 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Assistant Language Understanding On Device
Aug 07, 2023
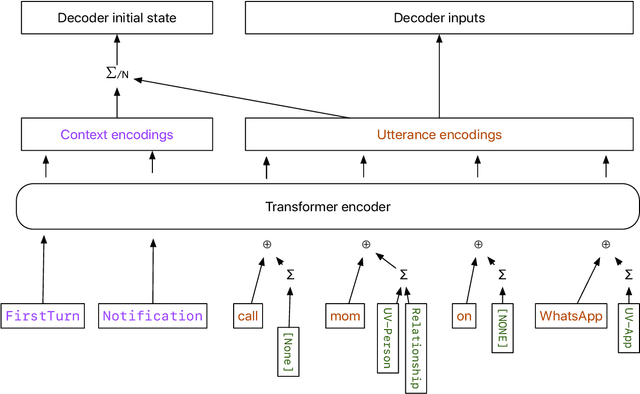
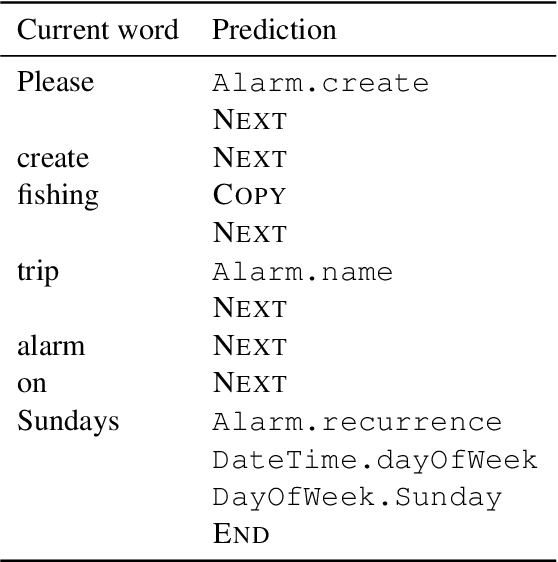

It has recently become feasible to run personal digital assistants on phones and other personal devices. In this paper we describe a design for a natural language understanding system that runs on device. In comparison to a server-based assistant, this system is more private, more reliable, faster, more expressive, and more accurate. We describe what led to key choices about architecture and technologies. For example, some approaches in the dialog systems literature are difficult to maintain over time in a deployment setting. We hope that sharing learnings from our practical experiences may help inform future work in the research community.
Feedback Effect in User Interaction with Intelligent Assistants: Delayed Engagement, Adaption and Drop-out
Mar 17, 2023With the growing popularity of intelligent assistants (IAs), evaluating IA quality becomes an increasingly active field of research. This paper identifies and quantifies the feedback effect, a novel component in IA-user interactions: how the capabilities and limitations of the IA influence user behavior over time. First, we demonstrate that unhelpful responses from the IA cause users to delay or reduce subsequent interactions in the short term via an observational study. Next, we expand the time horizon to examine behavior changes and show that as users discover the limitations of the IA's understanding and functional capabilities, they learn to adjust the scope and wording of their requests to increase the likelihood of receiving a helpful response from the IA. Our findings highlight the impact of the feedback effect at both the micro and meso levels. We further discuss its macro-level consequences: unsatisfactory interactions continuously reduce the likelihood and diversity of future user engagements in a feedback loop.
