 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylized Data-to-Text Generation: A Case Study in the E-Commerce Domain
May 05, 2023



Existing data-to-text generation efforts mainly focus on generating a coherent text from non-linguistic input data, such as tables and attribute-value pairs, but overlook that different application scenarios may require texts of different styles. Inspired by this, we define a new task, namely stylized data-to-text generation, whose aim is to generate coherent text for the given non-linguistic data according to a specific style. This task is non-trivial, due to three challenges: the logic of the generated text, unstructured style reference, and biased training samples. To address these challenges, we propose a novel stylized data-to-text generation model, named StyleD2T, comprising three components: logic planning-enhanced data embedding, mask-based style embedding, and unbiased stylized text generation. In the first component, we introduce a graph-guided logic planner for attribute organization to ensure the logic of generated text. In the second component, we devise feature-level mask-based style embedding to extract the essential style signal from the given unstructured style reference. In the last one, pseudo triplet augmentation is utilized to achieve unbiased text generation, and a multi-condition based confidence assignment function is designed to ensure the quality of pseudo samples. Extensive experiments on a newly collected dataset from Taobao have been conducted, and the results show the superiority of our model over existing methods.
Towards Zero-Shot Personalized Table-to-Text Generation with Contrastive Persona Distillation
Apr 18, 2023Existing neural methods have shown great potentials towards generating informative text from structured tabular data as well as maintaining high content fidelity. However, few of them shed light on generating personalized expressions, which often requires well-aligned persona-table-text datasets that are difficult to obtain. To overcome these obstacles, we explore personalized table-to-text generation under a zero-shot setting, by assuming no well-aligned persona-table-text triples are required during training. To this end, we firstly collect a set of unpaired persona information and then propose a semi-supervised approach with contrastive persona distillation (S2P-CPD) to generate personalized context. Specifically, tabular data and persona information are firstly represented as latent variables separately. Then, we devise a latent space fusion technique to distill persona information into the table representation. Besides, a contrastive-based discriminator is employed to guarantee the style consistency between the generated context and its corresponding persona. Experimental results on two benchmarks demonstrate S2P-CPD's ability on keeping both content fidelity and personalized expressions.
GGP: A Graph-based Grouping Planner for Explicit Control of Long Text Generation
Aug 18, 2021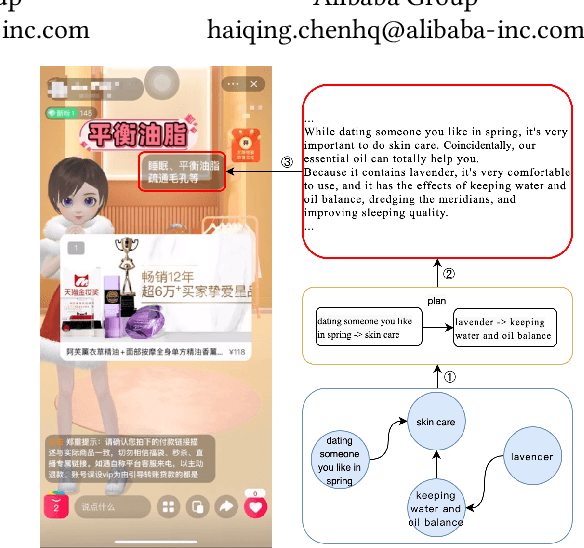

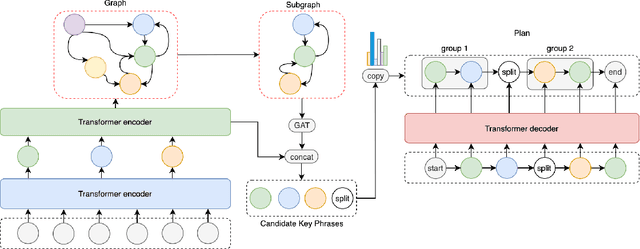
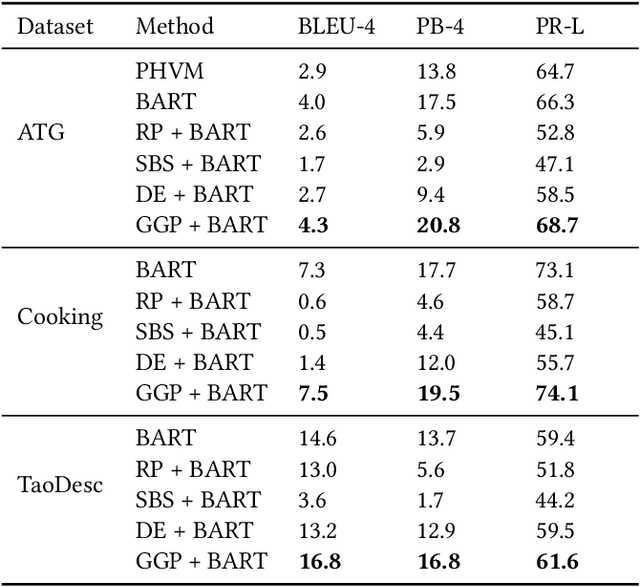
Existing data-driven methods can well handle short text generation. However, when applied to the long-text generation scenarios such as story generation or advertising text generation in the commercial scenario, these methods may generate illogical and uncontrollable texts. To address these aforementioned issues, we propose a graph-based grouping planner(GGP) following the idea of first-plan-then-generate. Specifically, given a collection of key phrases, GGP firstly encodes these phrases into an instance-level sequential representation and a corpus-level graph-based representation separately. With these two synergic representations, we then regroup these phrases into a fine-grained plan, based on which we generate the final long text. We conduct our experiments on three long text generation datasets and the experimental results reveal that GGP significantly outperforms baselines, which proves that GGP can control the long text generation by knowing how to say and in what order.
SPMoE: Generate Multiple Pattern-Aware Outputs with Sparse Pattern Mixture of Experts
Aug 18, 2021Many generation tasks follow a one-to-many mapping relationship: each input could be associated with multiple outputs. Existing methods like Conditional Variational AutoEncoder(CVAE) employ a latent variable to model this one-to-many relationship. However, this high-dimensional and dense latent variable lacks explainability and usually leads to poor and uncontrollable generations. In this paper, we innovatively introduce the linguistic concept of pattern to decompose the one-to-many mapping into multiple one-to-one mappings and further propose a model named Sparse Pattern Mixture of Experts(SPMoE). Each one-to-one mapping is associated with a conditional generation pattern and is modeled with an expert in SPMoE. To ensure each language pattern can be exclusively handled with an expert model for better explainability and diversity, a sparse mechanism is employed to coordinate all the expert models in SPMoE. We assess the performance of our SPMoE on the paraphrase generation task and the experiment results prove that SPMoE can achieve a good balance in terms of quality, pattern-level diversity, and corpus-level diversity.