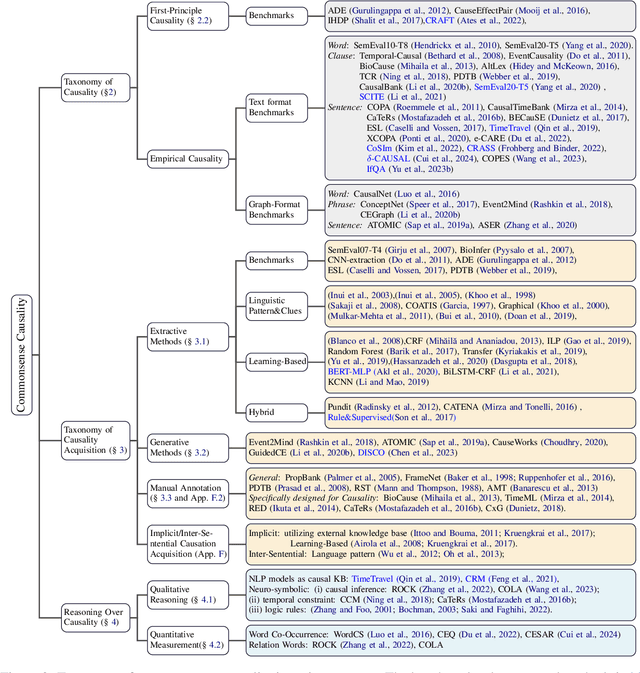

Understanding commonsense causality is a unique mark of intelligence for humans. It helps people understand the principles of the real world better and benefits the decision-making process related to causation. For instance, commonsense causality is crucial in judging whether a defendant's action causes the plaintiff's loss in determining legal liability. Despite its significance, a systematic exploration of this topic is notably lacking. Our comprehensive survey bridges this gap by focusing on taxonomies, benchmarks, acquisition methods, qualitative reasoning, and quantitative measurements in commonsense causality, synthesizing insights from over 200 representative articles. Our work aims to provide a systematic overview, update scholars on recent advancements, provide a pragmatic guide for beginners, and highlight promising future research directions in this vital field.
δ-CAUSAL: Exploring Defeasibility in Causal Reasoning
Jan 06, 2024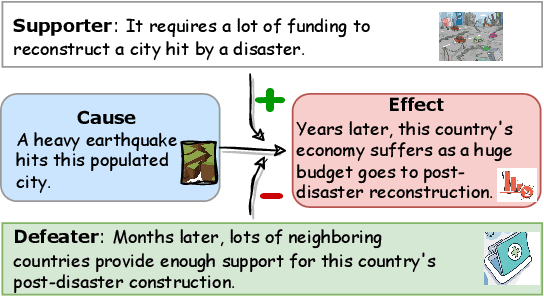