Using Pause Information for More Accurate Entity Recognition
Sep 27, 2021
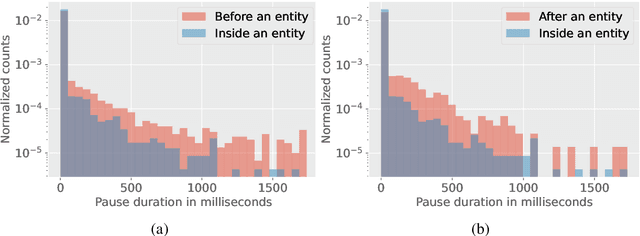

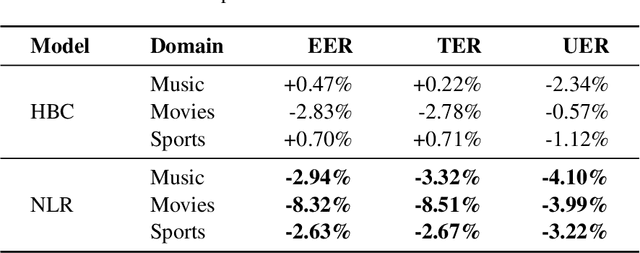
Entity tags in human-machine dialog are integral to natural language understanding (NLU) tasks in conversational assistants. However, current systems struggle to accurately parse spoken queries with the typical use of text input alone, and often fail to understand the user intent. Previous work in linguistics has identified a cross-language tendency for longer speech pauses surrounding nouns as compared to verbs. We demonstrate that the linguistic observation on pauses can be used to improve accuracy in machine-learnt language understanding tasks. Analysis of pauses in French and English utterances from a commercial voice assistant shows the statistically significant difference in pause duration around multi-token entity span boundaries compared to within entity spans. Additionally, in contrast to text-based NLU, we apply pause duration to enrich contextual embeddings to improve shallow parsing of entities. Results show that our proposed novel embeddings improve the relative error rate by up to 8% consistently across three domains for French, without any added annotation or alignment costs to the parser.
DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition in Virtual Assistants
Aug 15, 2021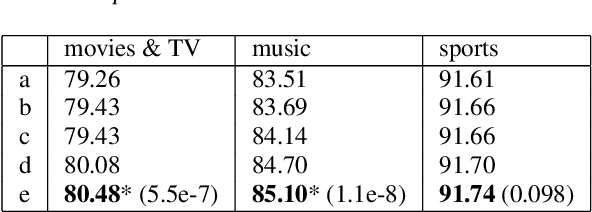
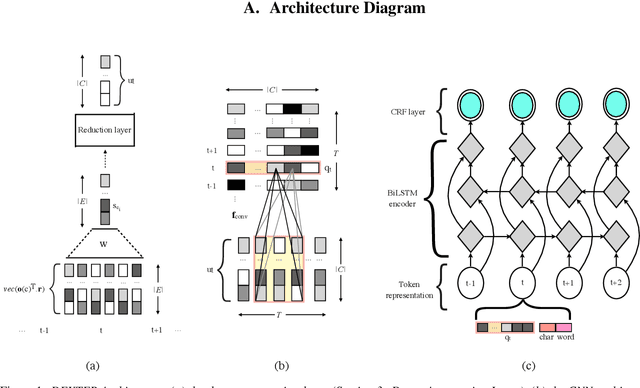
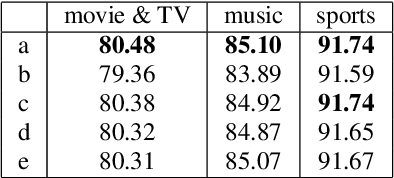
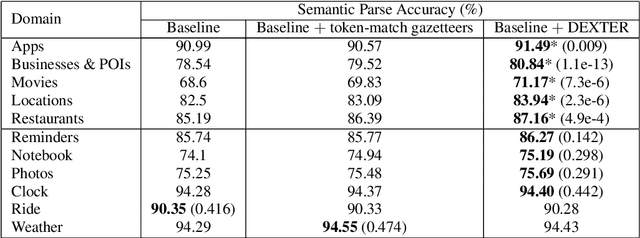
Named entity recognition (NER) is usually developed and tested on text from well-written sources. However, in intelligent voice assistants, where NER is an important component, input to NER may be noisy because of user or speech recognition error. In applications, entity labels may change frequently, and non-textual properties like topicality or popularity may be needed to choose among alternatives. We describe a NER system intended to address these problems. We test and train this system on a proprietary user-derived dataset. We compare with a baseline text-only NER system; the baseline enhanced with external gazetteers; and the baseline enhanced with the search and indirect labelling techniques we describe below. The final configuration gives around 6% reduction in NER error rate. We also show that this technique improves related tasks, such as semantic parsing, with an improvement of up to 5% in error rate.
