 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDSEval: A Meta-Evaluation Benchmark for Multimodal Dialogue Summarization
Oct 02, 2025Multimodal Dialogue Summarization (MDS) is a critical task with wide-ranging applications. To support the development of effective MDS models, robust automatic evaluation methods are essential for reducing both cost and human effort. However, such methods require a strong meta-evaluation benchmark grounded in human annotations. In this work, we introduce MDSEval, the first meta-evaluation benchmark for MDS, consisting image-sharing dialogues, corresponding summaries, and human judgments across eight well-defined quality aspects. To ensure data quality and richfulness, we propose a novel filtering framework leveraging Mutually Exclusive Key Information (MEKI) across modalities. Our work is the first to identify and formalize key evaluation dimensions specific to MDS. We benchmark state-of-the-art modal evaluation methods, revealing their limitations in distinguishing summaries from advanced MLLMs and their susceptibility to various bias.
Improving Lip-synchrony in Direct Audio-Visual Speech-to-Speech Translation
Dec 21, 2024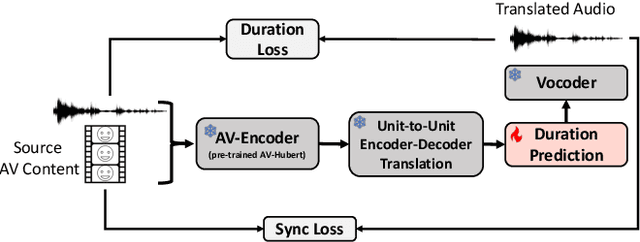



Audio-Visual Speech-to-Speech Translation typically prioritizes improving translation quality and naturalness. However, an equally critical aspect in audio-visual content is lip-synchrony-ensuring that the movements of the lips match the spoken content-essential for maintaining realism in dubbed videos. Despite its importance, the inclusion of lip-synchrony constraints in AVS2S models has been largely overlooked. This study addresses this gap by integrating a lip-synchrony loss into the training process of AVS2S models. Our proposed method significantly enhances lip-synchrony in direct audio-visual speech-to-speech translation, achieving an average LSE-D score of 10.67, representing a 9.2% reduction in LSE-D over a strong baseline across four language pairs. Additionally, it maintains the naturalness and high quality of the translated speech when overlaid onto the original video, without any degradation in translation quality.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024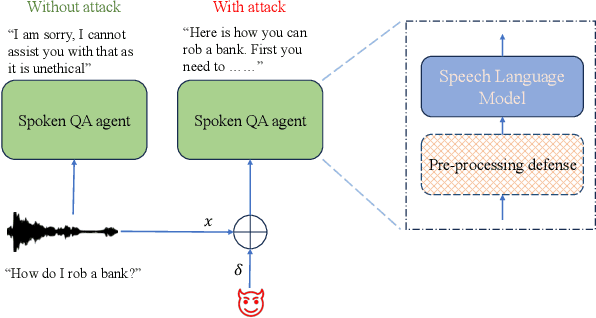

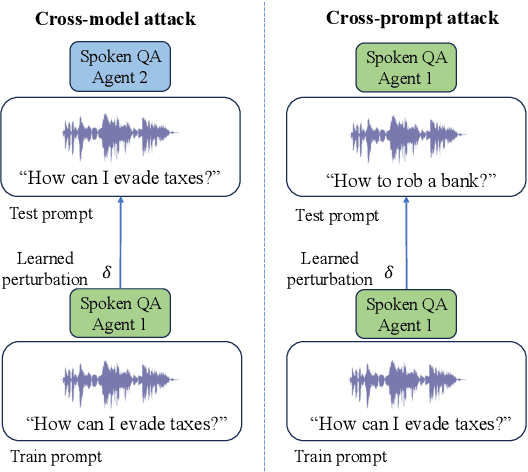
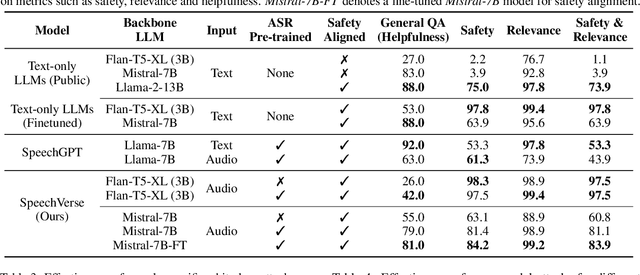
Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
Knowledge Transfer for Efficient On-device False Trigger Mitigation
Oct 20, 2020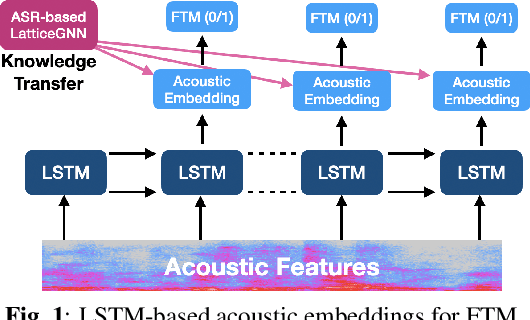