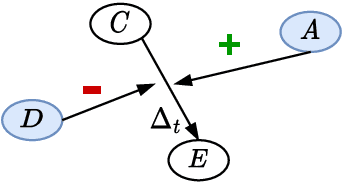

Defeasibility in causal reasoning implies that the causal relationship between cause and effect can be strengthened or weakened. Namely, the causal strength between cause and effect should increase or decrease with the incorporation of strengthening arguments (supporters) or weakening arguments (defeaters), respectively. However, existing works ignore defeasibility in causal reasoning and fail to evaluate existing causal strength metrics in defeasible settings. In this work, we present {\delta}-CAUSAL, the first benchmark dataset for studying defeasibility in causal reasoning. {\delta}-CAUSAL includes around 11K events spanning ten domains, featuring defeasible causality pairs, i.e., cause-effect pairs accompanied by supporters and defeaters. We further show current causal strength metrics fail to reflect the change of causal strength with the incorporation of supporters or defeaters in {\delta}-CAUSAL. To this end, we propose CESAR (Causal Embedding aSsociation with Attention Rating), a metric that measures causal strength based on token-level causal relationships. CESAR achieves a significant 69.7% relative improvement over existing metrics, increasing from 47.2% to 80.1% in capturing the causal strength change brought by supporters and defeaters. We further demonstrate even Large Language Models (LLMs) like GPT-3.5 still lag 4.5 and 10.7 points behind humans in generating supporters and defeaters, emphasizing the challenge posed by {\delta}-CAUSAL.
Towards Zero-Shot Personalized Table-to-Text Generation with Contrastive Persona Distillation
Apr 18, 2023Existing neural methods have shown great potentials towards generating informative text from structured tabular data as well as maintaining high content fidelity. However, few of them shed light on generating personalized expressions, which often requires well-aligned persona-table-text datasets that are difficult to obtain. To overcome these obstacles, we explore personalized table-to-text generation under a zero-shot setting, by assuming no well-aligned persona-table-text triples are required during training. To this end, we firstly collect a set of unpaired persona information and then propose a semi-supervised approach with contrastive persona distillation (S2P-CPD) to generate personalized context. Specifically, tabular data and persona information are firstly represented as latent variables separately. Then, we devise a latent space fusion technique to distill persona information into the table representation. Besides, a contrastive-based discriminator is employed to guarantee the style consistency between the generated context and its corresponding persona. Experimental results on two benchmarks demonstrate S2P-CPD's ability on keeping both content fidelity and personalized expressions.
GGP: A Graph-based Grouping Planner for Explicit Control of Long Text Generation
Aug 18, 2021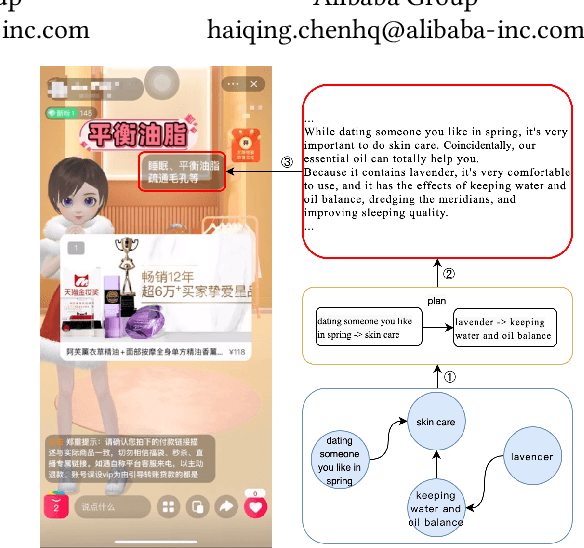

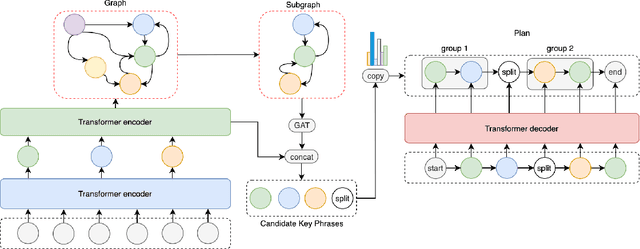
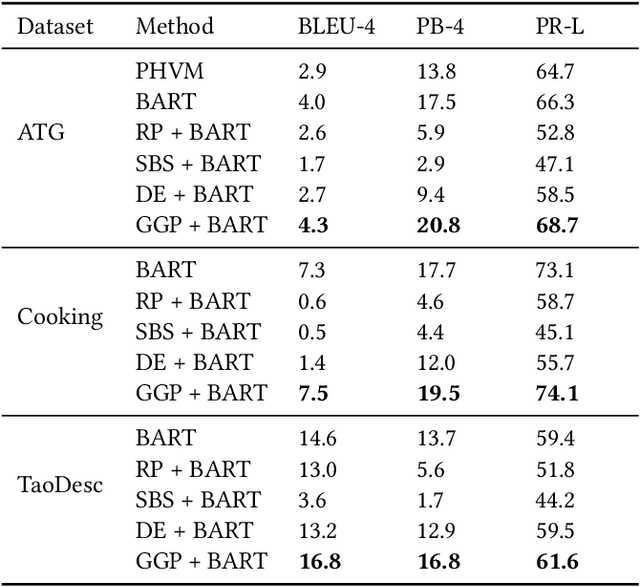
Existing data-driven methods can well handle short text generation. However, when applied to the long-text generation scenarios such as story generation or advertising text generation in the commercial scenario, these methods may generate illogical and uncontrollable texts. To address these aforementioned issues, we propose a graph-based grouping planner(GGP) following the idea of first-plan-then-generate. Specifically, given a collection of key phrases, GGP firstly encodes these phrases into an instance-level sequential representation and a corpus-level graph-based representation separately. With these two synergic representations, we then regroup these phrases into a fine-grained plan, based on which we generate the final long text. We conduct our experiments on three long text generation datasets and the experimental results reveal that GGP significantly outperforms baselines, which proves that GGP can control the long text generation by knowing how to say and in what order.