 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASEIN: Cascading Explicit and Implicit Control for Fine-grained Emotion Intensity Regulation
Jun 27, 2023
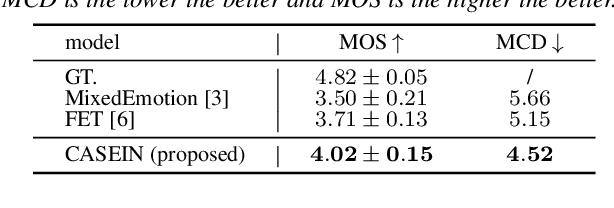
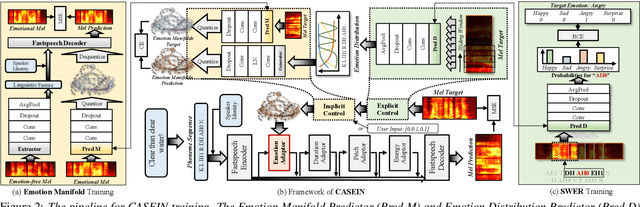

Existing fine-grained intensity regulation methods rely on explicit control through predicted emotion probabilities. However, these high-level semantic probabilities are often inaccurate and unsmooth at the phoneme level, leading to bias in learning. Especially when we attempt to mix multiple emotion intensities for specific phonemes, resulting in markedly reduced controllability and naturalness of the synthesis. To address this issue, we propose the CAScaded Explicit and Implicit coNtrol framework (CASEIN), which leverages accurate disentanglement of emotion manifolds from the reference speech to learn the implicit representation at a lower semantic level. This representation bridges the semantical gap between explicit probabilities and the synthesis model, reducing bias in learning. In experiments, our CASEIN surpasses existing methods in both controllability and naturalness. Notably, we are the first to achieve fine-grained control over the mixed intensity of multiple emotions.
Towards Zero-Shot Personalized Table-to-Text Generation with Contrastive Persona Distillation
Apr 18, 2023Existing neural methods have shown great potentials towards generating informative text from structured tabular data as well as maintaining high content fidelity. However, few of them shed light on generating personalized expressions, which often requires well-aligned persona-table-text datasets that are difficult to obtain. To overcome these obstacles, we explore personalized table-to-text generation under a zero-shot setting, by assuming no well-aligned persona-table-text triples are required during training. To this end, we firstly collect a set of unpaired persona information and then propose a semi-supervised approach with contrastive persona distillation (S2P-CPD) to generate personalized context. Specifically, tabular data and persona information are firstly represented as latent variables separately. Then, we devise a latent space fusion technique to distill persona information into the table representation. Besides, a contrastive-based discriminator is employed to guarantee the style consistency between the generated context and its corresponding persona. Experimental results on two benchmarks demonstrate S2P-CPD's ability on keeping both content fidelity and personalized expressions.
Knowledge Distillation of Transformer-based Language Models Revisited
Jun 30, 2022
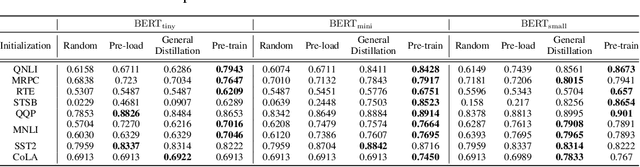
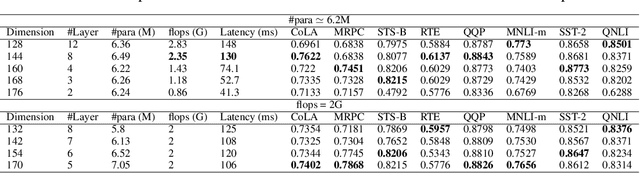
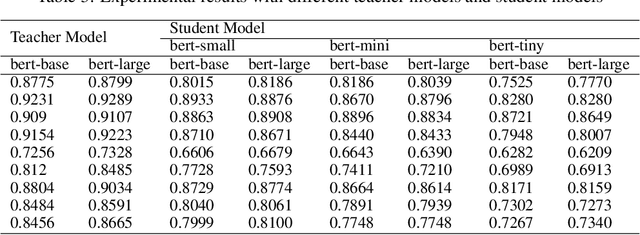
In the past few years, transformer-based pre-trained language models have achieved astounding success in both industry and academia. However, the large model size and high run-time latency are serious impediments to applying them in practice, especially on mobile phones and Internet of Things (IoT) devices. To compress the model, considerable literature has grown up around the theme of knowledge distillation (KD) recently. Nevertheless, how KD works in transformer-based models is still unclear. We tease apart the components of KD and propose a unified KD framework. Through the framework, systematic and extensive experiments that spent over 23,000 GPU hours render a comprehensive analysis from the perspectives of knowledge types, matching strategies, width-depth trade-off, initialization, model size, etc. Our empirical results shed light on the distillation in the pre-train language model and with relative significant improvement over previous state-of-the-arts(SOTA). Finally, we provide a best-practice guideline for the KD in transformer-based models.
