 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning
Oct 30, 2025Reinforcement finetuning (RFT) is a key technique for aligning Large Language Models (LLMs) with human preferences and enhancing reasoning, yet its effectiveness is highly sensitive to which tasks are explored during training. Uniform task sampling is inefficient, wasting computation on tasks that are either trivial or unsolvable, while existing task selection methods often suffer from high rollout costs, poor adaptivity, or incomplete evidence. We introduce \textbf{BOTS}, a unified framework for \textbf{B}ayesian \textbf{O}nline \textbf{T}ask \textbf{S}election in LLM reinforcement finetuning. Grounded in Bayesian inference, BOTS adaptively maintains posterior estimates of task difficulty as the model evolves. It jointly incorporates \emph{explicit evidence} from direct evaluations of selected tasks and \emph{implicit evidence} inferred from these evaluations for unselected tasks, with Thompson sampling ensuring a principled balance between exploration and exploitation. To make implicit evidence practical, we instantiate it with an ultra-light interpolation-based plug-in that estimates difficulties of unevaluated tasks without extra rollouts, adding negligible overhead. Empirically, across diverse domains and LLM scales, BOTS consistently improves data efficiency and performance over baselines and ablations, providing a practical and extensible solution for dynamic task selection in RFT.
Attention Basin: Why Contextual Position Matters in Large Language Models
Aug 07, 2025The performance of Large Language Models (LLMs) is significantly sensitive to the contextual position of information in the input. To investigate the mechanism behind this positional bias, our extensive experiments reveal a consistent phenomenon we term the attention basin: when presented with a sequence of structured items (e.g., retrieved documents or few-shot examples), models systematically assign higher attention to the items at the beginning and end of the sequence, while neglecting those in the middle. Crucially, our analysis further reveals that allocating higher attention to critical information is key to enhancing model performance. Based on these insights, we introduce Attention-Driven Reranking (AttnRank), a two-stage framework that (i) estimates a model's intrinsic positional attention preferences using a small calibration set, and (ii) reorders retrieved documents or few-shot examples to align the most salient content with these high-attention positions. AttnRank is a model-agnostic, training-free, and plug-and-play method with minimal computational overhead. Experiments on multi-hop QA and few-shot in-context learning tasks demonstrate that AttnRank achieves substantial improvements across 10 large language models of varying architectures and scales, without modifying model parameters or training procedures.
MindGYM: Enhancing Vision-Language Models via Synthetic Self-Challenging Questions
Mar 12, 2025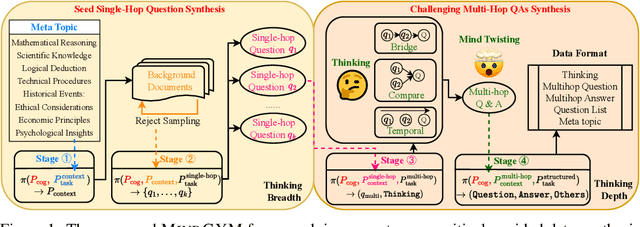
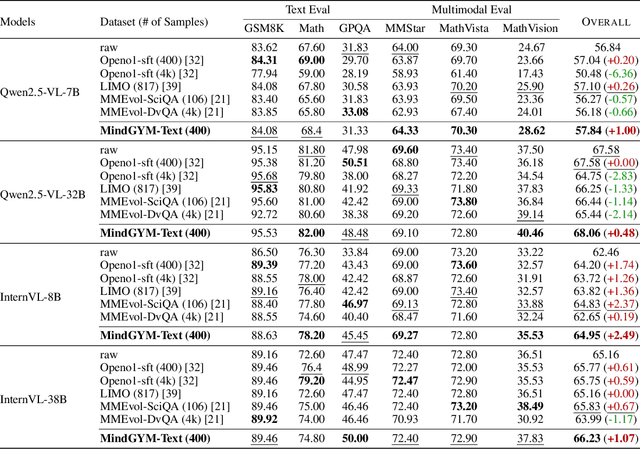
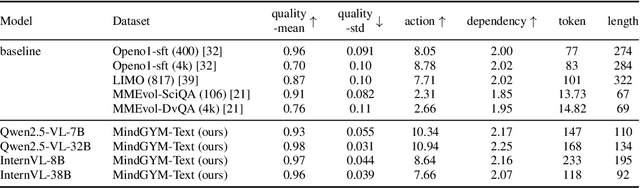
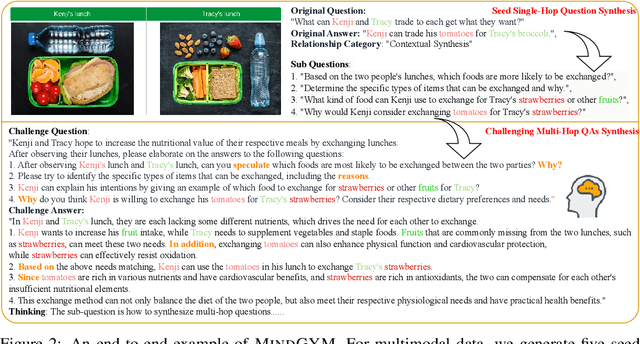
Large vision-language models (VLMs) face challenges in achieving robust, transferable reasoning abilities due to reliance on labor-intensive manual instruction datasets or computationally expensive self-supervised methods. To address these issues, we introduce MindGYM, a framework that enhances VLMs through synthetic self-challenging questions, consisting of three stages: (1) Seed Single-Hop Question Synthesis, generating cognitive questions across textual (e.g., logical deduction) and multimodal contexts (e.g., diagram-based queries) spanning eight semantic areas like ethical analysis; (2) Challenging Multi-Hop Question Synthesis, combining seed questions via diverse principles like bridging, visual-textual alignment, to create multi-step problems demanding deeper reasoning; and (3) Thinking-Induced Curriculum Fine-Tuning, a structured pipeline that progressively trains the model from scaffolded reasoning to standalone inference. By leveraging the model's self-synthesis capability, MindGYM achieves high data efficiency (e.g., +16% gains on MathVision-Mini with only 400 samples), computational efficiency (reducing both training and inference costs), and robust generalization across tasks. Extensive evaluations on seven benchmarks demonstrate superior performance over strong baselines, with notable improvements (+15.77% win rates) in reasoning depth and breadth validated via GPT-based scoring. MindGYM underscores the viability of self-challenging for refining VLM capabilities while minimizing human intervention and resource demands. Code and data are released to advance multimodal reasoning research.
Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data
Feb 05, 2025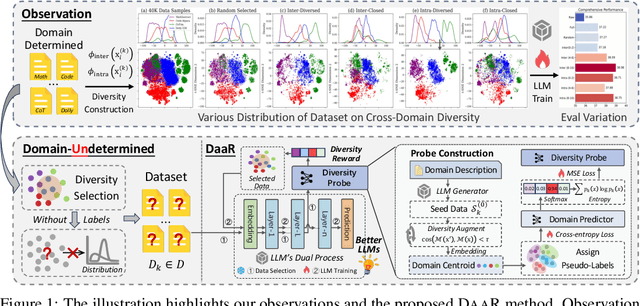

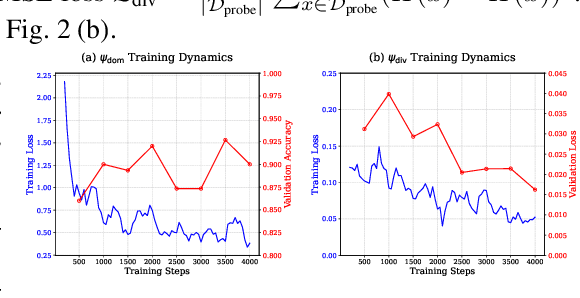
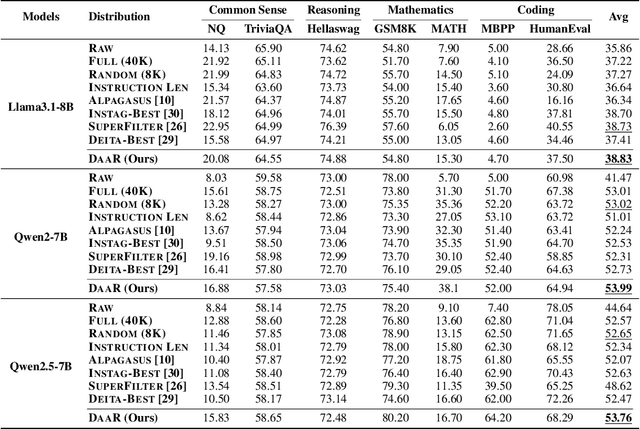
Fine-tuning large language models (LLMs) using diverse datasets is crucial for enhancing their overall performance across various domains. In practical scenarios, existing methods based on modeling the mixture proportions of data composition often struggle with data whose domain labels are missing, imprecise or non-normalized, while methods based on data selection usually encounter difficulties in balancing multi-domain performance. To address these challenges, in this paper, we study the role of data diversity in enhancing the overall abilities of LLMs by empirically constructing contrastive data pools and theoretically deriving explanations for both inter- and intra-diversity. Building upon the insights gained, we propose a new method that gives the LLM a dual identity: an output model to cognitively probe and select data based on diversity reward, as well as an input model to be tuned with the selected data. Extensive experiments show that the proposed method notably boosts performance across domain-undetermined data and a series of foundational downstream tasks when applied to various advanced LLMs. We release our code and hope this study can shed light on the understanding of data diversity and advance feedback-driven data-model co-development for LLMs.
On the Convergence of Zeroth-Order Federated Tuning for Large Language Models
Feb 20, 2024



The confluence of Federated Learning (FL) and Large Language Models (LLMs) is ushering in a new era in privacy-preserving natural language processing. However, the intensive memory requirements for fine-tuning LLMs pose significant challenges, especially when deploying on clients with limited computational resources. To circumvent this, we explore the novel integration of Memory-efficient Zeroth-Order Optimization within a federated setting, a synergy we term as FedMeZO. Our study is the first to examine the theoretical underpinnings of FedMeZO in the context of LLMs, tackling key questions regarding the influence of large parameter spaces on optimization behavior, the establishment of convergence properties, and the identification of critical parameters for convergence to inform personalized federated strategies. Our extensive empirical evidence supports the theory, showing that FedMeZO not only converges faster than traditional first-order methods such as FedAvg but also significantly reduces GPU memory usage during training to levels comparable to those during inference. Moreover, the proposed personalized FL strategy that is built upon the theoretical insights to customize the client-wise learning rate can effectively accelerate loss reduction. We hope our work can help to bridge theoretical and practical aspects of federated fine-tuning for LLMs, thereby stimulating further advancements and research in this area.