 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEXTER: Deep Encoding of External Knowledge for Named Entity Recognition in Virtual Assistants
Aug 15, 2021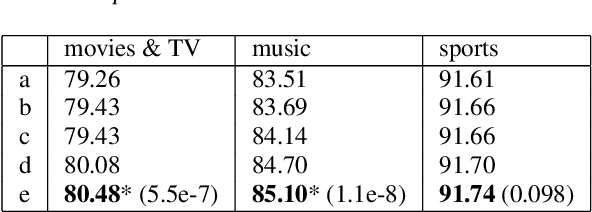
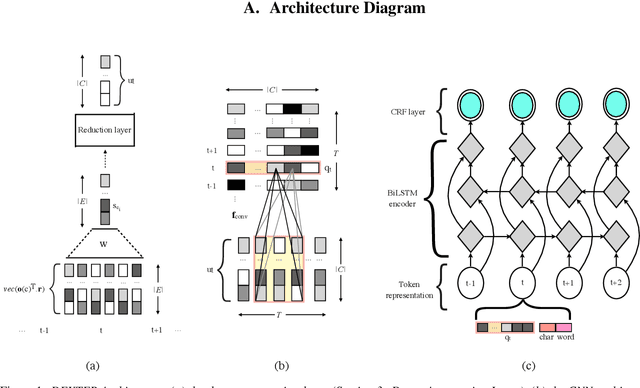
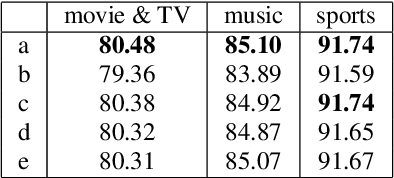
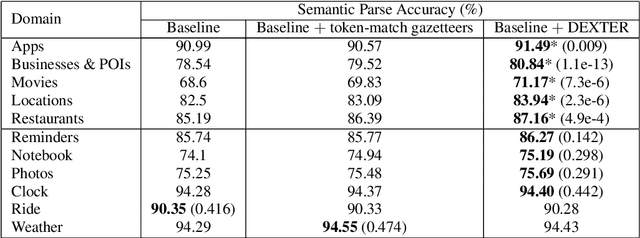
Named entity recognition (NER) is usually developed and tested on text from well-written sources. However, in intelligent voice assistants, where NER is an important component, input to NER may be noisy because of user or speech recognition error. In applications, entity labels may change frequently, and non-textual properties like topicality or popularity may be needed to choose among alternatives. We describe a NER system intended to address these problems. We test and train this system on a proprietary user-derived dataset. We compare with a baseline text-only NER system; the baseline enhanced with external gazetteers; and the baseline enhanced with the search and indirect labelling techniques we describe below. The final configuration gives around 6% reduction in NER error rate. We also show that this technique improves related tasks, such as semantic parsing, with an improvement of up to 5% in error rate.
Noise-robust Named Entity Understanding for Virtual Assistants
May 29, 2020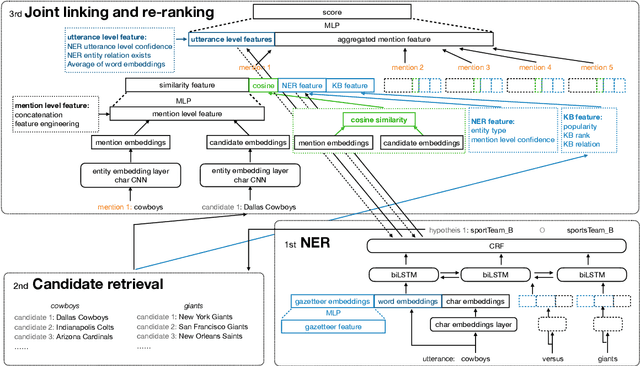
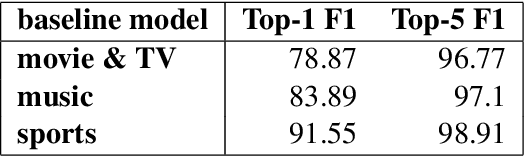
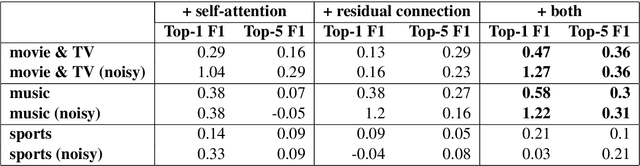
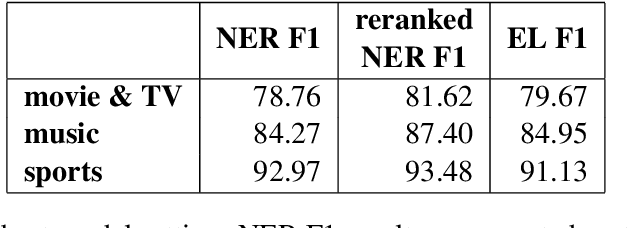
Named Entity Understanding (NEU) plays an essential role in interactions between users and voice assistants, since successfully identifying entities and correctly linking them to their standard forms is crucial to understanding the user's intent. NEU is a challenging task in voice assistants due to the ambiguous nature of natural language and because noise introduced by speech transcription and user errors occur frequently in spoken natural language queries. In this paper, we propose an architecture with novel features that jointly solves the recognition of named entities (a.k.a. Named Entity Recognition, or NER) and the resolution to their canonical forms (a.k.a. Entity Linking, or EL). We show that by combining NER and EL information in a joint reranking module, our proposed framework improves accuracy in both tasks. This improved performance and the features that enable it, also lead to better accuracy in downstream tasks, such as domain classification and semantic parsing.