GGP: A Graph-based Grouping Planner for Explicit Control of Long Text Generation
Aug 18, 2021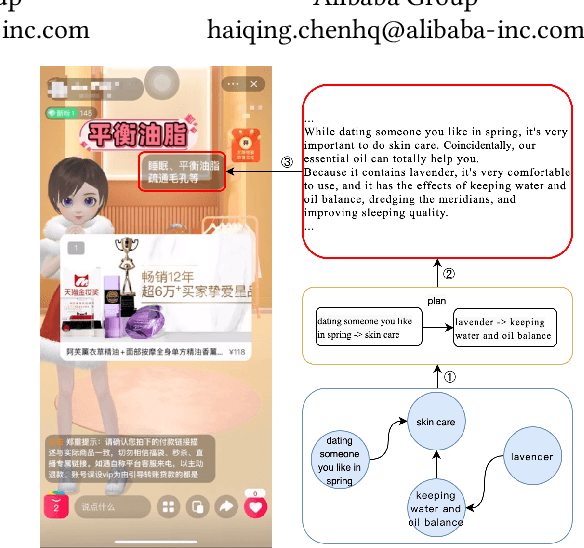

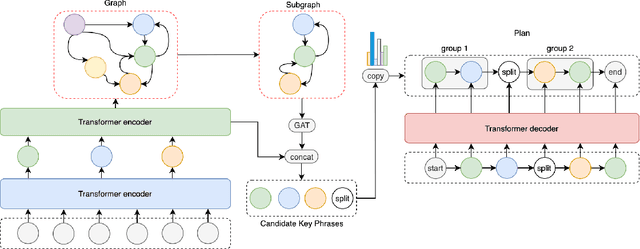
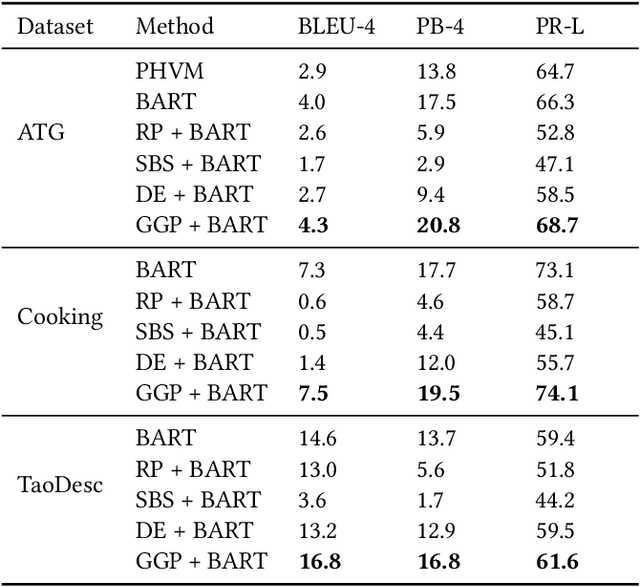
Existing data-driven methods can well handle short text generation. However, when applied to the long-text generation scenarios such as story generation or advertising text generation in the commercial scenario, these methods may generate illogical and uncontrollable texts. To address these aforementioned issues, we propose a graph-based grouping planner(GGP) following the idea of first-plan-then-generate. Specifically, given a collection of key phrases, GGP firstly encodes these phrases into an instance-level sequential representation and a corpus-level graph-based representation separately. With these two synergic representations, we then regroup these phrases into a fine-grained plan, based on which we generate the final long text. We conduct our experiments on three long text generation datasets and the experimental results reveal that GGP significantly outperforms baselines, which proves that GGP can control the long text generation by knowing how to say and in what order.
