 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Mesh Transformers with Topology-Guided Pretraining for Morphometric Analysis of Brain Structures
Apr 06, 2026Representation learning on large-scale unstructured volumetric and surface meshes poses significant challenges in neuroimaging, especially when models must incorporate diverse vertex-level morphometric descriptors, such as cortical thickness, curvature, sulcal depth, and myelin content, which carry subtle disease-related signals. Current approaches either ignore these clinically informative features or support only a single mesh topology, restricting their use across imaging pipelines. We introduce a hierarchical transformer framework designed for heterogeneous mesh analysis that operates on spatially adaptive tree partitions constructed from simplicial complexes of arbitrary order. This design accommodates both volumetric and surface discretizations within a single architecture, enabling efficient multi-scale attention without topology-specific modifications. A feature projection module maps variable-length per-vertex clinical descriptors into the spatial hierarchy, separating geometric structure from feature dimensionality and allowing seamless integration of different neuroimaging feature sets. Self-supervised pretraining via masked reconstruction of both coordinates and morphometric channels on large unlabeled cohorts yields a transferable encoder backbone applicable to diverse downstream tasks and mesh modalities. We validate our approach on Alzheimer's disease classification and amyloid burden prediction using volumetric brain meshes from ADNI, as well as focal cortical dysplasia detection on cortical surface meshes from the MELD dataset, achieving state-of-the-art results across all benchmarks.
SODA: Semi On-Policy Black-Box Distillation for Large Language Models
Apr 04, 2026Black-box knowledge distillation for large language models presents a strict trade-off. Simple off-policy methods (e.g., sequence-level knowledge distillation) struggle to correct the student's inherent errors. Fully on-policy methods (e.g., Generative Adversarial Distillation) solve this via adversarial training but introduce well-known training instability and crippling computational overhead. To address this dilemma, we propose SODA (Semi On-policy Distillation with Alignment), a highly efficient alternative motivated by the inherent capability gap between frontier teachers and much smaller base models. Because a compact student model's natural, zero-shot responses are almost strictly inferior to the powerful teacher's targets, we can construct a highly effective contrastive signal simply by pairing the teacher's optimal response with a one-time static snapshot of the student's outputs. This demonstrates that exposing the small student to its own static inferior behaviors is sufficient for high-quality distribution alignment, eliminating the need for costly dynamic rollouts and fragile adversarial balancing. Extensive evaluations across four compact Qwen2.5 and Llama-3 models validate this semi on-policy paradigm. SODA matches or outperforms the state-of-the-art methods on 15 out of 16 benchmark results. More importantly, it achieves this superior distillation quality while training 10 times faster, consuming 27% less peak GPU memory, and completely eliminating adversarial instability.
Bridging Restoration and Diagnosis: A Comprehensive Benchmark for Retinal Fundus Enhancement
Apr 04, 2026Over the past decade, generative models have demonstrated success in enhancing fundus images. However, the evaluation of these models remains a challenge. A benchmark for fundus image enhancement is needed for three main reasons:(1) Conventional denoising metrics such as PSNR and SSIM fail to capture clinically relevant features, such as lesion preservation and vessel morphology consistency, limiting their applicability in real-world settings; (2) There is a lack of unified evaluation protocols that address both paired and unpaired enhancement methods, particularly those guided by clinical expertise; and (3) An evaluation framework should provide actionable insights to guide future advancements in clinically aligned enhancement models. To address these gaps, we introduce EyeBench-V2, a benchmark designed to bridge the gap between enhancement model performance and clinical utility. Our work offers three key contributions:(1) Multi-dimensional clinical-alignment through downstream evaluations: Beyond standard enhancement metrics, we assess performance across clinically meaningful tasks including vessel segmentation, diabetic retinopathy (DR) grading, generalization to unseen noise patterns, and lesion segmentation. (2) Expert-guided evaluation design: We curate a novel dataset enabling fair comparisons between paired and unpaired enhancement methods, accompanied by a structured manual assessment protocol by medical experts, which evaluates clinically critical aspects such as lesion structure alterations, background color shifts, and the introduction of artificial structures. (3) Actionable insights: Our benchmark provides a rigorous, task-oriented analysis of existing generative models, equipping clinical researchers with the evidence needed to make informed decisions, while also identifying limitations in current methods to inform the design of next-generation enhancement models.
