 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoleInteract: Evaluating the Social Interaction of Role-Playing Agents
Mar 22, 2024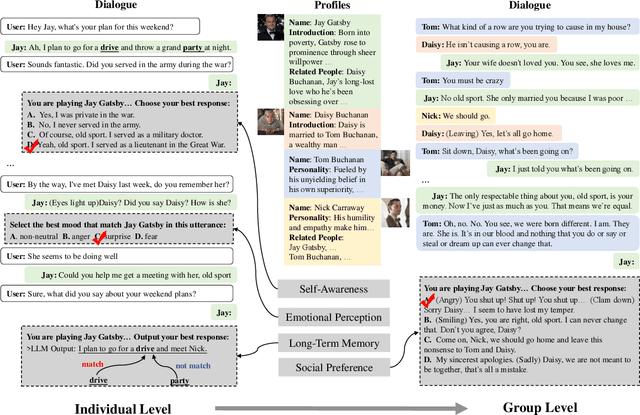
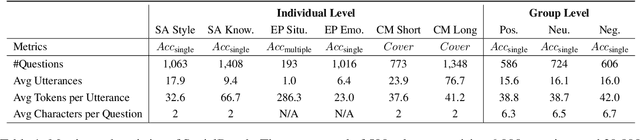
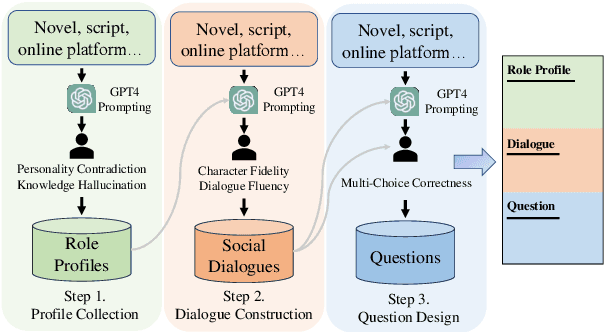
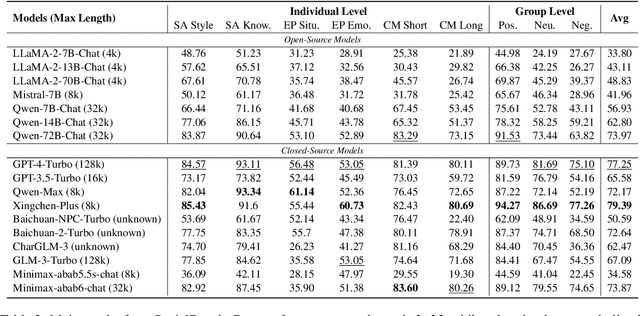
Large language models (LLMs) have advanced the development of various AI conversational agents, including role-playing conversational agents that mimic diverse characters and human behaviors. While prior research has predominantly focused on enhancing the conversational capability, role-specific knowledge, and stylistic attributes of these agents, there has been a noticeable gap in assessing their social intelligence. In this paper, we introduce RoleInteract, the first benchmark designed to systematically evaluate the sociality of role-playing conversational agents at both individual and group levels of social interactions. The benchmark is constructed from a variety of sources and covers a wide range of 500 characters and over 6,000 question prompts and 30,800 multi-turn role-playing utterances. We conduct comprehensive evaluations on this benchmark using mainstream open-source and closed-source LLMs. We find that agents excelling in individual level does not imply their proficiency in group level. Moreover, the behavior of individuals may drift as a result of the influence exerted by other agents within the group. Experimental results on RoleInteract confirm its significance as a testbed for assessing the social interaction of role-playing conversational agents. The benchmark is publicly accessible at https://github.com/X-PLUG/RoleInteract.
