 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
May 04, 2026We present Mamoda2.5, a unified AR-Diffusion framework that seamlessly integrates multimodal understanding and generation within a single architecture. To efficiently enhance the model's generation capability, we equip the Diffusion Transformer backbone with a fine-grained Mixture-of-Experts (MoE) design (128 experts, Top-8 routing), yielding a 25B-parameter model that activates only 3B parameters, significantly reducing training costs while scaling up the model capacity. Mamoda2.5 achieves top-tier generation performance on VBench 2.0 and sets a new record in video editing quality, surpassing evaluated open-source models and matching the performance of current top-tier proprietary models, including the Kling O1 on OpenVE-Bench. Furthermore, we introduce a joint few-step distillation and reinforcement learning framework that compresses the 30-step editing model into a 4-step model and greatly accelerates model inference. Compared to open-source baselines, Mamoda2.5 achieves up to $95.9\times$ faster video editing inference. In real-world applications, Mamoda2.5 has been successfully deployed for content moderation and creative restoration tasks in advertising scenarios, achieving a 98% success rate in internal advertising video editing scenario.
Is Memorization Helpful or Harmful? Prior Information Sets the Threshold
Feb 10, 2026We examine the connection between training error and generalization error for arbitrary estimating procedures, working in an overparameterized linear model under general priors in a Bayesian setup. We find determining factors inherent to the prior distribution $π$, giving explicit conditions under which optimal generalization necessitates that the training error be (i) near interpolating relative to the noise size (i.e., memorization is necessary), or (ii) close to the noise level (i.e., overfitting is harmful). Remarkably, these phenomena occur when the noise reaches thresholds determined by the Fisher information and the variance parameters of the prior $π$.
Causal-Driven Feature Evaluation for Cross-Domain Image Classification
Jan 29, 2026Out-of-distribution (OOD) generalization remains a fundamental challenge in real-world classification, where test distributions often differ substantially from training data. Most existing approaches pursue domain-invariant representations, implicitly assuming that invariance implies reliability. However, features that are invariant across domains are not necessarily causally effective for prediction. In this work, we revisit OOD classification from a causal perspective and propose to evaluate learned representations based on their necessity and sufficiency under distribution shift. We introduce an explicit segment-level framework that directly measures causal effectiveness across domains, providing a more faithful criterion than invariance alone. Experiments on multi-domain benchmarks demonstrate consistent improvements in OOD performance, particularly under challenging domain shifts, highlighting the value of causal evaluation for robust generalization.
Concentration Inequalities for Exchangeable Tensors and Matrix-valued Data
Jan 28, 2026We study concentration inequalities for structured weighted sums of random data, including (i) tensor inner products and (ii) sequential matrix sums. We are interested in tail bounds and concentration inequalities for those structured weighted sums under exchangeability, extending beyond the classical framework of independent terms. We develop Hoeffding and Bernstein bounds provided with structure-dependent exchangeability. Along the way, we recover known results in weighted sum of exchangeable random variables and i.i.d. sums of random matrices to the optimal constants. Notably, we develop a sharper concentration bound for combinatorial sum of matrix arrays than the results previously derived from Chatterjee's method of exchangeable pairs. For applications, the richer structures provide us with novel analytical tools for estimating the average effect of multi-factor response models and studying fixed-design sketching methods in federated averaging. We apply our results to these problems, and find that our theoretical predictions are corroborated by numerical evidence.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Neural SDEs as a Unified Approach to Continuous-Domain Sequence Modeling
Jan 31, 2025



Inspired by the ubiquitous use of differential equations to model continuous dynamics across diverse scientific and engineering domains, we propose a novel and intuitive approach to continuous sequence modeling. Our method interprets time-series data as \textit{discrete samples from an underlying continuous dynamical system}, and models its time evolution using Neural Stochastic Differential Equation (Neural SDE), where both the flow (drift) and diffusion terms are parameterized by neural networks. We derive a principled maximum likelihood objective and a \textit{simulation-free} scheme for efficient training of our Neural SDE model. We demonstrate the versatility of our approach through experiments on sequence modeling tasks across both embodied and generative AI. Notably, to the best of our knowledge, this is the first work to show that SDE-based continuous-time modeling also excels in such complex scenarios, and we hope that our work opens up new avenues for research of SDE models in high-dimensional and temporally intricate domains.
