 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRAL: Visual In-Context Reasoning via Analogy in Diffusion Transformers
Feb 03, 2026Replicating In-Context Learning (ICL) in computer vision remains challenging due to task heterogeneity. We propose \textbf{VIRAL}, a framework that elicits visual reasoning from a pre-trained image editing model by formulating ICL as conditional generation via visual analogy ($x_s : x_t :: x_q : y_q$). We adapt a frozen Diffusion Transformer (DiT) using role-aware multi-image conditioning and introduce a Mixture-of-Experts LoRA to mitigate gradient interference across diverse tasks. Additionally, to bridge the gaps in current visual context datasets, we curate a large-scale dataset spanning perception, restoration, and editing. Experiments demonstrate that VIRAL outperforms existing methods, validating that a unified V-ICL paradigm can handle the majority of visual tasks, including open-domain editing. Our code is available at https://anonymous.4open.science/r/VIRAL-744A
Spectral Evolution Search: Efficient Inference-Time Scaling for Reward-Aligned Image Generation
Feb 03, 2026Inference-time scaling offers a versatile paradigm for aligning visual generative models with downstream objectives without parameter updates. However, existing approaches that optimize the high-dimensional initial noise suffer from severe inefficiency, as many search directions exert negligible influence on the final generation. We show that this inefficiency is closely related to a spectral bias in generative dynamics: model sensitivity to initial perturbations diminishes rapidly as frequency increases. Building on this insight, we propose Spectral Evolution Search (SES), a plug-and-play framework for initial noise optimization that executes gradient-free evolutionary search within a low-frequency subspace. Theoretically, we derive the Spectral Scaling Prediction from perturbation propagation dynamics, which explains the systematic differences in the impact of perturbations across frequencies. Extensive experiments demonstrate that SES significantly advances the Pareto frontier of generation quality versus computational cost, consistently outperforming strong baselines under equivalent budgets.
BOTS: A Unified Framework for Bayesian Online Task Selection in LLM Reinforcement Finetuning
Oct 30, 2025Reinforcement finetuning (RFT) is a key technique for aligning Large Language Models (LLMs) with human preferences and enhancing reasoning, yet its effectiveness is highly sensitive to which tasks are explored during training. Uniform task sampling is inefficient, wasting computation on tasks that are either trivial or unsolvable, while existing task selection methods often suffer from high rollout costs, poor adaptivity, or incomplete evidence. We introduce \textbf{BOTS}, a unified framework for \textbf{B}ayesian \textbf{O}nline \textbf{T}ask \textbf{S}election in LLM reinforcement finetuning. Grounded in Bayesian inference, BOTS adaptively maintains posterior estimates of task difficulty as the model evolves. It jointly incorporates \emph{explicit evidence} from direct evaluations of selected tasks and \emph{implicit evidence} inferred from these evaluations for unselected tasks, with Thompson sampling ensuring a principled balance between exploration and exploitation. To make implicit evidence practical, we instantiate it with an ultra-light interpolation-based plug-in that estimates difficulties of unevaluated tasks without extra rollouts, adding negligible overhead. Empirically, across diverse domains and LLM scales, BOTS consistently improves data efficiency and performance over baselines and ablations, providing a practical and extensible solution for dynamic task selection in RFT.
Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
May 23, 2025Trinity-RFT is a general-purpose, flexible and scalable framework designed for reinforcement fine-tuning (RFT) of large language models. It is built with a decoupled design, consisting of (1) an RFT-core that unifies and generalizes synchronous/asynchronous, on-policy/off-policy, and online/offline modes of RFT, (2) seamless integration for agent-environment interaction with high efficiency and robustness, and (3) systematic data pipelines optimized for RFT. Trinity-RFT can be easily adapted for diverse application scenarios, and serves as a unified platform for exploring advanced reinforcement learning paradigms. This technical report outlines the vision, features, design and implementations of Trinity-RFT, accompanied by extensive examples demonstrating the utility and user-friendliness of the proposed framework.
DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?
May 22, 2025While recent text-to-image (T2I) models show impressive capabilities in synthesizing images from brief descriptions, their performance significantly degrades when confronted with long, detail-intensive prompts required in professional applications. We present DetailMaster, the first comprehensive benchmark specifically designed to evaluate T2I models' systematical abilities to handle extended textual inputs that contain complex compositional requirements. Our benchmark introduces four critical evaluation dimensions: Character Attributes, Structured Character Locations, Multi-Dimensional Scene Attributes, and Explicit Spatial/Interactive Relationships. The benchmark comprises long and detail-rich prompts averaging 284.89 tokens, with high quality validated by expert annotators. Evaluation on 7 general-purpose and 5 long-prompt-optimized T2I models reveals critical performance limitations: state-of-the-art models achieve merely ~50% accuracy in key dimensions like attribute binding and spatial reasoning, while all models showing progressive performance degradation as prompt length increases. Our analysis highlights systemic failures in structural comprehension and detail overload handling, motivating future research into architectures with enhanced compositional reasoning. We open-source the dataset, data curation code, and evaluation tools to advance detail-rich T2I generation and enable broad applications that would otherwise be infeasible due to the lack of a dedicated benchmark.