SPMoE: Generate Multiple Pattern-Aware Outputs with Sparse Pattern Mixture of Experts
Aug 18, 2021Many generation tasks follow a one-to-many mapping relationship: each input could be associated with multiple outputs. Existing methods like Conditional Variational AutoEncoder(CVAE) employ a latent variable to model this one-to-many relationship. However, this high-dimensional and dense latent variable lacks explainability and usually leads to poor and uncontrollable generations. In this paper, we innovatively introduce the linguistic concept of pattern to decompose the one-to-many mapping into multiple one-to-one mappings and further propose a model named Sparse Pattern Mixture of Experts(SPMoE). Each one-to-one mapping is associated with a conditional generation pattern and is modeled with an expert in SPMoE. To ensure each language pattern can be exclusively handled with an expert model for better explainability and diversity, a sparse mechanism is employed to coordinate all the expert models in SPMoE. We assess the performance of our SPMoE on the paraphrase generation task and the experiment results prove that SPMoE can achieve a good balance in terms of quality, pattern-level diversity, and corpus-level diversity.
An Emotion-controlled Dialog Response Generation Model with Dynamic Vocabulary
Mar 04, 2021
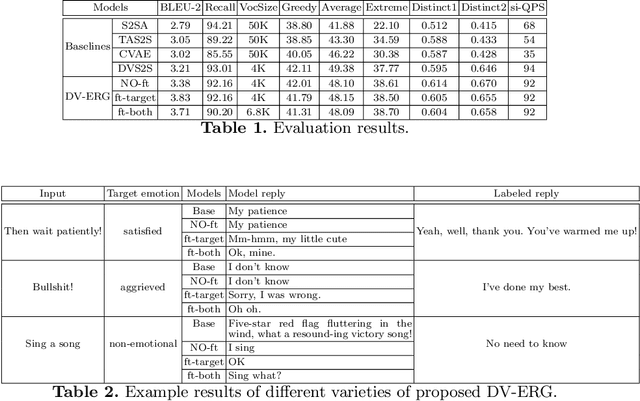
In response generation task, proper sentimental expressions can obviously improve the human-like level of the responses. However, for real application in online systems, high QPS (queries per second, an indicator of the flow capacity of on-line systems) is required, and a dynamic vocabulary mechanism has been proved available in improving speed of generative models. In this paper, we proposed an emotion-controlled dialog response generation model based on the dynamic vocabulary mechanism, and the experimental results show the benefit of this model.
OneStop QAMaker: Extract Question-Answer Pairs from Text in a One-Stop Approach
Feb 24, 2021Large-scale question-answer (QA) pairs are critical for advancing research areas like machine reading comprehension and question answering. To construct QA pairs from documents requires determining how to ask a question and what is the corresponding answer. Existing methods for QA pair generation usually follow a pipeline approach. Namely, they first choose the most likely candidate answer span and then generate the answer-specific question. This pipeline approach, however, is undesired in mining the most appropriate QA pairs from documents since it ignores the connection between question generation and answer extraction, which may lead to incompatible QA pair generation, i.e., the selected answer span is inappropriate for question generation. However, for human annotators, we take the whole QA pair into account and consider the compatibility between question and answer. Inspired by such motivation, instead of the conventional pipeline approach, we propose a model named OneStop generate QA pairs from documents in a one-stop approach. Specifically, questions and their corresponding answer span is extracted simultaneously and the process of question generation and answer extraction mutually affect each other. Additionally, OneStop is much more efficient to be trained and deployed in industrial scenarios since it involves only one model to solve the complex QA generation task. We conduct comprehensive experiments on three large-scale machine reading comprehension datasets: SQuAD, NewsQA, and DuReader. The experimental results demonstrate that our OneStop model outperforms the baselines significantly regarding the quality of generated questions, quality of generated question-answer pairs, and model efficiency.
