 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
TauGenNet: Plasma-Driven Tau PET Image Synthesis via Text-Guided 3D Diffusion Models
Sep 04, 2025



Accurate quantification of tau pathology via tau positron emission tomography (PET) scan is crucial for diagnosing and monitoring Alzheimer's disease (AD). However, the high cost and limited availability of tau PET restrict its widespread use. In contrast, structural magnetic resonance imaging (MRI) and plasma-based biomarkers provide non-invasive and widely available complementary information related to brain anatomy and disease progression. In this work, we propose a text-guided 3D diffusion model for 3D tau PET image synthesis, leveraging multimodal conditions from both structural MRI and plasma measurement. Specifically, the textual prompt is from the plasma p-tau217 measurement, which is a key indicator of AD progression, while MRI provides anatomical structure constraints. The proposed framework is trained and evaluated using clinical AV1451 tau PET data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database. Experimental results demonstrate that our approach can generate realistic, clinically meaningful 3D tau PET across a range of disease stages. The proposed framework can help perform tau PET data augmentation under different settings, provide a non-invasive, cost-effective alternative for visualizing tau pathology, and support the simulation of disease progression under varying plasma biomarker levels and cognitive conditions.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
Understanding How Value Neurons Shape the Generation of Specified Values in LLMs
May 23, 2025Rapid integration of large language models (LLMs) into societal applications has intensified concerns about their alignment with universal ethical principles, as their internal value representations remain opaque despite behavioral alignment advancements. Current approaches struggle to systematically interpret how values are encoded in neural architectures, limited by datasets that prioritize superficial judgments over mechanistic analysis. We introduce ValueLocate, a mechanistic interpretability framework grounded in the Schwartz Values Survey, to address this gap. Our method first constructs ValueInsight, a dataset that operationalizes four dimensions of universal value through behavioral contexts in the real world. Leveraging this dataset, we develop a neuron identification method that calculates activation differences between opposing value aspects, enabling precise localization of value-critical neurons without relying on computationally intensive attribution methods. Our proposed validation method demonstrates that targeted manipulation of these neurons effectively alters model value orientations, establishing causal relationships between neurons and value representations. This work advances the foundation for value alignment by bridging psychological value frameworks with neuron analysis in LLMs.
Toward Effective Reinforcement Learning Fine-Tuning for Medical VQA in Vision-Language Models
May 20, 2025

Recently, reinforcement learning (RL)-based tuning has shifted the trajectory of Multimodal Large Language Models (MLLMs), particularly following the introduction of Group Relative Policy Optimization (GRPO). However, directly applying it to medical tasks remains challenging for achieving clinically grounded model behavior. Motivated by the need to align model response with clinical expectations, we investigate four critical dimensions that affect the effectiveness of RL-based tuning in medical visual question answering (VQA): base model initialization strategy, the role of medical semantic alignment, the impact of length-based rewards on long-chain reasoning, and the influence of bias. We conduct extensive experiments to analyze these factors for medical MLLMs, providing new insights into how models are domain-specifically fine-tuned. Additionally, our results also demonstrate that GRPO-based RL tuning consistently outperforms standard supervised fine-tuning (SFT) in both accuracy and reasoning quality.
Accurate KV Cache Quantization with Outlier Tokens Tracing
May 16, 2025The impressive capabilities of Large Language Models (LLMs) come at the cost of substantial computational resources during deployment. While KV Cache can significantly reduce recomputation during inference, it also introduces additional memory overhead. KV Cache quantization presents a promising solution, striking a good balance between memory usage and accuracy. Previous research has shown that the Keys are distributed by channel, while the Values are distributed by token. Consequently, the common practice is to apply channel-wise quantization to the Keys and token-wise quantization to the Values. However, our further investigation reveals that a small subset of unusual tokens exhibit unique characteristics that deviate from this pattern, which can substantially impact quantization accuracy. To address this, we develop a simple yet effective method to identify these tokens accurately during the decoding process and exclude them from quantization as outlier tokens, significantly improving overall accuracy. Extensive experiments show that our method achieves significant accuracy improvements under 2-bit quantization and can deliver a 6.4 times reduction in memory usage and a 2.3 times increase in throughput.
Talk Before You Retrieve: Agent-Led Discussions for Better RAG in Medical QA
Apr 30, 2025Medical question answering (QA) is a reasoning-intensive task that remains challenging for large language models (LLMs) due to hallucinations and outdated domain knowledge. Retrieval-Augmented Generation (RAG) provides a promising post-training solution by leveraging external knowledge. However, existing medical RAG systems suffer from two key limitations: (1) a lack of modeling for human-like reasoning behaviors during information retrieval, and (2) reliance on suboptimal medical corpora, which often results in the retrieval of irrelevant or noisy snippets. To overcome these challenges, we propose Discuss-RAG, a plug-and-play module designed to enhance the medical QA RAG system through collaborative agent-based reasoning. Our method introduces a summarizer agent that orchestrates a team of medical experts to emulate multi-turn brainstorming, thereby improving the relevance of retrieved content. Additionally, a decision-making agent evaluates the retrieved snippets before their final integration. Experimental results on four benchmark medical QA datasets show that Discuss-RAG consistently outperforms MedRAG, especially significantly improving answer accuracy by up to 16.67% on BioASQ and 12.20% on PubMedQA. The code is available at: https://github.com/LLM-VLM-GSL/Discuss-RAG.
Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains
Apr 01, 2025
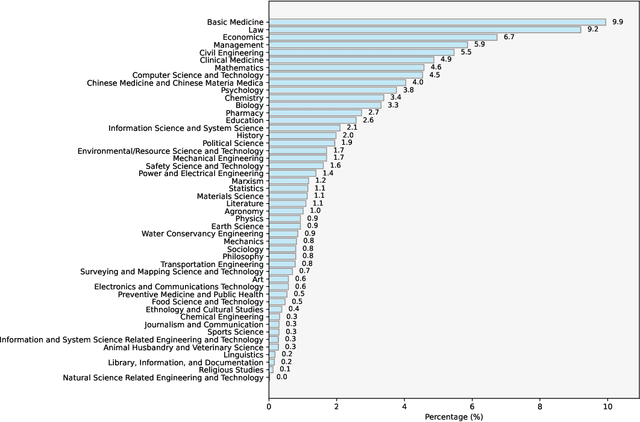