Leveraging User Engagement Signals For Entity Labeling in a Virtual Assistant
Sep 18, 2019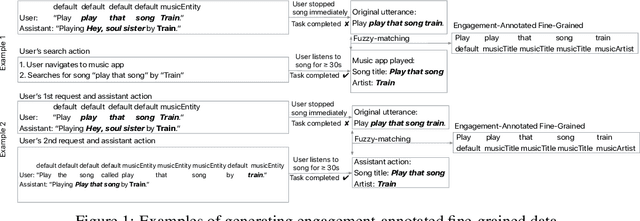
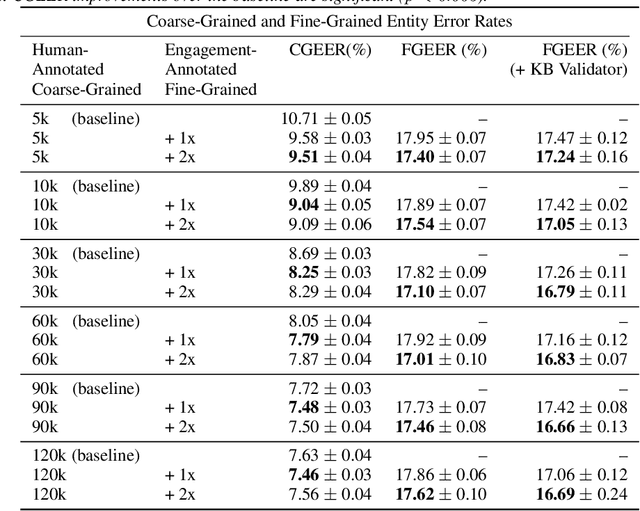
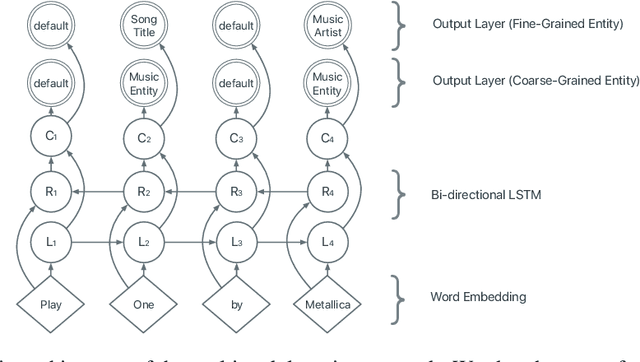
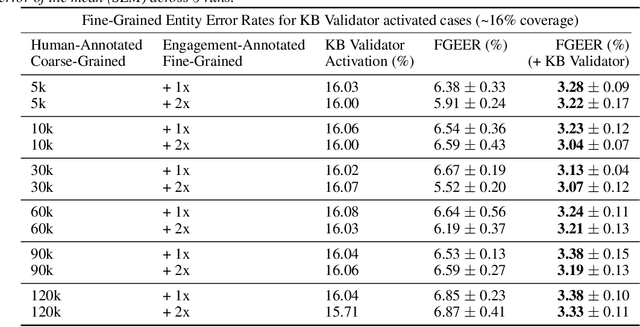
Personal assistant AI systems such as Siri, Cortana, and Alexa have become widely used as a means to accomplish tasks through natural language commands. However, components in these systems generally rely on supervised machine learning algorithms that require large amounts of hand-annotated training data, which is expensive and time consuming to collect. The ability to incorporate unsupervised, weakly supervised, or distantly supervised data holds significant promise in overcoming this bottleneck. In this paper, we describe a framework that leverages user engagement signals (user behaviors that demonstrate a positive or negative response to content) to automatically create granular entity labels for training data augmentation. Strategies such as multi-task learning and validation using an external knowledge base are employed to incorporate the engagement annotated data and to boost the model's accuracy on a sequence labeling task. Our results show that learning from data automatically labeled by user engagement signals achieves significant accuracy gains in a production deep learning system, when measured on both the sequence labeling task as well as on user facing results produced by the system end-to-end. We believe this is the first use of user engagement signals to help generate training data for a sequence labeling task on a large scale, and can be applied in practical settings to speed up new feature deployment when little human annotated data is available.