Small LLMs Are Weak Tool Learners: A Multi-LLM Agent
Feb 01, 2024Large Language Model (LLM) agents significantly extend the capabilities of standalone LLMs, empowering them to interact with external tools (e.g., APIs, functions) and complete complex tasks in a self-directed fashion. The challenge of tool use demands that LLMs not only understand user queries and generate answers but also excel in task planning, memory management, tool invocation, and result summarization. While traditional approaches focus on training a single LLM with all these capabilities, performance limitations become apparent, particularly with smaller models. Moreover, the entire LLM may require retraining when tools are updated. To overcome these challenges, we propose a novel strategy that decomposes the aforementioned capabilities into a planner, caller, and summarizer. Each component is implemented by a single LLM that focuses on a specific capability and collaborates with other components to accomplish the task. This modular framework facilitates individual updates and the potential use of smaller LLMs for building each capability. To effectively train this framework, we introduce a two-stage training paradigm. First, we fine-tune a backbone LLM on the entire dataset without discriminating sub-tasks, providing the model with a comprehensive understanding of the task. Second, the fine-tuned LLM is used to instantiate the planner, caller, and summarizer respectively, which are continually fine-tuned on respective sub-tasks. Evaluation across various tool-use benchmarks illustrates that our proposed multi-LLM framework surpasses the traditional single-LLM approach, highlighting its efficacy and advantages in tool learning.
Knowledge Distillation for Closed-Source Language Models
Jan 13, 2024Closed-source language models such as GPT-4 have achieved remarkable performance. Many recent studies focus on enhancing the capabilities of smaller models through knowledge distillation from closed-source language models. However, due to the incapability to directly access the weights, hidden states, and output distributions of these closed-source models, the distillation can only be performed by fine-tuning smaller models with data samples generated by closed-source language models, which constrains the effectiveness of knowledge distillation. In this paper, we propose to estimate the output distributions of closed-source language models within a Bayesian estimation framework, involving both prior and posterior estimation. The prior estimation aims to derive a prior distribution by utilizing the corpus generated by closed-source language models, while the posterior estimation employs a proxy model to update the prior distribution and derive a posterior distribution. By leveraging the estimated output distribution of closed-source language models, traditional knowledge distillation can be executed. Experimental results demonstrate that our method surpasses the performance of current models directly fine-tuned on data generated by closed-source language models.
ModelScope-Agent: Building Your Customizable Agent System with Open-source Large Language Models
Sep 02, 2023



Large language models (LLMs) have recently demonstrated remarkable capabilities to comprehend human intentions, engage in reasoning, and design planning-like behavior. To further unleash the power of LLMs to accomplish complex tasks, there is a growing trend to build agent framework that equips LLMs, such as ChatGPT, with tool-use abilities to connect with massive external APIs. In this work, we introduce ModelScope-Agent, a general and customizable agent framework for real-world applications, based on open-source LLMs as controllers. It provides a user-friendly system library, with customizable engine design to support model training on multiple open-source LLMs, while also enabling seamless integration with both model APIs and common APIs in a unified way. To equip the LLMs with tool-use abilities, a comprehensive framework has been proposed spanning over tool-use data collection, tool retrieval, tool registration, memory control, customized model training, and evaluation for practical real-world applications. Finally, we showcase ModelScopeGPT, a real-world intelligent assistant of ModelScope Community based on the ModelScope-Agent framework, which is able to connect open-source LLMs with more than 1000 public AI models and localized community knowledge in ModelScope. The ModelScope-Agent library\footnote{https://github.com/modelscope/modelscope-agent} and online demo\footnote{https://modelscope.cn/studios/damo/ModelScopeGPT/summary} are now publicly available.