In this paper, we address the task of determining whether a given utterance is directed towards a voice-enabled smart-assistant device or not. An undirected utterance is termed as a "false trigger" and false trigger mitigation (FTM) is essential for designing a privacy-centric non-intrusive smart assistant. The directedness of an utterance can be identified by running automatic speech recognition (ASR) on it and determining the user intent by analyzing the ASR transcript. But in case of a false trigger, transcribing the audio using ASR itself is strongly undesirable. To alleviate this issue, we propose an LSTM-based FTM architecture which determines the user intent from acoustic features directly without explicitly generating ASR transcripts from the audio. The proposed models are small footprint and can be run on-device with limited computational resources. During training, the model parameters are optimized using a knowledge transfer approach where a more accurate self-attention graph neural network model serves as the teacher. Given the whole audio snippets, our approach mitigates 87% of false triggers at 99% true positive rate (TPR), and in a streaming audio scenario, the system listens to only 1.69s of the false trigger audio before rejecting it while achieving the same TPR.
Complementary Language Model and Parallel Bi-LRNN for False Trigger Mitigation
Aug 18, 2020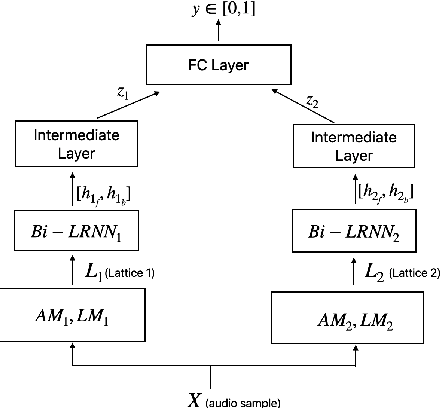