MindGYM: Enhancing Vision-Language Models via Synthetic Self-Challenging Questions
Mar 12, 2025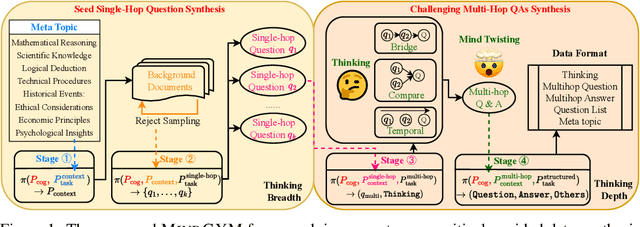
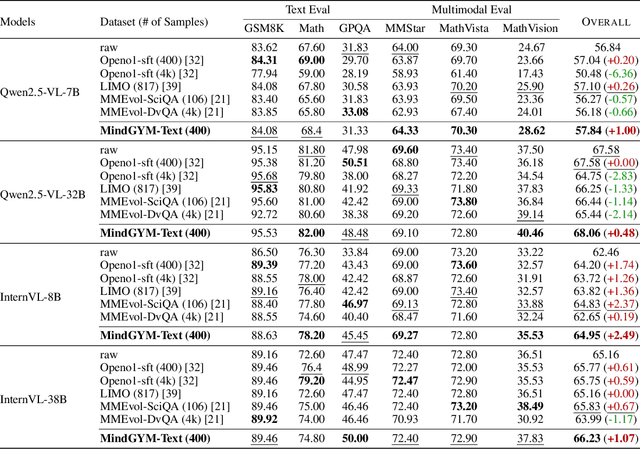
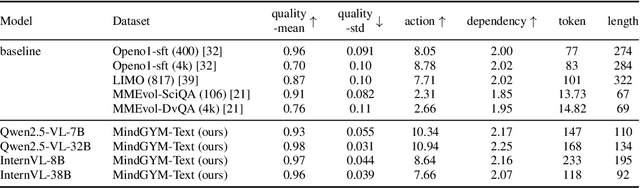
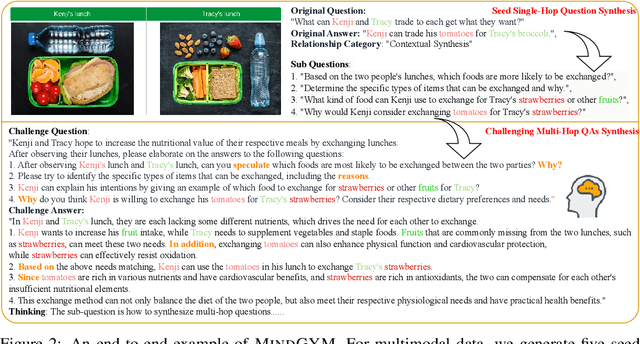
Large vision-language models (VLMs) face challenges in achieving robust, transferable reasoning abilities due to reliance on labor-intensive manual instruction datasets or computationally expensive self-supervised methods. To address these issues, we introduce MindGYM, a framework that enhances VLMs through synthetic self-challenging questions, consisting of three stages: (1) Seed Single-Hop Question Synthesis, generating cognitive questions across textual (e.g., logical deduction) and multimodal contexts (e.g., diagram-based queries) spanning eight semantic areas like ethical analysis; (2) Challenging Multi-Hop Question Synthesis, combining seed questions via diverse principles like bridging, visual-textual alignment, to create multi-step problems demanding deeper reasoning; and (3) Thinking-Induced Curriculum Fine-Tuning, a structured pipeline that progressively trains the model from scaffolded reasoning to standalone inference. By leveraging the model's self-synthesis capability, MindGYM achieves high data efficiency (e.g., +16% gains on MathVision-Mini with only 400 samples), computational efficiency (reducing both training and inference costs), and robust generalization across tasks. Extensive evaluations on seven benchmarks demonstrate superior performance over strong baselines, with notable improvements (+15.77% win rates) in reasoning depth and breadth validated via GPT-based scoring. MindGYM underscores the viability of self-challenging for refining VLM capabilities while minimizing human intervention and resource demands. Code and data are released to advance multimodal reasoning research.
Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data
Feb 05, 2025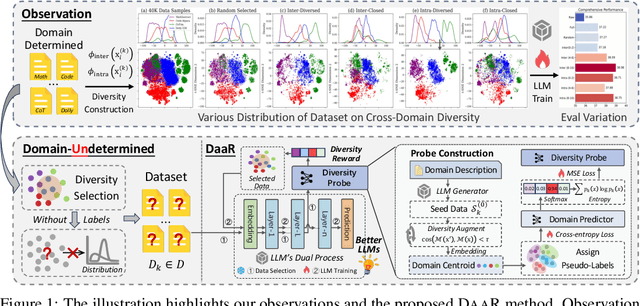

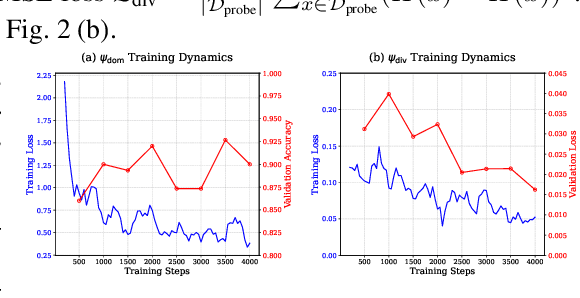
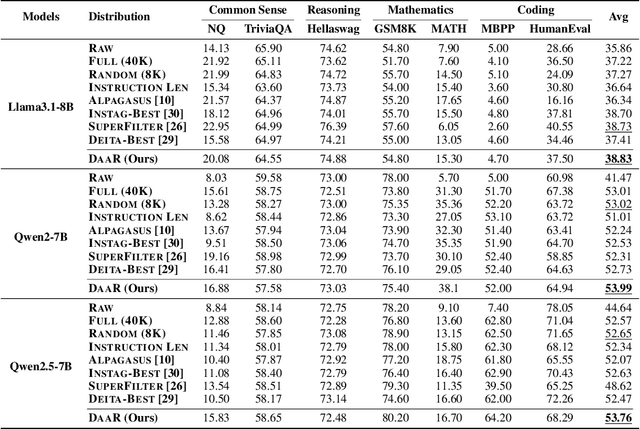
Fine-tuning large language models (LLMs) using diverse datasets is crucial for enhancing their overall performance across various domains. In practical scenarios, existing methods based on modeling the mixture proportions of data composition often struggle with data whose domain labels are missing, imprecise or non-normalized, while methods based on data selection usually encounter difficulties in balancing multi-domain performance. To address these challenges, in this paper, we study the role of data diversity in enhancing the overall abilities of LLMs by empirically constructing contrastive data pools and theoretically deriving explanations for both inter- and intra-diversity. Building upon the insights gained, we propose a new method that gives the LLM a dual identity: an output model to cognitively probe and select data based on diversity reward, as well as an input model to be tuned with the selected data. Extensive experiments show that the proposed method notably boosts performance across domain-undetermined data and a series of foundational downstream tasks when applied to various advanced LLMs. We release our code and hope this study can shed light on the understanding of data diversity and advance feedback-driven data-model co-development for LLMs.
HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
Dec 23, 2024



In the domain of Multimodal Large Language Models (MLLMs), achieving human-centric video understanding remains a formidable challenge. Existing benchmarks primarily emphasize object and action recognition, often neglecting the intricate nuances of human emotions, behaviors, and speech visual alignment within video content. We present HumanVBench, an innovative benchmark meticulously crafted to bridge these gaps in the evaluation of video MLLMs. HumanVBench comprises 17 carefully designed tasks that explore two primary dimensions: inner emotion and outer manifestations, spanning static and dynamic, basic and complex, as well as single-modal and cross-modal aspects. With two advanced automated pipelines for video annotation and distractor-included QA generation, HumanVBench utilizes diverse state-of-the-art (SOTA) techniques to streamline benchmark data synthesis and quality assessment, minimizing human annotation dependency tailored to human-centric multimodal attributes. A comprehensive evaluation across 16 SOTA video MLLMs reveals notable limitations in current performance, especially in cross-modal and temporal alignment, underscoring the necessity for further refinement toward achieving more human-like understanding. HumanVBench is open-sourced to facilitate future advancements and real-world applications in video MLLMs.