Open-Domain Question Answering Goes Conversational via Question Rewriting
Oct 10, 2020

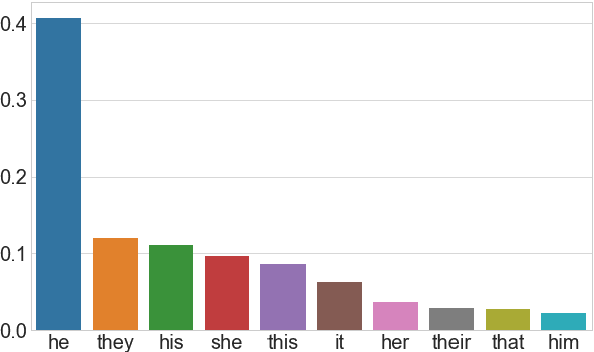
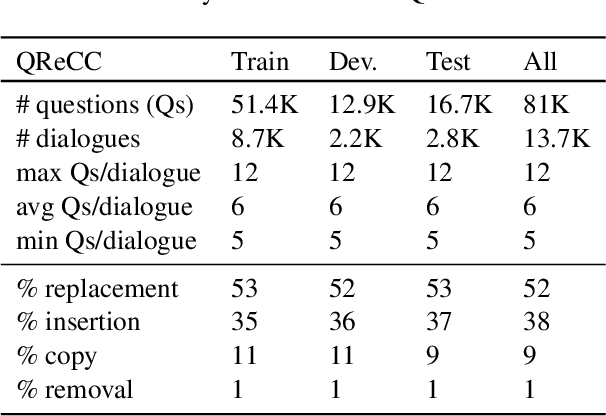
We introduce a new dataset for Question Rewriting in Conversational Context (QReCC), which contains 14K conversations with 81K question-answer pairs. The task in QReCC is to find answers to conversational questions within a collection of 10M web pages (split into 54M passages). Answers to questions in the same conversation may be distributed across several web pages. QReCC provides annotations that allow us to train and evaluate individual subtasks of question rewriting, passage retrieval and reading comprehension required for the end-to-end conversational question answering (QA) task. We report the effectiveness of a strong baseline approach that combines the state-of-the-art model for question rewriting, and competitive models for open-domain QA. Our results set the first baseline for the QReCC dataset with F1 of 19.07, compared to the human upper bound of 74.47, indicating the difficulty of the setup and a large room for improvement.
Noise-robust Named Entity Understanding for Virtual Assistants
May 29, 2020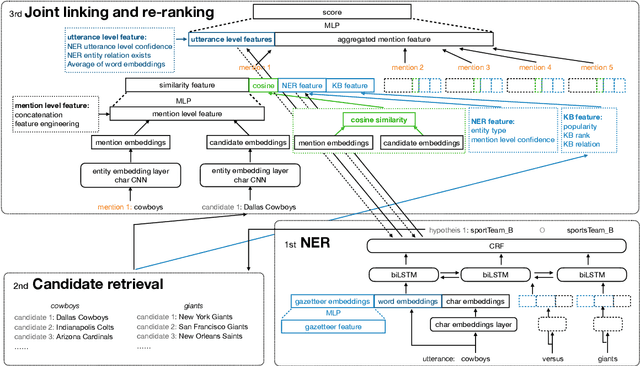
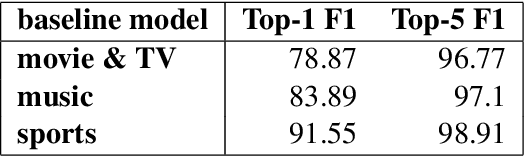
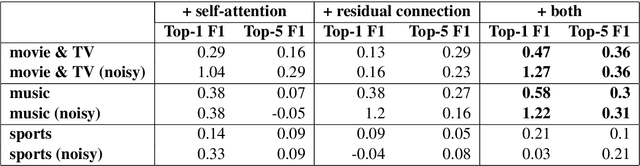
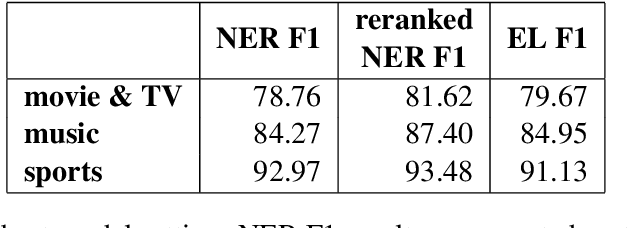
Named Entity Understanding (NEU) plays an essential role in interactions between users and voice assistants, since successfully identifying entities and correctly linking them to their standard forms is crucial to understanding the user's intent. NEU is a challenging task in voice assistants due to the ambiguous nature of natural language and because noise introduced by speech transcription and user errors occur frequently in spoken natural language queries. In this paper, we propose an architecture with novel features that jointly solves the recognition of named entities (a.k.a. Named Entity Recognition, or NER) and the resolution to their canonical forms (a.k.a. Entity Linking, or EL). We show that by combining NER and EL information in a joint reranking module, our proposed framework improves accuracy in both tasks. This improved performance and the features that enable it, also lead to better accuracy in downstream tasks, such as domain classification and semantic parsing.