Your Agent is More Brittle Than You Think: Uncovering Indirect Injection Vulnerabilities in Agentic LLMs
Apr 04, 2026The rapid deployment of open-source frameworks has significantly advanced the development of modern multi-agent systems. However, expanded action spaces, including uncontrolled privilege exposure and hidden inter-system interactions, pose severe security challenges. Specifically, Indirect Prompt Injections (IPI), which conceal malicious instructions within third-party content, can trigger unauthorized actions such as data exfiltration during normal operations. While current security evaluations predominantly rely on isolated single-turn benchmarks, the systemic vulnerabilities of these agents within complex dynamic environments remain critically underexplored. To bridge this gap, we systematically evaluate six defense strategies against four sophisticated IPI attack vectors across nine LLM backbones. Crucially, we conduct our evaluation entirely within dynamic multi-step tool-calling environments to capture the true attack surface of modern autonomous agents. Moving beyond binary success rates, our multidimensional analysis reveals a pronounced fragility. Advanced injections successfully bypass nearly all baseline defenses, and some surface-level mitigations even produce counterproductive side effects. Furthermore, while agents execute malicious instructions almost instantaneously, their internal states exhibit abnormally high decision entropy. Motivated by this latent hesitation, we investigate Representation Engineering (RepE) as a robust detection strategy. By extracting hidden states at the tool-input position, we revealed that the RepE-based circuit breaker successfully identifies and intercepts unauthorized actions before the agent commits to them, achieving high detection accuracy across diverse LLM backbones. This study exposes the limitations of current IPI defenses and provides a highly practical paradigm for building resilient multi-agent architectures.
OTPrune: Distribution-Aligned Visual Token Pruning via Optimal Transport
Feb 25, 2026Multi-modal large language models (MLLMs) achieve strong visual-language reasoning but suffer from high inference cost due to redundant visual tokens. Recent work explores visual token pruning to accelerate inference, while existing pruning methods overlook the underlying distributional structure of visual representations. We propose OTPrune, a training-free framework that formulates pruning as distribution alignment via optimal transport (OT). By minimizing the 2-Wasserstein distance between the full and pruned token distributions, OTPrune preserves both local diversity and global representativeness while reducing inference cost. Moreover, we derive a tractable submodular objective that enables efficient optimization, and theoretically prove its monotonicity and submodularity, providing a principled foundation for stable and efficient pruning. We further provide a comprehensive analysis that explains how distributional alignment contributes to stable and semantically faithful pruning. Comprehensive experiments on wider benchmarks demonstrate that OTPrune achieves superior performance-efficiency tradeoffs compared to state-of-the-art methods. The code is available at https://github.com/xiwenc1/OTPrune.
SGW-GAN: Sliced Gromov-Wasserstein Guided GANs for Retinal Fundus Image Enhancement
Jan 19, 2026Retinal fundus photography is indispensable for ophthalmic screening and diagnosis, yet image quality is often degraded by noise, artifacts, and uneven illumination. Recent GAN- and diffusion-based enhancement methods improve perceptual quality by aligning degraded images with high-quality distributions, but our analysis shows that this focus can distort intra-class geometry: clinically related samples become dispersed, disease-class boundaries blur, and downstream tasks such as grading or lesion detection are harmed. The Gromov Wasserstein (GW) discrepancy offers a principled solution by aligning distributions through internal pairwise distances, naturally preserving intra-class structure, but its high computational cost restricts practical use. To overcome this, we propose SGW-GAN, the first framework to incorporate Sliced GW (SGW) into retinal image enhancement. SGW approximates GW via random projections, retaining relational fidelity while greatly reducing cost. Experiments on public datasets show that SGW-GAN produces visually compelling enhancements, achieves superior diabetic retinopathy grading, and reports the lowest GW discrepancy across disease labels, demonstrating both efficiency and clinical fidelity for unpaired medical image enhancement.
AHA: Aligning Large Audio-Language Models for Reasoning Hallucinations via Counterfactual Hard Negatives
Dec 30, 2025Although Large Audio-Language Models (LALMs) deliver state-of-the-art (SOTA) performance, they frequently suffer from hallucinations, e.g. generating text not grounded in the audio input. We analyze these grounding failures and identify a distinct taxonomy: Event Omission, False Event Identity, Temporal Relation Error, and Quantitative Temporal Error. To address this, we introduce the AHA (Audio Hallucination Alignment) framework. By leveraging counterfactual hard negative mining, our pipeline constructs a high-quality preference dataset that forces models to distinguish strict acoustic evidence from linguistically plausible fabrications. Additionally, we establish AHA-Eval, a diagnostic benchmark designed to rigorously test these fine-grained temporal reasoning capabilities. We apply this data to align Qwen2.5-Omni. The resulting model, Qwen-Audio-AHA, achieves a 13.7% improvement on AHA-Eval. Crucially, this benefit generalizes beyond our diagnostic set. Our model shows substantial gains on public benchmarks, including 1.3% on MMAU-Test and 1.6% on MMAR, outperforming latest SOTA methods.
