 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models
Feb 03, 2026Entropy serves as a critical metric for measuring the diversity of outputs generated by large language models (LLMs), providing valuable insights into their exploration capabilities. While recent studies increasingly focus on monitoring and adjusting entropy to better balance exploration and exploitation in reinforcement fine-tuning (RFT), a principled understanding of entropy dynamics during this process is yet to be thoroughly investigated. In this paper, we establish a theoretical framework for analyzing the entropy dynamics during the RFT process, which begins with a discriminant expression that quantifies entropy change under a single logit update. This foundation enables the derivation of a first-order expression for entropy change, which can be further extended to the update formula of Group Relative Policy Optimization (GRPO). The corollaries and insights drawn from the theoretical analysis inspire the design of entropy control methods, and also offer a unified lens for interpreting various entropy-based methods in existing studies. We provide empirical evidence to support the main conclusions of our analysis and demonstrate the effectiveness of the derived entropy-discriminator clipping methods. This study yields novel insights into RFT training dynamics, providing theoretical support and practical strategies for optimizing the exploration-exploitation balance during LLM fine-tuning.
R$^3$L: Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification
Jan 07, 2026Reinforcement learning drives recent advances in LLM reasoning and agentic capabilities, yet current approaches struggle with both exploration and exploitation. Exploration suffers from low success rates on difficult tasks and high costs of repeated rollouts from scratch. Exploitation suffers from coarse credit assignment and training instability: Trajectory-level rewards penalize valid prefixes for later errors, and failure-dominated groups overwhelm the few positive signals, leaving optimization without constructive direction. To this end, we propose R$^3$L, Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification. To synthesize high-quality trajectories, R$^3$L shifts from stochastic sampling to active synthesis via reflect-then-retry, leveraging language feedback to diagnose errors, transform failed attempts into successful ones, and reduce rollout costs by restarting from identified failure points. With errors diagnosed and localized, Pivotal Credit Assignment updates only the diverging suffix where contrastive signals exist, excluding the shared prefix from gradient update. Since failures dominate on difficult tasks and reflect-then-retry produces off-policy data, risking training instability, Positive Amplification upweights successful trajectories to ensure positive signals guide the optimization process. Experiments on agentic and reasoning tasks demonstrate 5\% to 52\% relative improvements over baselines while maintaining training stability. Our code is released at https://github.com/shiweijiezero/R3L.
AHA: Aligning Large Audio-Language Models for Reasoning Hallucinations via Counterfactual Hard Negatives
Dec 30, 2025Although Large Audio-Language Models (LALMs) deliver state-of-the-art (SOTA) performance, they frequently suffer from hallucinations, e.g. generating text not grounded in the audio input. We analyze these grounding failures and identify a distinct taxonomy: Event Omission, False Event Identity, Temporal Relation Error, and Quantitative Temporal Error. To address this, we introduce the AHA (Audio Hallucination Alignment) framework. By leveraging counterfactual hard negative mining, our pipeline constructs a high-quality preference dataset that forces models to distinguish strict acoustic evidence from linguistically plausible fabrications. Additionally, we establish AHA-Eval, a diagnostic benchmark designed to rigorously test these fine-grained temporal reasoning capabilities. We apply this data to align Qwen2.5-Omni. The resulting model, Qwen-Audio-AHA, achieves a 13.7% improvement on AHA-Eval. Crucially, this benefit generalizes beyond our diagnostic set. Our model shows substantial gains on public benchmarks, including 1.3% on MMAU-Test and 1.6% on MMAR, outperforming latest SOTA methods.
Pose State Perception of Interventional Robot for Cardio-cerebrovascular Procedures
Jun 17, 2025In response to the increasing demand for cardiocerebrovascular interventional surgeries, precise control of interventional robots has become increasingly important. Within these complex vascular scenarios, the accurate and reliable perception of the pose state for interventional robots is particularly crucial. This paper presents a novel vision-based approach without the need of additional sensors or markers. The core of this paper's method consists of a three-part framework: firstly, a dual-head multitask U-Net model for simultaneous vessel segment and interventional robot detection; secondly, an advanced algorithm for skeleton extraction and optimization; and finally, a comprehensive pose state perception system based on geometric features is implemented to accurately identify the robot's pose state and provide strategies for subsequent control. The experimental results demonstrate the proposed method's high reliability and accuracy in trajectory tracking and pose state perception.
Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
May 23, 2025Trinity-RFT is a general-purpose, flexible and scalable framework designed for reinforcement fine-tuning (RFT) of large language models. It is built with a decoupled design, consisting of (1) an RFT-core that unifies and generalizes synchronous/asynchronous, on-policy/off-policy, and online/offline modes of RFT, (2) seamless integration for agent-environment interaction with high efficiency and robustness, and (3) systematic data pipelines optimized for RFT. Trinity-RFT can be easily adapted for diverse application scenarios, and serves as a unified platform for exploring advanced reinforcement learning paradigms. This technical report outlines the vision, features, design and implementations of Trinity-RFT, accompanied by extensive examples demonstrating the utility and user-friendliness of the proposed framework.
Enhancing Latent Computation in Transformers with Latent Tokens
May 19, 2025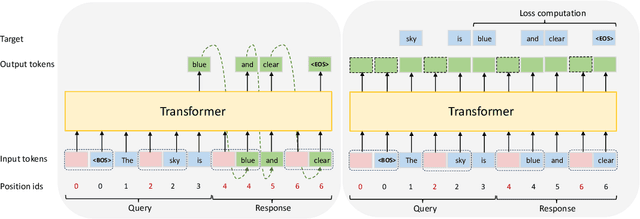

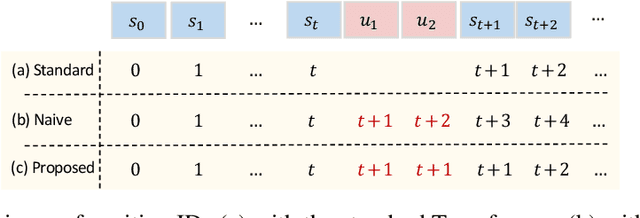
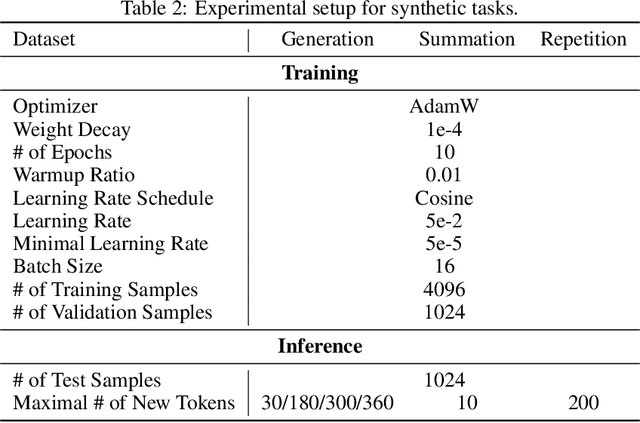
Augmenting large language models (LLMs) with auxiliary tokens has emerged as a promising strategy for enhancing model performance. In this work, we introduce a lightweight method termed latent tokens; these are dummy tokens that may be non-interpretable in natural language but steer the autoregressive decoding process of a Transformer-based LLM via the attention mechanism. The proposed latent tokens can be seamlessly integrated with a pre-trained Transformer, trained in a parameter-efficient manner, and applied flexibly at inference time, while adding minimal complexity overhead to the existing infrastructure of standard Transformers. We propose several hypotheses about the underlying mechanisms of latent tokens and design synthetic tasks accordingly to verify them. Numerical results confirm that the proposed method noticeably outperforms the baselines, particularly in the out-of-distribution generalization scenarios, highlighting its potential in improving the adaptability of LLMs.