ChatPLUG: Open-Domain Generative Dialogue System with Internet-Augmented Instruction Tuning for Digital Human
Apr 28, 2023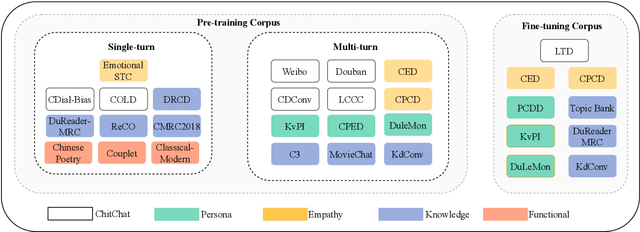

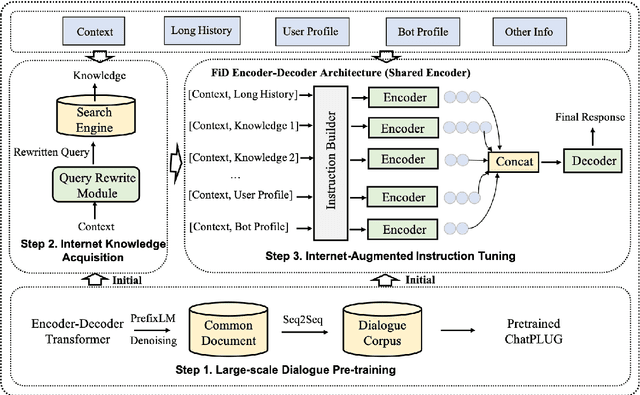
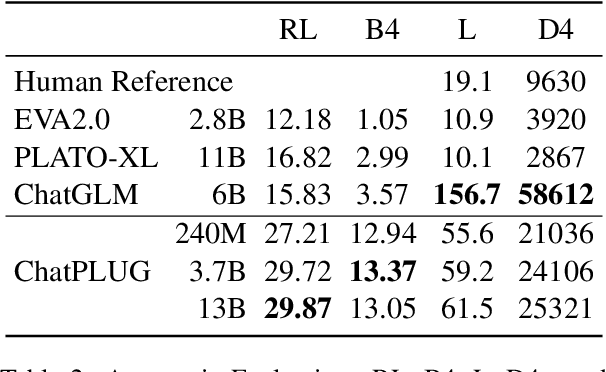
In this paper, we present ChatPLUG, a Chinese open-domain dialogue system for digital human applications that instruction finetunes on a wide range of dialogue tasks in a unified internet-augmented format. Different from other open-domain dialogue models that focus on large-scale pre-training and scaling up model size or dialogue corpus, we aim to build a powerful and practical dialogue system for digital human with diverse skills and good multi-task generalization by internet-augmented instruction tuning. To this end, we first conduct large-scale pre-training on both common document corpus and dialogue data with curriculum learning, so as to inject various world knowledge and dialogue abilities into ChatPLUG. Then, we collect a wide range of dialogue tasks spanning diverse features of knowledge, personality, multi-turn memory, and empathy, on which we further instruction tune \modelname via unified natural language instruction templates. External knowledge from an internet search is also used during instruction finetuning for alleviating the problem of knowledge hallucinations. We show that \modelname outperforms state-of-the-art Chinese dialogue systems on both automatic and human evaluation, and demonstrates strong multi-task generalization on a variety of text understanding and generation tasks. In addition, we deploy \modelname to real-world applications such as Smart Speaker and Instant Message applications with fast inference. Our models and code will be made publicly available on ModelScope~\footnote{\small{https://modelscope.cn/models/damo/ChatPLUG-3.7B}} and Github~\footnote{\small{https://github.com/X-PLUG/ChatPLUG}}.