Reinforcement learning with verifiable rewards (RLVR) has demonstrated significant success in enhancing mathematical reasoning and coding performance of large language models (LLMs), especially when structured reference answers are accessible for verification. However, its extension to broader, less structured domains remains unexplored. In this work, we investigate the effectiveness and scalability of RLVR across diverse real-world domains including medicine, chemistry, psychology, economics, and education, where structured reference answers are typically unavailable. We reveal that binary verification judgments on broad-domain tasks exhibit high consistency across various LLMs provided expert-written reference answers exist. Motivated by this finding, we utilize a generative scoring technique that yields soft, model-based reward signals to overcome limitations posed by binary verifications, especially in free-form, unstructured answer scenarios. We further demonstrate the feasibility of training cross-domain generative reward models using relatively small (7B) LLMs without the need for extensive domain-specific annotation. Through comprehensive experiments, our RLVR framework establishes clear performance gains, significantly outperforming state-of-the-art open-source aligned models such as Qwen2.5-72B and DeepSeek-R1-Distill-Qwen-32B across domains in free-form settings. Our approach notably enhances the robustness, flexibility, and scalability of RLVR, representing a substantial step towards practical reinforcement learning applications in complex, noisy-label scenarios.
Enhancing Alzheimer's Diagnosis: Leveraging Anatomical Landmarks in Graph Convolutional Neural Networks on Tetrahedral Meshes
Mar 06, 2025Alzheimer's disease (AD) is a major neurodegenerative condition that affects millions around the world. As one of the main biomarkers in the AD diagnosis procedure, brain amyloid positivity is typically identified by positron emission tomography (PET), which is costly and invasive. Brain structural magnetic resonance imaging (sMRI) may provide a safer and more convenient solution for the AD diagnosis. Recent advances in geometric deep learning have facilitated sMRI analysis and early diagnosis of AD. However, determining AD pathology, such as brain amyloid deposition, in preclinical stage remains challenging, as less significant morphological changes can be observed. As a result, few AD classification models are generalizable to the brain amyloid positivity classification task. Blood-based biomarkers (BBBMs), on the other hand, have recently achieved remarkable success in predicting brain amyloid positivity and identifying individuals with high risk of being brain amyloid positive. However, individuals in medium risk group still require gold standard tests such as Amyloid PET for further evaluation. Inspired by the recent success of transformer architectures, we propose a geometric deep learning model based on transformer that is both scalable and robust to variations in input volumetric mesh size. Our work introduced a novel tokenization scheme for tetrahedral meshes, incorporating anatomical landmarks generated by a pre-trained Gaussian process model. Our model achieved superior classification performance in AD classification task. In addition, we showed that the model was also generalizable to the brain amyloid positivity prediction with individuals in the medium risk class, where BM alone cannot achieve a clear classification. Our work may enrich geometric deep learning research and improve AD diagnosis accuracy without using expensive and invasive PET scans.
RetinalGPT: A Retinal Clinical Preference Conversational Assistant Powered by Large Vision-Language Models
Mar 06, 2025Recently, Multimodal Large Language Models (MLLMs) have gained significant attention for their remarkable ability to process and analyze non-textual data, such as images, videos, and audio. Notably, several adaptations of general-domain MLLMs to the medical field have been explored, including LLaVA-Med. However, these medical adaptations remain insufficiently advanced in understanding and interpreting retinal images. In contrast, medical experts emphasize the importance of quantitative analyses for disease detection and interpretation. This underscores a gap between general-domain and medical-domain MLLMs: while general-domain MLLMs excel in broad applications, they lack the specialized knowledge necessary for precise diagnostic and interpretative tasks in the medical field. To address these challenges, we introduce \textit{RetinalGPT}, a multimodal conversational assistant for clinically preferred quantitative analysis of retinal images. Specifically, we achieve this by compiling a large retinal image dataset, developing a novel data pipeline, and employing customized visual instruction tuning to enhance both retinal analysis and enrich medical knowledge. In particular, RetinalGPT outperforms MLLM in the generic domain by a large margin in the diagnosis of retinal diseases in 8 benchmark retinal datasets. Beyond disease diagnosis, RetinalGPT features quantitative analyses and lesion localization, representing a pioneering step in leveraging LLMs for an interpretable and end-to-end clinical research framework. The code is available at https://github.com/Retinal-Research/RetinalGPT