 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Agent-Compatible Context Management for Long-Horizon Tasks
May 29, 2026LLM agents increasingly face long-horizon tasks such as web search and deep research in real-world applications, where accumulated context can cause long-context degradation and reasoning failures. Prior work mitigates this through context management with agent-side context control or fixed strategies such as summarization, which require training the agent itself for adaptation - making it impractical for closed-source agents and ignoring that different agents may require different strategies. We introduce Adaptive Context Management (AdaCoM), which trains an external LLM to manage the context of a frozen agent through flexible modification actions and end-to-end reinforcement learning. Across diverse agents on web search and deep research benchmarks, AdaCoM substantially improves performance by preserving task constraints and progress while pruning stale content. The learned strategies reveal a Fidelity-Reliability Trade-off: agents with higher vanilla ReAct performance benefit from higher-fidelity context preservation, whereas lower-performing agents require more aggressive compression to stay within a reliable reasoning regime. Transfer experiments show that AdaCoM generalizes most effectively across agents with similar capability (measured by vanilla ReAct performance), suggesting a practical path toward reusable context managers for agent systems.
Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents
Jan 05, 2026Large language model (LLM) agents face fundamental limitations in long-horizon reasoning due to finite context windows, making effective memory management critical. Existing methods typically handle long-term memory (LTM) and short-term memory (STM) as separate components, relying on heuristics or auxiliary controllers, which limits adaptability and end-to-end optimization. In this paper, we propose Agentic Memory (AgeMem), a unified framework that integrates LTM and STM management directly into the agent's policy. AgeMem exposes memory operations as tool-based actions, enabling the LLM agent to autonomously decide what and when to store, retrieve, update, summarize, or discard information. To train such unified behaviors, we propose a three-stage progressive reinforcement learning strategy and design a step-wise GRPO to address sparse and discontinuous rewards induced by memory operations. Experiments on five long-horizon benchmarks demonstrate that AgeMem consistently outperforms strong memory-augmented baselines across multiple LLM backbones, achieving improved task performance, higher-quality long-term memory, and more efficient context usage.
Security Tensors as a Cross-Modal Bridge: Extending Text-Aligned Safety to Vision in LVLM
Jul 28, 2025Large visual-language models (LVLMs) integrate aligned large language models (LLMs) with visual modules to process multimodal inputs. However, the safety mechanisms developed for text-based LLMs do not naturally extend to visual modalities, leaving LVLMs vulnerable to harmful image inputs. To address this cross-modal safety gap, we introduce security tensors - trainable input vectors applied during inference through either the textual or visual modality. These tensors transfer textual safety alignment to visual processing without modifying the model's parameters. They are optimized using a curated dataset containing (i) malicious image-text pairs requiring rejection, (ii) contrastive benign pairs with text structurally similar to malicious queries, with the purpose of being contrastive examples to guide visual reliance, and (iii) general benign samples preserving model functionality. Experimental results demonstrate that both textual and visual security tensors significantly enhance LVLMs' ability to reject diverse harmful visual inputs while maintaining near-identical performance on benign tasks. Further internal analysis towards hidden-layer representations reveals that security tensors successfully activate the language module's textual "safety layers" in visual inputs, thereby effectively extending text-based safety to the visual modality.
Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data
Feb 05, 2025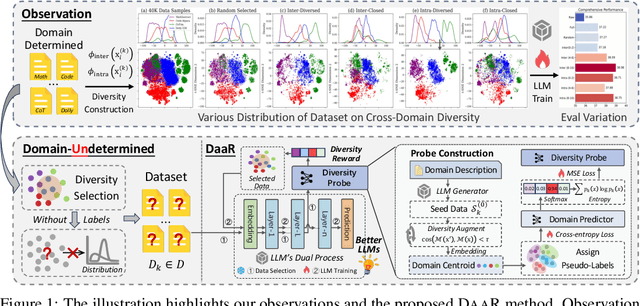

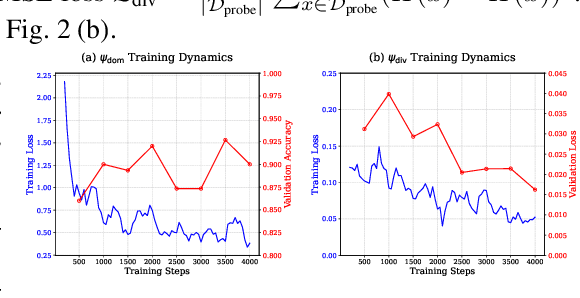
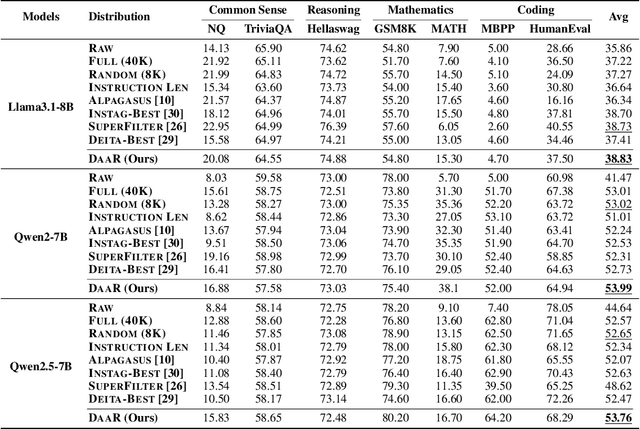
Fine-tuning large language models (LLMs) using diverse datasets is crucial for enhancing their overall performance across various domains. In practical scenarios, existing methods based on modeling the mixture proportions of data composition often struggle with data whose domain labels are missing, imprecise or non-normalized, while methods based on data selection usually encounter difficulties in balancing multi-domain performance. To address these challenges, in this paper, we study the role of data diversity in enhancing the overall abilities of LLMs by empirically constructing contrastive data pools and theoretically deriving explanations for both inter- and intra-diversity. Building upon the insights gained, we propose a new method that gives the LLM a dual identity: an output model to cognitively probe and select data based on diversity reward, as well as an input model to be tuned with the selected data. Extensive experiments show that the proposed method notably boosts performance across domain-undetermined data and a series of foundational downstream tasks when applied to various advanced LLMs. We release our code and hope this study can shed light on the understanding of data diversity and advance feedback-driven data-model co-development for LLMs.
Safety Layers of Aligned Large Language Models: The Key to LLM Security
Aug 30, 2024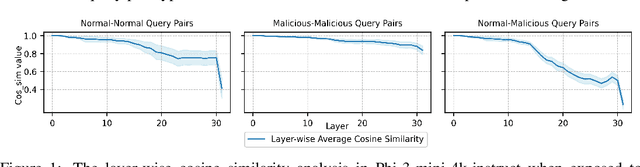



Aligned LLMs are highly secure, capable of recognizing and refusing to answer malicious questions. However, the role of internal parameters in maintaining this security is not well understood, further these models are vulnerable to security degradation when fine-tuned with non-malicious backdoor data or normal data. To address these challenges, our work uncovers the mechanism behind security in aligned LLMs at the parameter level, identifying a small set of contiguous layers in the middle of the model that are crucial for distinguishing malicious queries from normal ones, referred to as "safety layers." We first confirm the existence of these safety layers by analyzing variations in input vectors within the model's internal layers. Additionally, we leverage the over-rejection phenomenon and parameters scaling analysis to precisely locate the safety layers. Building on this understanding, we propose a novel fine-tuning approach, Safely Partial-Parameter Fine-Tuning (SPPFT), that fixes the gradient of the safety layers during fine-tuning to address the security degradation. Our experiments demonstrate that this approach significantly preserves model security while maintaining performance and reducing computational resources compared to full fine-tuning.
The Synergy between Data and Multi-Modal Large Language Models: A Survey from Co-Development Perspective
Jul 11, 2024



The rapid development of large language models (LLMs) has been witnessed in recent years. Based on the powerful LLMs, multi-modal LLMs (MLLMs) extend the modality from text to a broader spectrum of domains, attracting widespread attention due to the broader range of application scenarios. As LLMs and MLLMs rely on vast amounts of model parameters and data to achieve emergent capabilities, the importance of data is receiving increasingly widespread attention and recognition. Tracing and analyzing recent data-oriented works for MLLMs, we find that the development of models and data is not two separate paths but rather interconnected. On the one hand, vaster and higher-quality data contribute to better performance of MLLMs, on the other hand, MLLMs can facilitate the development of data. The co-development of multi-modal data and MLLMs requires a clear view of 1) at which development stage of MLLMs can specific data-centric approaches be employed to enhance which capabilities, and 2) by utilizing which capabilities and acting as which roles can models contribute to multi-modal data. To promote the data-model co-development for MLLM community, we systematically review existing works related to MLLMs from the data-model co-development perspective. A regularly maintained project associated with this survey is accessible at https://github.com/modelscope/data-juicer/blob/main/docs/awesome_llm_data.md.