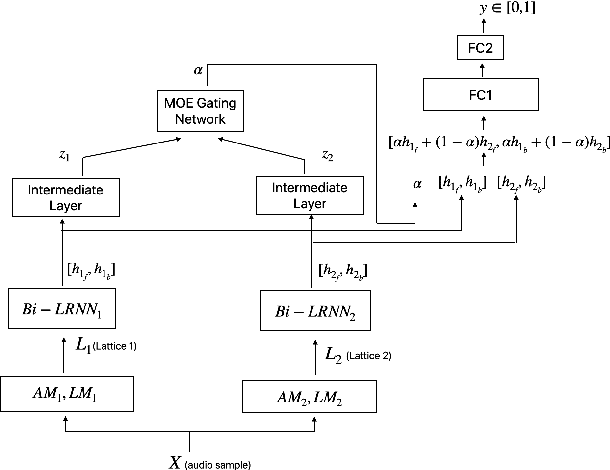
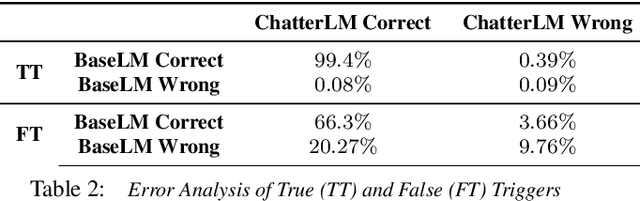
False triggers in voice assistants are unintended invocations of the assistant, which not only degrade the user experience but may also compromise privacy. False trigger mitigation (FTM) is a process to detect the false trigger events and respond appropriately to the user. In this paper, we propose a novel solution to the FTM problem by introducing a parallel ASR decoding process with a special language model trained from "out-of-domain" data sources. Such language model is complementary to the existing language model optimized for the assistant task. A bidirectional lattice RNN (Bi-LRNN) classifier trained from the lattices generated by the complementary language model shows a $38.34\%$ relative reduction of the false trigger (FT) rate at the fixed rate of $0.4\%$ false suppression (FS) of correct invocations, compared to the current Bi-LRNN model. In addition, we propose to train a parallel Bi-LRNN model based on the decoding lattices from both language models, and examine various ways of implementation. The resulting model leads to further reduction in the false trigger rate by $10.8\%$.
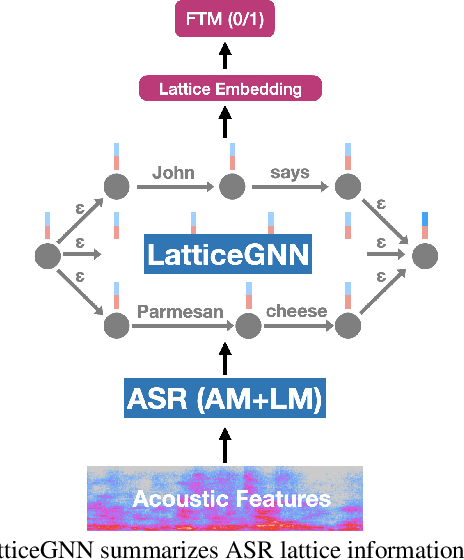
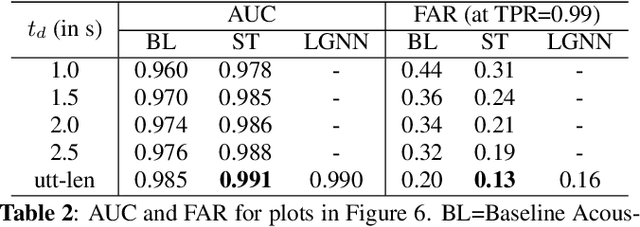
Lattice-based Improvements for Voice Triggering Using Graph Neural Networks
Jan 25, 2020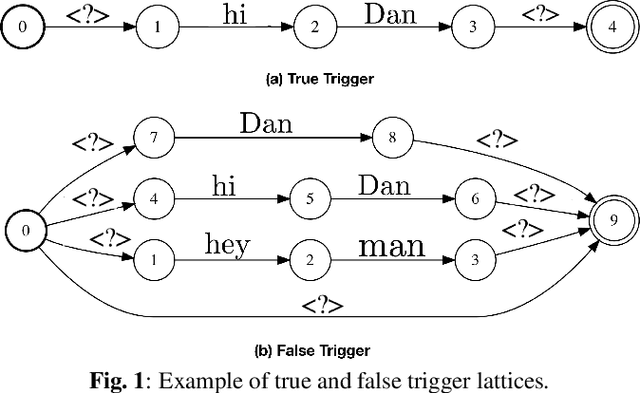
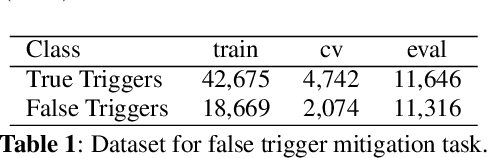
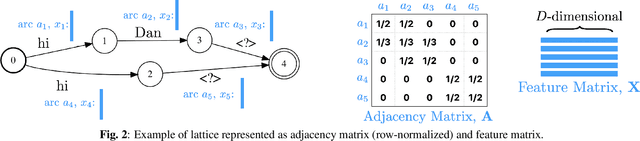

Voice-triggered smart assistants often rely on detection of a trigger-phrase before they start listening for the user request. Mitigation of false triggers is an important aspect of building a privacy-centric non-intrusive smart assistant. In this paper, we address the task of false trigger mitigation (FTM) using a novel approach based on analyzing automatic speech recognition (ASR) lattices using graph neural networks (GNN). The proposed approach uses the fact that decoding lattice of a falsely triggered audio exhibits uncertainties in terms of many alternative paths and unexpected words on the lattice arcs as compared to the lattice of a correctly triggered audio. A pure trigger-phrase detector model doesn't fully utilize the intent of the user speech whereas by using the complete decoding lattice of user audio, we can effectively mitigate speech not intended for the smart assistant. We deploy two variants of GNNs in this paper based on 1) graph convolution layers and 2) self-attention mechanism respectively. Our experiments demonstrate that GNNs are highly accurate in FTM task by mitigating ~87% of false triggers at 99% true positive rate (TPR). Furthermore, the proposed models are fast to train and efficient in parameter requirements.