ArtAug: Enhancing Text-to-Image Generation through Synthesis-Understanding Interaction
Dec 18, 2024



The emergence of diffusion models has significantly advanced image synthesis. The recent studies of model interaction and self-corrective reasoning approach in large language models offer new insights for enhancing text-to-image models. Inspired by these studies, we propose a novel method called ArtAug for enhancing text-to-image models in this paper. To the best of our knowledge, ArtAug is the first one that improves image synthesis models via model interactions with understanding models. In the interactions, we leverage human preferences implicitly learned by image understanding models to provide fine-grained suggestions for image synthesis models. The interactions can modify the image content to make it aesthetically pleasing, such as adjusting exposure, changing shooting angles, and adding atmospheric effects. The enhancements brought by the interaction are iteratively fused into the synthesis model itself through an additional enhancement module. This enables the synthesis model to directly produce aesthetically pleasing images without any extra computational cost. In the experiments, we train the ArtAug enhancement module on existing text-to-image models. Various evaluation metrics consistently demonstrate that ArtAug enhances the generative capabilities of text-to-image models without incurring additional computational costs. The source code and models will be released publicly.
Img-Diff: Contrastive Data Synthesis for Multimodal Large Language Models
Aug 09, 2024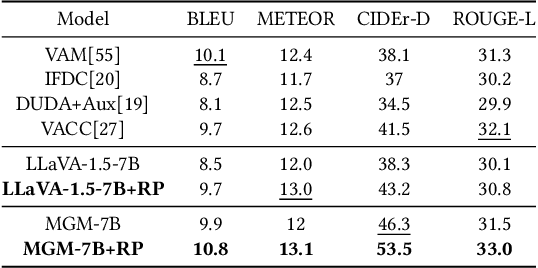
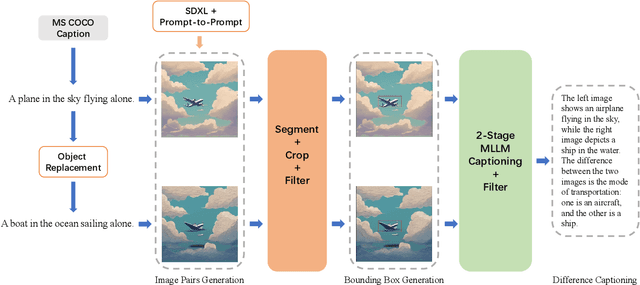
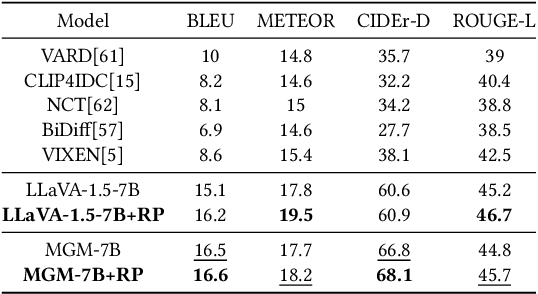
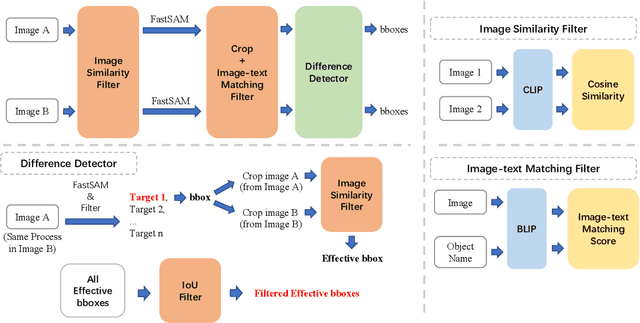
High-performance Multimodal Large Language Models (MLLMs) rely heavily on data quality. This study introduces a novel dataset named Img-Diff, designed to enhance fine-grained image recognition in MLLMs by leveraging insights from contrastive learning and image difference captioning. By analyzing object differences between similar images, we challenge models to identify both matching and distinct components. We utilize the Stable-Diffusion-XL model and advanced image editing techniques to create pairs of similar images that highlight object replacements. Our methodology includes a Difference Area Generator for object differences identifying, followed by a Difference Captions Generator for detailed difference descriptions. The result is a relatively small but high-quality dataset of "object replacement" samples. We use the the proposed dataset to finetune state-of-the-art (SOTA) MLLMs such as MGM-7B, yielding comprehensive improvements of performance scores over SOTA models that trained with larger-scale datasets, in numerous image difference and Visual Question Answering tasks. For instance, our trained models notably surpass the SOTA models GPT-4V and Gemini on the MMVP benchmark. Besides, we investigate alternative methods for generating image difference data through "object removal" and conduct a thorough evaluation to confirm the dataset's diversity, quality, and robustness, presenting several insights on the synthesis of such a contrastive dataset. To encourage further research and advance the field of multimodal data synthesis and enhancement of MLLMs' fundamental capabilities for image understanding, we release our codes and dataset at https://github.com/modelscope/data-juicer/tree/ImgDiff.