RetinalGPT: A Retinal Clinical Preference Conversational Assistant Powered by Large Vision-Language Models
Mar 06, 2025Recently, Multimodal Large Language Models (MLLMs) have gained significant attention for their remarkable ability to process and analyze non-textual data, such as images, videos, and audio. Notably, several adaptations of general-domain MLLMs to the medical field have been explored, including LLaVA-Med. However, these medical adaptations remain insufficiently advanced in understanding and interpreting retinal images. In contrast, medical experts emphasize the importance of quantitative analyses for disease detection and interpretation. This underscores a gap between general-domain and medical-domain MLLMs: while general-domain MLLMs excel in broad applications, they lack the specialized knowledge necessary for precise diagnostic and interpretative tasks in the medical field. To address these challenges, we introduce \textit{RetinalGPT}, a multimodal conversational assistant for clinically preferred quantitative analysis of retinal images. Specifically, we achieve this by compiling a large retinal image dataset, developing a novel data pipeline, and employing customized visual instruction tuning to enhance both retinal analysis and enrich medical knowledge. In particular, RetinalGPT outperforms MLLM in the generic domain by a large margin in the diagnosis of retinal diseases in 8 benchmark retinal datasets. Beyond disease diagnosis, RetinalGPT features quantitative analyses and lesion localization, representing a pioneering step in leveraging LLMs for an interpretable and end-to-end clinical research framework. The code is available at https://github.com/Retinal-Research/RetinalGPT
Enhancing Alzheimer's Diagnosis: Leveraging Anatomical Landmarks in Graph Convolutional Neural Networks on Tetrahedral Meshes
Mar 06, 2025Alzheimer's disease (AD) is a major neurodegenerative condition that affects millions around the world. As one of the main biomarkers in the AD diagnosis procedure, brain amyloid positivity is typically identified by positron emission tomography (PET), which is costly and invasive. Brain structural magnetic resonance imaging (sMRI) may provide a safer and more convenient solution for the AD diagnosis. Recent advances in geometric deep learning have facilitated sMRI analysis and early diagnosis of AD. However, determining AD pathology, such as brain amyloid deposition, in preclinical stage remains challenging, as less significant morphological changes can be observed. As a result, few AD classification models are generalizable to the brain amyloid positivity classification task. Blood-based biomarkers (BBBMs), on the other hand, have recently achieved remarkable success in predicting brain amyloid positivity and identifying individuals with high risk of being brain amyloid positive. However, individuals in medium risk group still require gold standard tests such as Amyloid PET for further evaluation. Inspired by the recent success of transformer architectures, we propose a geometric deep learning model based on transformer that is both scalable and robust to variations in input volumetric mesh size. Our work introduced a novel tokenization scheme for tetrahedral meshes, incorporating anatomical landmarks generated by a pre-trained Gaussian process model. Our model achieved superior classification performance in AD classification task. In addition, we showed that the model was also generalizable to the brain amyloid positivity prediction with individuals in the medium risk class, where BM alone cannot achieve a clear classification. Our work may enrich geometric deep learning research and improve AD diagnosis accuracy without using expensive and invasive PET scans.
Plasma-CycleGAN: Plasma Biomarker-Guided MRI to PET Cross-modality Translation Using Conditional CycleGAN
Jan 04, 2025



Cross-modality translation between MRI and PET imaging is challenging due to the distinct mechanisms underlying these modalities. Blood-based biomarkers (BBBMs) are revolutionizing Alzheimer's disease (AD) detection by identifying patients and quantifying brain amyloid levels. However, the potential of BBBMs to enhance PET image synthesis remains unexplored. In this paper, we performed a thorough study on the effect of incorporating BBBM into deep generative models. By evaluating three widely used cross-modality translation models, we found that BBBMs integration consistently enhances the generative quality across all models. By visual inspection of the generated results, we observed that PET images generated by CycleGAN exhibit the best visual fidelity. Based on these findings, we propose Plasma-CycleGAN, a novel generative model based on CycleGAN, to synthesize PET images from MRI using BBBMs as conditions. This is the first approach to integrate BBBMs in conditional cross-modality translation between MRI and PET.
Many-MobileNet: Multi-Model Augmentation for Robust Retinal Disease Classification
Dec 03, 2024



In this work, we propose Many-MobileNet, an efficient model fusion strategy for retinal disease classification using lightweight CNN architecture. Our method addresses key challenges such as overfitting and limited dataset variability by training multiple models with distinct data augmentation strategies and different model complexities. Through this fusion technique, we achieved robust generalization in data-scarce domains while balancing computational efficiency with feature extraction capabilities.