Learning to Expand: Reinforced Pseudo-relevance Feedback Selection for Information-seeking Conversations
Nov 25, 2020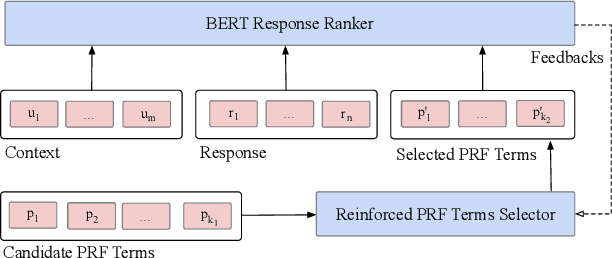
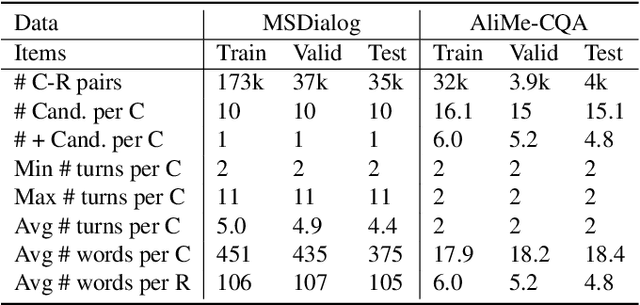
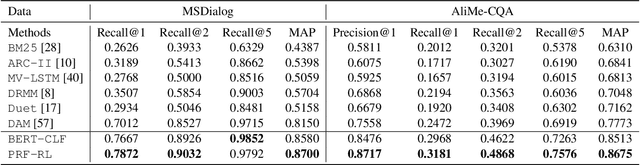
Intelligent personal assistant systems for information-seeking conversations are increasingly popular in real-world applications, especially for e-commerce companies. With the development of research in such conversation systems, the pseudo-relevance feedback (PRF) has demonstrated its effectiveness in incorporating relevance signals from external documents. However, the existing studies are either based on heuristic rules or require heavy manual labeling. In this work, we treat the PRF selection as a learning task and proposed a reinforced learning based method that can be trained in an end-to-end manner without any human annotations. More specifically, we proposed a reinforced selector to extract useful PRF terms to enhance response candidates and a BERT based response ranker to rank the PRF-enhanced responses. The performance of the ranker serves as rewards to guide the selector to extract useful PRF terms, and thus boost the task performance. Extensive experiments on both standard benchmark and commercial datasets show the superiority of our reinforced PRF term selector compared with other potential soft or hard selection methods. Both qualitative case studies and quantitative analysis show that our model can not only select meaningful PRF terms to expand response candidates but also achieve the best results compared with all the baseline methods on a variety of evaluation metrics. We have also deployed our method on online production in an e-commerce company, which shows a significant improvement over the existing online ranking system.
Improving Commonsense Question Answering by Graph-based Iterative Retrieval over Multiple Knowledge Sources
Nov 05, 2020
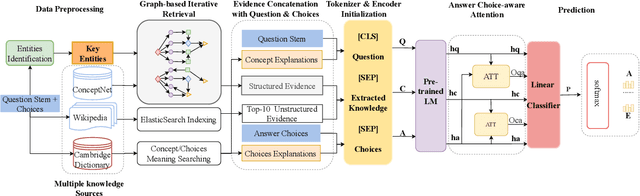
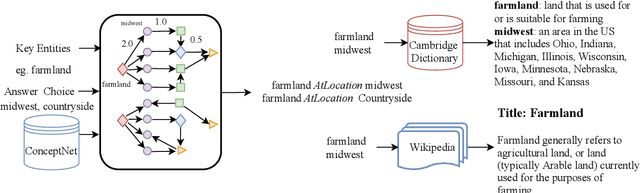

In order to facilitate natural language understanding, the key is to engage commonsense or background knowledge. However, how to engage commonsense effectively in question answering systems is still under exploration in both research academia and industry. In this paper, we propose a novel question-answering method by integrating multiple knowledge sources, i.e. ConceptNet, Wikipedia, and the Cambridge Dictionary, to boost the performance. More concretely, we first introduce a novel graph-based iterative knowledge retrieval module, which iteratively retrieves concepts and entities related to the given question and its choices from multiple knowledge sources. Afterward, we use a pre-trained language model to encode the question, retrieved knowledge and choices, and propose an answer choice-aware attention mechanism to fuse all hidden representations of the previous modules. Finally, the linear classifier for specific tasks is used to predict the answer. Experimental results on the CommonsenseQA dataset show that our method significantly outperforms other competitive methods and achieves the new state-of-the-art. In addition, further ablation studies demonstrate the effectiveness of our graph-based iterative knowledge retrieval module and the answer choice-aware attention module in retrieving and synthesizing background knowledge from multiple knowledge sources.