Enhanced coarsening of charge density waves induced by electron correlation: Machine-learning enabled large-scale dynamical simulations
Dec 30, 2024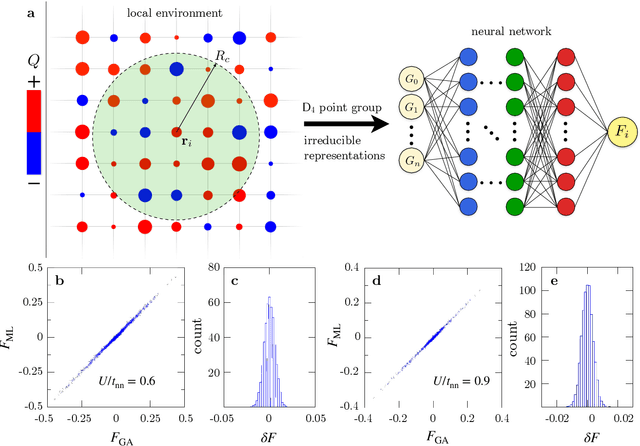
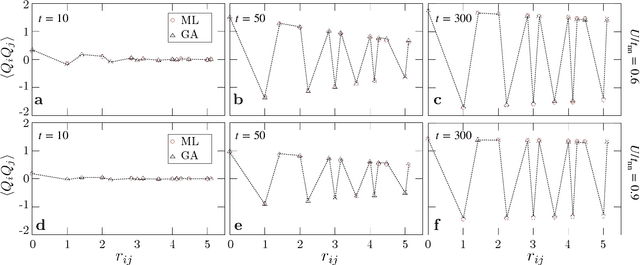

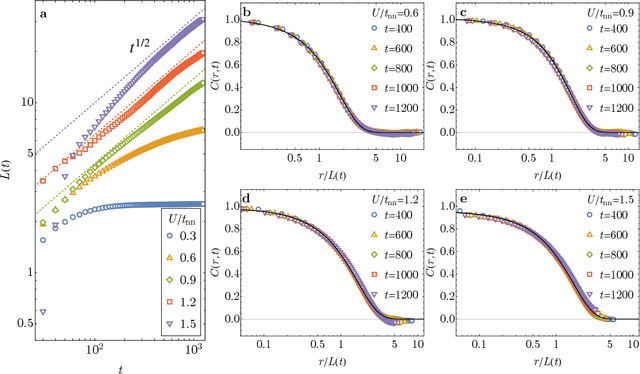
The phase ordering kinetics of emergent orders in correlated electron systems is a fundamental topic in non-equilibrium physics, yet it remains largely unexplored. The intricate interplay between quasiparticles and emergent order-parameter fields could lead to unusual coarsening dynamics that is beyond the standard theories. However, accurate treatment of both quasiparticles and collective degrees of freedom is a multi-scale challenge in dynamical simulations of correlated electrons. Here we leverage modern machine learning (ML) methods to achieve a linear-scaling algorithm for simulating the coarsening of charge density waves (CDWs), one of the fundamental symmetry breaking phases in functional electron materials. We demonstrate our approach on the square-lattice Hubbard-Holstein model and uncover an intriguing enhancement of CDW coarsening which is related to the screening of on-site potential by electron-electron interactions. Our study provides fresh insights into the role of electron correlations in non-equilibrium dynamics and underscores the promise of ML force-field approaches for advancing multi-scale dynamical modeling of correlated electron systems.