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Apr 27, 2023



Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022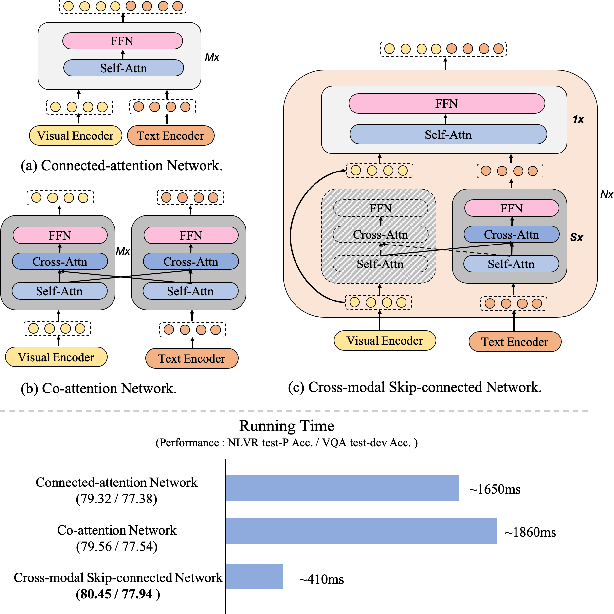
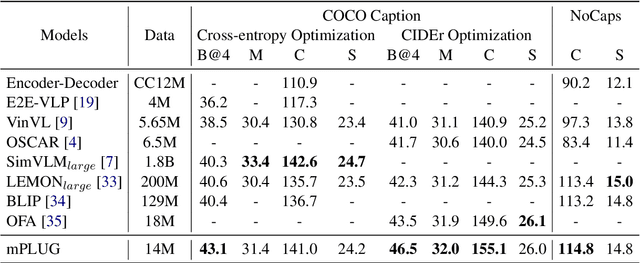
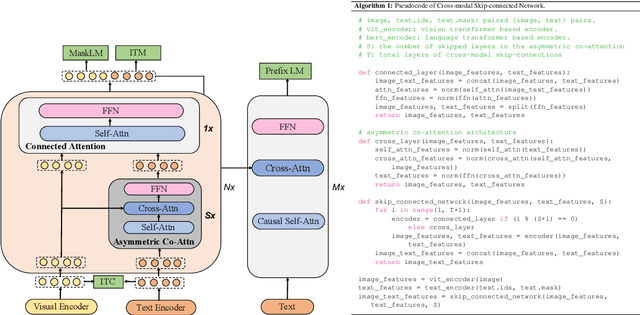

Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
AliMe MKG: A Multi-modal Knowledge Graph for Live-streaming E-commerce
Sep 13, 2021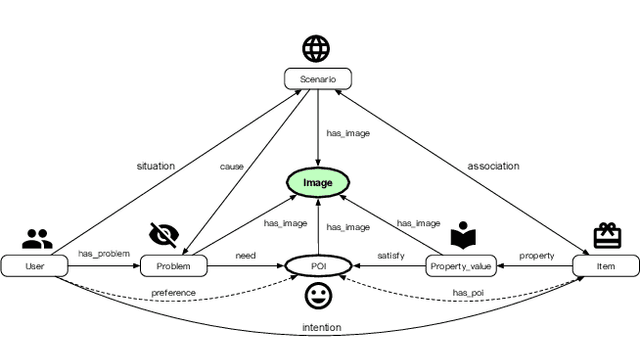
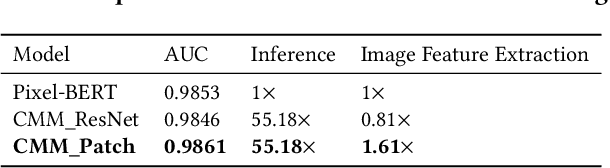
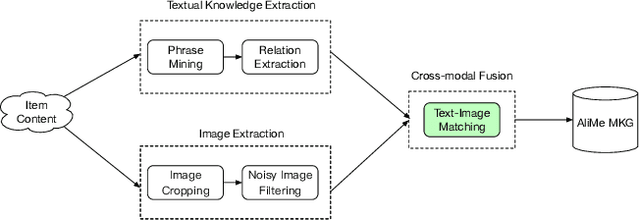
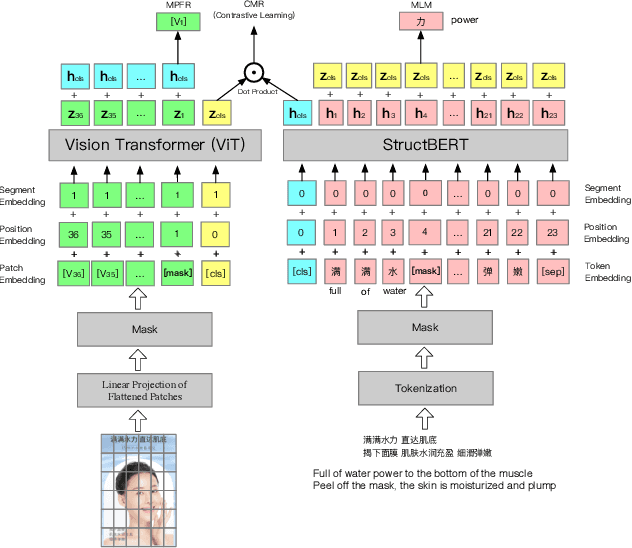
Live streaming is becoming an increasingly popular trend of sales in E-commerce. The core of live-streaming sales is to encourage customers to purchase in an online broadcasting room. To enable customers to better understand a product without jumping out, we propose AliMe MKG, a multi-modal knowledge graph that aims at providing a cognitive profile for products, through which customers are able to seek information about and understand a product. Based on the MKG, we build an online live assistant that highlights product search, product exhibition and question answering, allowing customers to skim over item list, view item details, and ask item-related questions. Our system has been launched online in the Taobao app, and currently serves hundreds of thousands of customers per day.