Fast 2DGS: Efficient Image Representation with Deep Gaussian Prior
Dec 14, 2025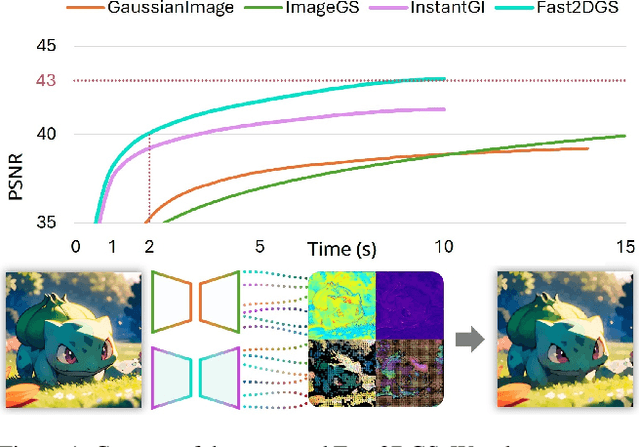

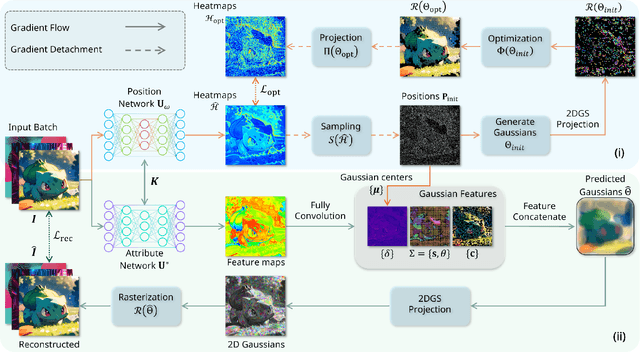
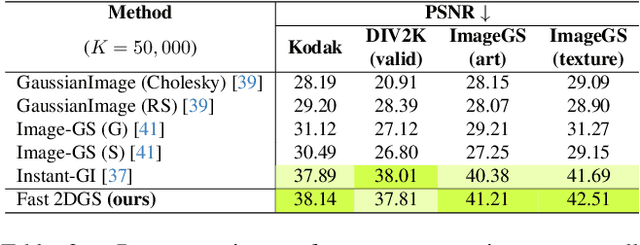
As generative models become increasingly capable of producing high-fidelity visual content, the demand for efficient, interpretable, and editable image representations has grown substantially. Recent advances in 2D Gaussian Splatting (2DGS) have emerged as a promising solution, offering explicit control, high interpretability, and real-time rendering capabilities (>1000 FPS). However, high-quality 2DGS typically requires post-optimization. Existing methods adopt random or heuristics (e.g., gradient maps), which are often insensitive to image complexity and lead to slow convergence (>10s). More recent approaches introduce learnable networks to predict initial Gaussian configurations, but at the cost of increased computational and architectural complexity. To bridge this gap, we present Fast-2DGS, a lightweight framework for efficient Gaussian image representation. Specifically, we introduce Deep Gaussian Prior, implemented as a conditional network to capture the spatial distribution of Gaussian primitives under different complexities. In addition, we propose an attribute regression network to predict dense Gaussian properties. Experiments demonstrate that this disentangled architecture achieves high-quality reconstruction in a single forward pass, followed by minimal fine-tuning. More importantly, our approach significantly reduces computational cost without compromising visual quality, bringing 2DGS closer to industry-ready deployment.
Toward Effective Reinforcement Learning Fine-Tuning for Medical VQA in Vision-Language Models
May 20, 2025

Recently, reinforcement learning (RL)-based tuning has shifted the trajectory of Multimodal Large Language Models (MLLMs), particularly following the introduction of Group Relative Policy Optimization (GRPO). However, directly applying it to medical tasks remains challenging for achieving clinically grounded model behavior. Motivated by the need to align model response with clinical expectations, we investigate four critical dimensions that affect the effectiveness of RL-based tuning in medical visual question answering (VQA): base model initialization strategy, the role of medical semantic alignment, the impact of length-based rewards on long-chain reasoning, and the influence of bias. We conduct extensive experiments to analyze these factors for medical MLLMs, providing new insights into how models are domain-specifically fine-tuned. Additionally, our results also demonstrate that GRPO-based RL tuning consistently outperforms standard supervised fine-tuning (SFT) in both accuracy and reasoning quality.
DRA-GRPO: Exploring Diversity-Aware Reward Adjustment for R1-Zero-Like Training of Large Language Models
May 14, 2025Recent advances in reinforcement learning for language model post-training, such as Group Relative Policy Optimization (GRPO), have shown promise in low-resource settings. However, GRPO typically relies on solution-level and scalar reward signals that fail to capture the semantic diversity among sampled completions. This leads to what we identify as a diversity-quality inconsistency, where distinct reasoning paths may receive indistinguishable rewards. To address this limitation, we propose $\textit{Diversity-aware Reward Adjustment}$ (DRA), a method that explicitly incorporates semantic diversity into the reward computation. DRA uses Submodular Mutual Information (SMI) to downweight redundant completions and amplify rewards for diverse ones. This encourages better exploration during learning, while maintaining stable exploitation of high-quality samples. Our method integrates seamlessly with both GRPO and its variant DR.~GRPO, resulting in $\textit{DRA-GRPO}$ and $\textit{DGA-DR.~GRPO}$. We evaluate our method on five mathematical reasoning benchmarks and find that it outperforms recent strong baselines. It achieves state-of-the-art performance with an average accuracy of 58.2%, using only 7,000 fine-tuning samples and a total training cost of approximately $55. The code is available at https://github.com/xiwenc1/DRA-GRPO.