Kinetics of orbital ordering in cooperative Jahn-Teller models: Machine-learning enabled large-scale simulations
May 23, 2024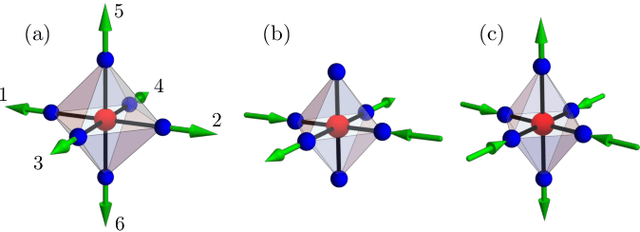

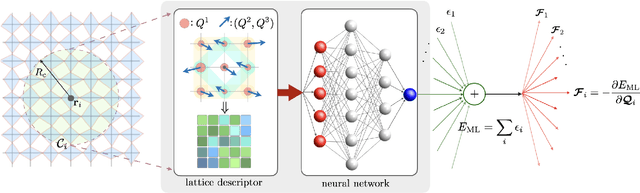
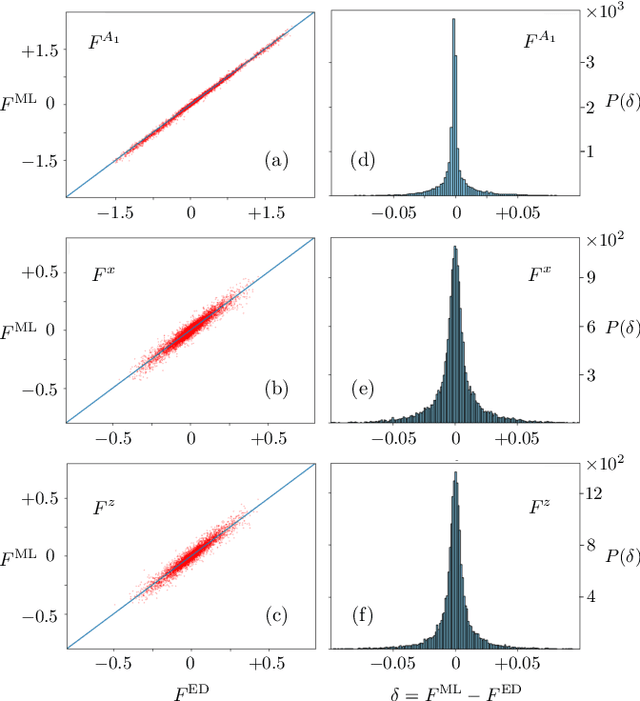
We present a scalable machine learning (ML) force-field model for the adiabatic dynamics of cooperative Jahn-Teller (JT) systems. Large scale dynamical simulations of the JT model also shed light on the orbital ordering dynamics in colossal magnetoresistance manganites. The JT effect in these materials describes the distortion of local oxygen octahedra driven by a coupling to the orbital degrees of freedom of $e_g$ electrons. An effective electron-mediated interaction between the local JT modes leads to a structural transition and the emergence of long-range orbital order at low temperatures. Assuming the principle of locality, a deep-learning neural-network model is developed to accurately and efficiently predict the electron-induced forces that drive the dynamical evolution of JT phonons. A group-theoretical method is utilized to develop a descriptor that incorporates the combined orbital and lattice symmetry into the ML model. Large-scale Langevin dynamics simulations, enabled by the ML force-field models, are performed to investigate the coarsening dynamics of the composite JT distortion and orbital order after a thermal quench. The late-stage coarsening of orbital domains exhibits pronounced freezing behaviors which are likely related to the unusual morphology of the domain structures. Our work highlights a promising avenue for multi-scale dynamical modeling of correlated electron systems.
Exploring the Robustness of In-Context Learning with Noisy Labels
May 01, 2024



Recently, the mysterious In-Context Learning (ICL) ability exhibited by Transformer architectures, especially in large language models (LLMs), has sparked significant research interest. However, the resilience of Transformers' in-context learning capabilities in the presence of noisy samples, prevalent in both training corpora and prompt demonstrations, remains underexplored. In this paper, inspired by prior research that studies ICL ability using simple function classes, we take a closer look at this problem by investigating the robustness of Transformers against noisy labels. Specifically, we first conduct a thorough evaluation and analysis of the robustness of Transformers against noisy labels during in-context learning and show that they exhibit notable resilience against diverse types of noise in demonstration labels. Furthermore, we delve deeper into this problem by exploring whether introducing noise into the training set, akin to a form of data augmentation, enhances such robustness during inference, and find that such noise can indeed improve the robustness of ICL. Overall, our fruitful analysis and findings provide a comprehensive understanding of the resilience of Transformer models against label noises during ICL and provide valuable insights into the research on Transformers in natural language processing. Our code is available at https://github.com/InezYu0928/in-context-learning.