Generalized Reinforcement Meta Learning for Few-Shot Optimization
May 04, 2020
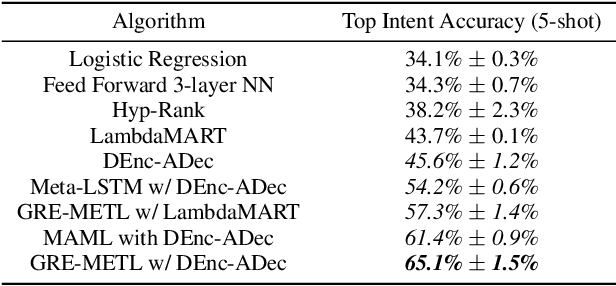
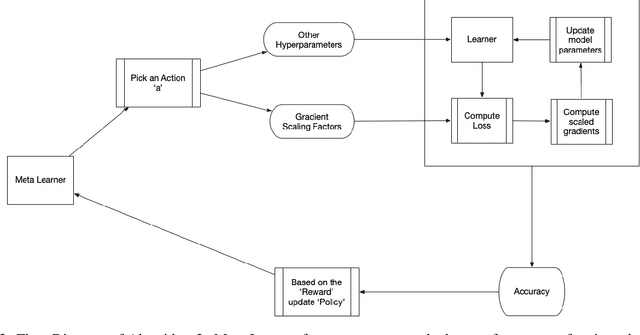

We present a generic and flexible Reinforcement Learning (RL) based meta-learning framework for the problem of few-shot learning. During training, it learns the best optimization algorithm to produce a learner (ranker/classifier, etc) by exploiting stable patterns in loss surfaces. Our method implicitly estimates the gradients of a scaled loss function while retaining the general properties intact for parameter updates. Besides providing improved performance on few-shot tasks, our framework could be easily extended to do network architecture search. We further propose a novel dual encoder, affinity-score based decoder topology that achieves additional improvements to performance. Experiments on an internal dataset, MQ2007, and AwA2 show our approach outperforms existing alternative approaches by 21%, 8%, and 4% respectively on accuracy and NDCG metrics. On Mini-ImageNet dataset our approach achieves comparable results with Prototypical Networks. Empirical evaluations demonstrate that our approach provides a unified and effective framework.