AliMe KG: Domain Knowledge Graph Construction and Application in E-commerce
Sep 24, 2020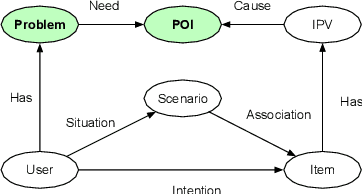
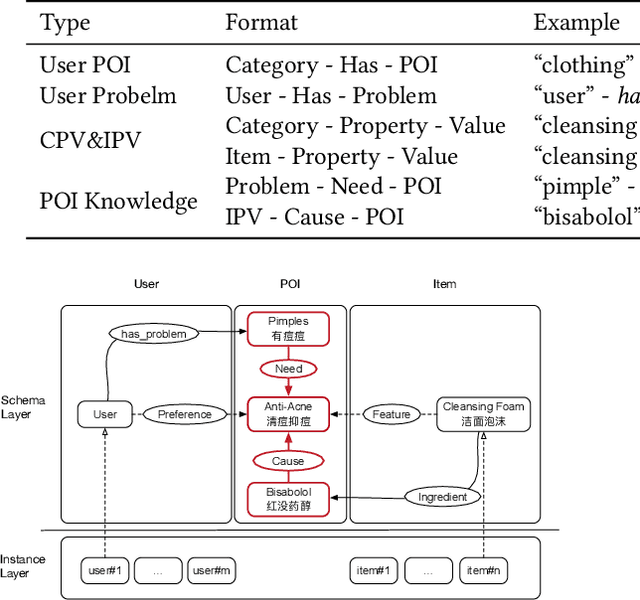
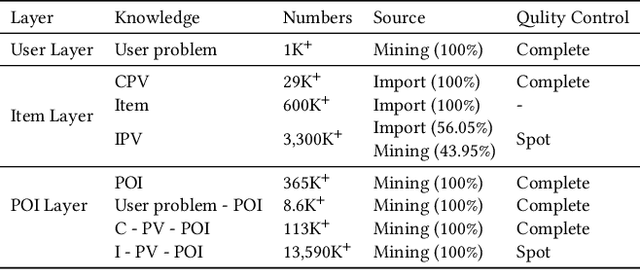
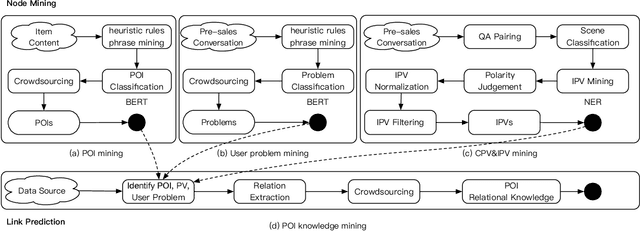
Pre-sales customer service is of importance to E-commerce platforms as it contributes to optimizing customers' buying process. To better serve users, we propose AliMe KG, a domain knowledge graph in E-commerce that captures user problems, points of interests (POI), item information and relations thereof. It helps to understand user needs, answer pre-sales questions and generate explanation texts. We applied AliMe KG to several online business scenarios such as shopping guide, question answering over properties and recommendation reason generation, and gained positive results. In the paper, we systematically introduce how we construct domain knowledge graph from free text, and demonstrate its business value with several applications. Our experience shows that mining structured knowledge from free text in vertical domain is practicable, and can be of substantial value in industrial settings.