AliMe KG: Domain Knowledge Graph Construction and Application in E-commerce
Sep 24, 2020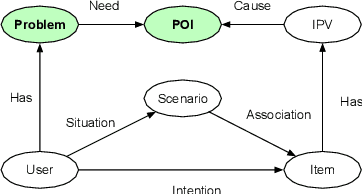
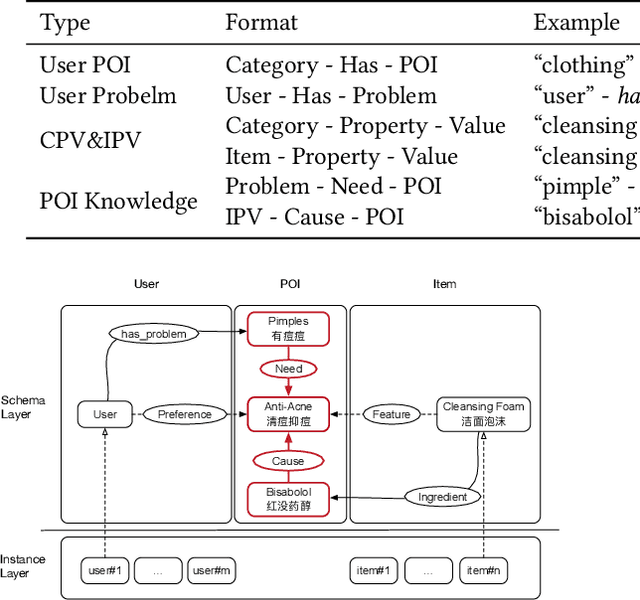
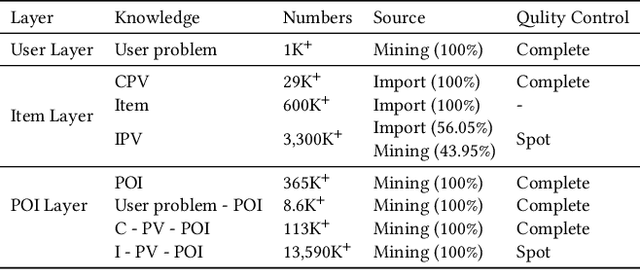
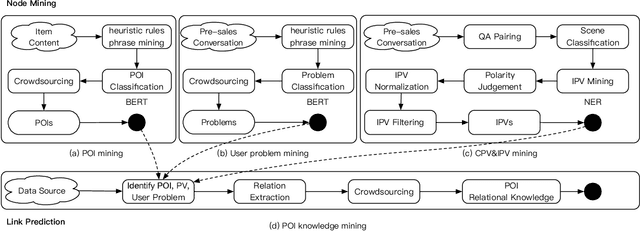
Pre-sales customer service is of importance to E-commerce platforms as it contributes to optimizing customers' buying process. To better serve users, we propose AliMe KG, a domain knowledge graph in E-commerce that captures user problems, points of interests (POI), item information and relations thereof. It helps to understand user needs, answer pre-sales questions and generate explanation texts. We applied AliMe KG to several online business scenarios such as shopping guide, question answering over properties and recommendation reason generation, and gained positive results. In the paper, we systematically introduce how we construct domain knowledge graph from free text, and demonstrate its business value with several applications. Our experience shows that mining structured knowledge from free text in vertical domain is practicable, and can be of substantial value in industrial settings.