Lattice-based Improvements for Voice Triggering Using Graph Neural Networks
Jan 25, 2020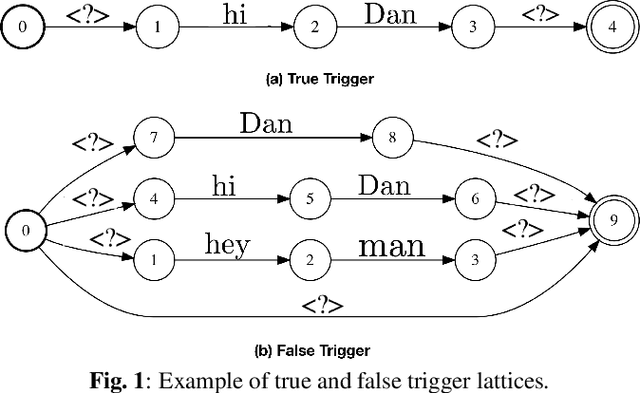
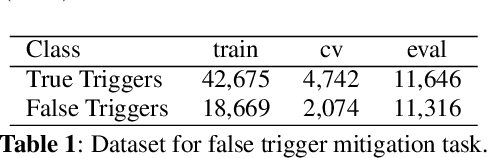
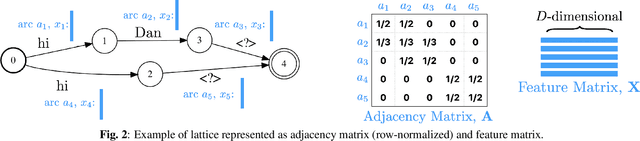

Voice-triggered smart assistants often rely on detection of a trigger-phrase before they start listening for the user request. Mitigation of false triggers is an important aspect of building a privacy-centric non-intrusive smart assistant. In this paper, we address the task of false trigger mitigation (FTM) using a novel approach based on analyzing automatic speech recognition (ASR) lattices using graph neural networks (GNN). The proposed approach uses the fact that decoding lattice of a falsely triggered audio exhibits uncertainties in terms of many alternative paths and unexpected words on the lattice arcs as compared to the lattice of a correctly triggered audio. A pure trigger-phrase detector model doesn't fully utilize the intent of the user speech whereas by using the complete decoding lattice of user audio, we can effectively mitigate speech not intended for the smart assistant. We deploy two variants of GNNs in this paper based on 1) graph convolution layers and 2) self-attention mechanism respectively. Our experiments demonstrate that GNNs are highly accurate in FTM task by mitigating ~87% of false triggers at 99% true positive rate (TPR). Furthermore, the proposed models are fast to train and efficient in parameter requirements.
Leveraging User Engagement Signals For Entity Labeling in a Virtual Assistant
Sep 18, 2019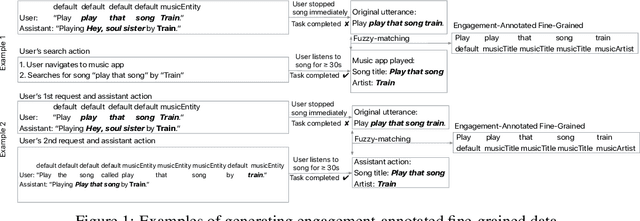
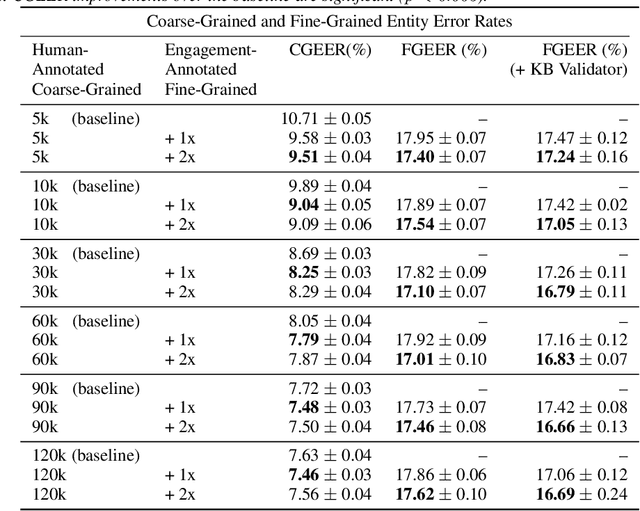
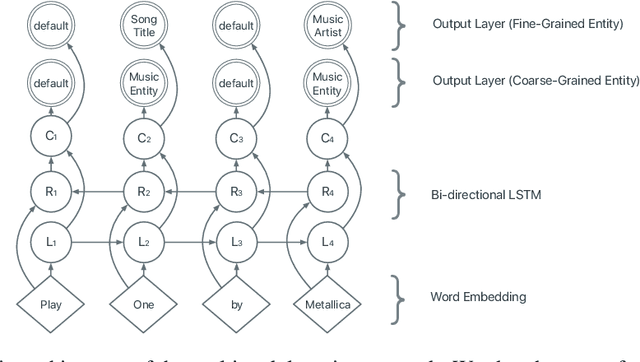
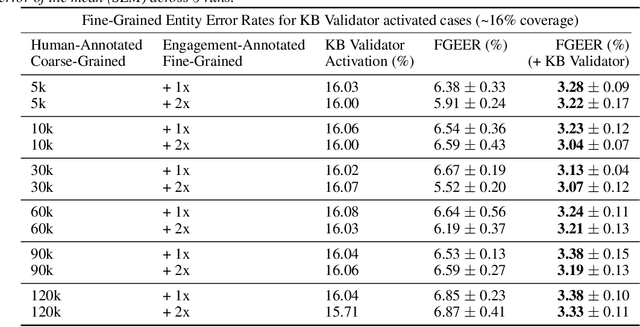
Personal assistant AI systems such as Siri, Cortana, and Alexa have become widely used as a means to accomplish tasks through natural language commands. However, components in these systems generally rely on supervised machine learning algorithms that require large amounts of hand-annotated training data, which is expensive and time consuming to collect. The ability to incorporate unsupervised, weakly