 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Directed Speech Detection for Follow-up Conversations Using Large Language Models
Nov 04, 2024Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
KGLens: A Parameterized Knowledge Graph Solution to Assess What an LLM Does and Doesn't Know
Dec 15, 2023Current approaches to evaluating large language models (LLMs) with pre-existing Knowledge Graphs (KG) mostly ignore the structure of the KG and make arbitrary choices of which part of the graph to evaluate. In this paper, we introduce KGLens, a method to evaluate LLMs by generating natural language questions from a KG in a structure aware manner so that we can characterize its performance on a more aggregated level. KGLens uses a parameterized KG, where each edge is augmented with a beta distribution that guides how to sample edges from the KG for QA testing. As the evaluation proceeds, different edges of the parameterized KG are sampled and assessed appropriately, converging to a more global picture of the performance of the LLMs on the KG as a whole. In our experiments, we construct three domain-specific KGs for knowledge assessment, comprising over 19,000 edges, 700 relations, and 21,000 entities. The results demonstrate that KGLens can not only assess overall performance but also provide topic, temporal, and relation analyses of LLMs. This showcases the adaptability and customizability of KGLens, emphasizing its ability to focus the evaluation based on specific criteria.
Leveraging Large Language Models for Exploiting ASR Uncertainty
Sep 12, 2023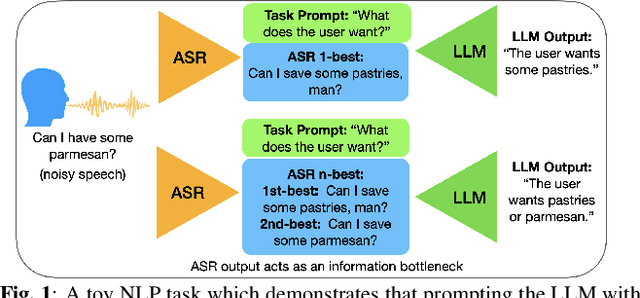


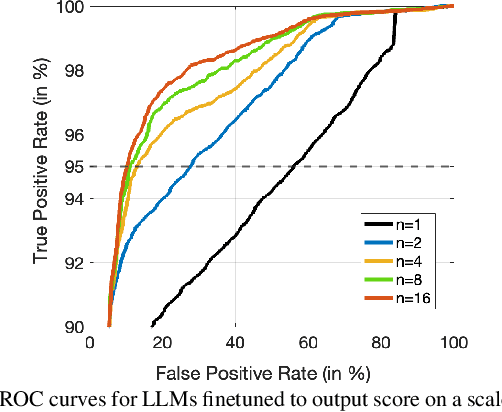
While large language models excel in a variety of natural language processing (NLP) tasks, to perform well on spoken language understanding (SLU) tasks, they must either rely on off-the-shelf automatic speech recognition (ASR) systems for transcription, or be equipped with an in-built speech modality. This work focuses on the former scenario, where LLM's accuracy on SLU tasks is constrained by the accuracy of a fixed ASR system on the spoken input. Specifically, we tackle speech-intent classification task, where a high word-error-rate can limit the LLM's ability to understand the spoken intent. Instead of chasing a high accuracy by designing complex or specialized architectures regardless of deployment costs, we seek to answer how far we can go without substantially changing the underlying ASR and LLM, which can potentially be shared by multiple unrelated tasks. To this end, we propose prompting the LLM with an n-best list of ASR hypotheses instead of only the error-prone 1-best hypothesis. We explore prompt-engineering to explain the concept of n-best lists to the LLM; followed by the finetuning of Low-Rank Adapters on the downstream tasks. Our approach using n-best lists proves to be effective on a device-directed speech detection task as well as on a keyword spotting task, where systems using n-best list prompts outperform those using 1-best ASR hypothesis; thus paving the way for an efficient method to exploit ASR uncertainty via LLMs for speech-based applications.
Complementary Language Model and Parallel Bi-LRNN for False Trigger Mitigation
Aug 18, 2020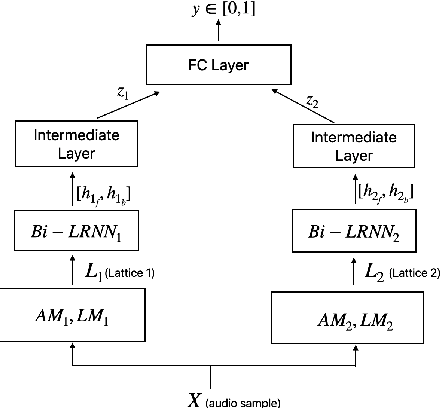

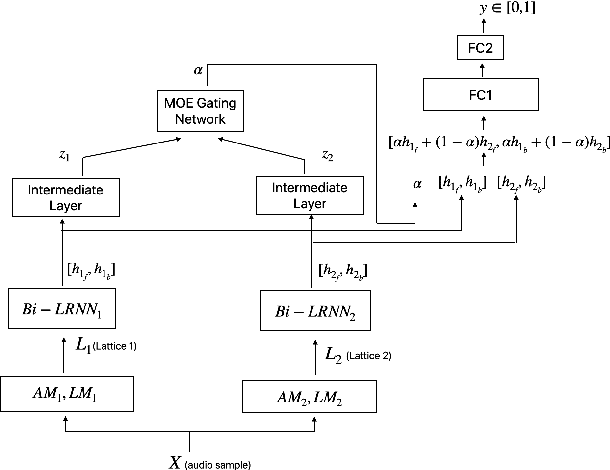
False triggers in voice assistants are unintended invocations of the assistant, which not only degrade the user experience but may also compromise privacy. False trigger mitigation (FTM) is a process to detect the false trigger events and respond appropriately to the user. In this paper, we propose a novel solution to the FTM problem by introducing a parallel ASR decoding process with a special language model trained from "out-of-domain" data sources. Such language model is complementary to the existing language model optimized for the assistant task. A bidirectional lattice RNN (Bi-LRNN) classifier trained from the lattices generated by the complementary language model shows a $38.34\%$ relative reduction of the false trigger (FT) rate at the fixed rate of $0.4\%$ false suppression (FS) of correct invocations, compared to the current Bi-LRNN model. In addition, we propose to train a parallel Bi-LRNN model based on the decoding lattices from both language models, and examine various ways of implementation. The resulting model leads to further reduction in the false trigger rate by $10.8\%$.