When to Trust LLMs: Aligning Confidence with Response Quality
Apr 26, 2024Despite the success of large language models (LLMs) in natural language generation, much evidence shows that LLMs may produce incorrect or nonsensical text. This limitation highlights the importance of discerning when to trust LLMs, especially in safety-critical domains. Existing methods, which rely on verbalizing confidence to tell the reliability by inducing top-k responses and sampling-aggregating multiple responses, often fail, due to the lack of objective guidance of confidence. To address this, we propose CONfidence-Quality-ORDerpreserving alignment approach (CONQORD), leveraging reinforcement learning with a tailored dual-component reward function. This function encompasses quality reward and orderpreserving alignment reward functions. Specifically, the order-preserving reward incentivizes the model to verbalize greater confidence for responses of higher quality to align the order of confidence and quality. Experiments demonstrate that our CONQORD significantly improves the alignment performance between confidence levels and response accuracy, without causing the model to become over-cautious. Furthermore, the aligned confidence provided by CONQORD informs when to trust LLMs, and acts as a determinant for initiating the retrieval process of external knowledge. Aligning confidence with response quality ensures more transparent and reliable responses, providing better trustworthiness.
A Bargaining-based Approach for Feature Trading in Vertical Federated Learning
Feb 23, 2024Vertical Federated Learning (VFL) has emerged as a popular machine learning paradigm, enabling model training across the data and the task parties with different features about the same user set while preserving data privacy. In production environment, VFL usually involves one task party and one data party. Fair and economically efficient feature trading is crucial to the commercialization of VFL, where the task party is considered as the data consumer who buys the data party's features. However, current VFL feature trading practices often price the data party's data as a whole and assume transactions occur prior to the performing VFL. Neglecting the performance gains resulting from traded features may lead to underpayment and overpayment issues. In this study, we propose a bargaining-based feature trading approach in VFL to encourage economically efficient transactions. Our model incorporates performance gain-based pricing, taking into account the revenue-based optimization objectives of both parties. We analyze the proposed bargaining model under perfect and imperfect performance information settings, proving the existence of an equilibrium that optimizes the parties' objectives. Moreover, we develop performance gain estimation-based bargaining strategies for imperfect performance information scenarios and discuss potential security issues and solutions. Experiments on three real-world datasets demonstrate the effectiveness of the proposed bargaining model.
Double-I Watermark: Protecting Model Copyright for LLM Fine-tuning
Feb 22, 2024



To support various applications, business owners often seek the customized models that are obtained by fine-tuning a pre-trained LLM through the API provided by LLM owners or cloud servers. However, this process carries a substantial risk of model misuse, potentially resulting in severe economic consequences for business owners. Thus, safeguarding the copyright of these customized models during LLM fine-tuning has become an urgent practical requirement, but there are limited existing solutions to provide such protection. To tackle this pressing issue, we propose a novel watermarking approach named "Double-I watermark". Specifically, based on the instruct-tuning data, two types of backdoor data paradigms are introduced with trigger in the instruction and the input, respectively. By leveraging LLM's learning capability to incorporate customized backdoor samples into the dataset, the proposed approach effectively injects specific watermarking information into the customized model during fine-tuning, which makes it easy to inject and verify watermarks in commercial scenarios. We evaluate the proposed "Double-I watermark" under various fine-tuning methods, demonstrating its harmlessness, robustness, uniqueness, imperceptibility, and validity through both theoretical analysis and experimental verification.
AgentScope: A Flexible yet Robust Multi-Agent Platform
Feb 21, 2024With the rapid advancement of Large Language Models (LLMs), significant progress has been made in multi-agent applications. However, the complexities in coordinating agents' cooperation and LLMs' erratic performance pose notable challenges in developing robust and efficient multi-agent applications. To tackle these challenges, we propose AgentScope, a developer-centric multi-agent platform with message exchange as its core communication mechanism. Together with abundant syntactic tools, built-in resources, and user-friendly interactions, our communication mechanism significantly reduces the barriers to both development and understanding. Towards robust and flexible multi-agent application, AgentScope provides both built-in and customizable fault tolerance mechanisms while it is also armed with system-level supports for multi-modal data generation, storage and transmission. Additionally, we design an actor-based distribution framework, enabling easy conversion between local and distributed deployments and automatic parallel optimization without extra effort. With these features, AgentScope empowers developers to build applications that fully realize the potential of intelligent agents. We have released AgentScope at https://github.com/modelscope/agentscope, and hope AgentScope invites wider participation and innovation in this fast-moving field.