supervised, or distantly supervised data holds significant promise in overcoming this bottleneck. In this paper, we describe a framework that leverages user engagement signals (user behaviors that demonstrate a positive or negative response to content) to automatically create granular entity labels for training data augmentation. Strategies such as multi-task learning and validation using an external knowledge base are employed to incorporate the engagement annotated data and to boost the model's accuracy on a sequence labeling task. Our results show that learning from data automatically labeled by user engagement signals achieves significant accuracy gains in a production deep learning system, when measured on both the sequence labeling task as well as on user facing results produced by the system end-to-end. We believe this is the first use of user engagement signals to help generate training data for a sequence labeling task on a large scale, and can be applied in practical settings to speed up new feature deployment when little human annotated data is available.
Active Learning for Domain Classification in a Commercial Spoken Personal Assistant
Aug 29, 2019
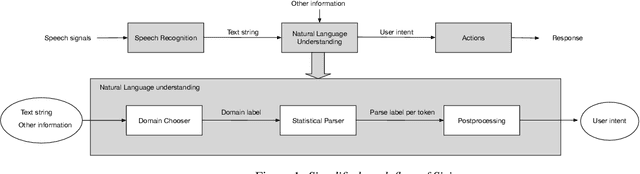
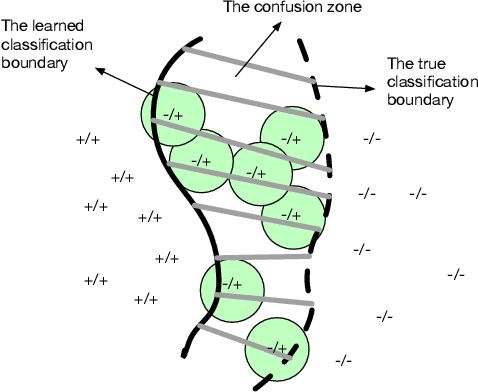
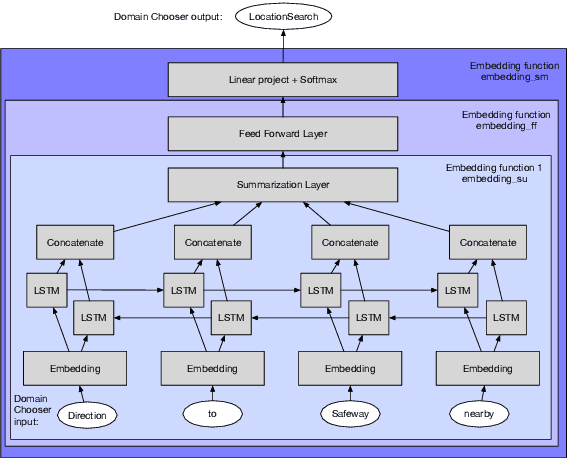
We describe a method for selecting relevant new training data for the LSTM-based domain selection component of our personal assistant system. Adding more annotated training data for any ML system typically improves accuracy, but only if it provides examples not already adequately covered in the existing data. However, obtaining, selecting, and labeling relevant data is expensive. This work presents a simple technique that automatically identifies new helpful examples suitable for human annotation. Our experimental results show that the proposed method, compared with random-selection and entropy-based methods, leads to higher accuracy improvements given a fixed annotation budget. Although developed and tested in the setting of a commercial intelligent assistant, the technique is of wider applicability.