 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Dynamic Situational Awareness in Human Robot Teams: An Interview Study
Jan 15, 2025



In human-robot teams, human situational awareness is the operator's conscious knowledge of the team's states, actions, plans and their environment. Appropriate human situational awareness is critical to successful human-robot collaboration. In human-robot teaming, it is often assumed that the best and required level of situational awareness is knowing everything at all times. This view is problematic, because what a human needs to know for optimal team performance varies given the dynamic environmental conditions, task context and roles and capabilities of team members. We explore this topic by interviewing 16 participants with active and repeated experience in diverse human-robot teaming applications. Based on analysis of these interviews, we derive a framework explaining the dynamic nature of required situational awareness in human-robot teaming. In addition, we identify a range of factors affecting the dynamic nature of required and actual levels of situational awareness (i.e., dynamic situational awareness), types of situational awareness inefficiencies resulting from gaps between actual and required situational awareness, and their main consequences. We also reveal various strategies, initiated by humans and robots, that assist in maintaining the required situational awareness. Our findings inform the implementation of accurate estimates of dynamic situational awareness and the design of user-adaptive human-robot interfaces. Therefore, this work contributes to the future design of more collaborative and effective human-robot teams.
Alternative Interfaces for Human-initiated Natural Language Communication and Robot-initiated Haptic Feedback: Towards Better Situational Awareness in Human-Robot Collaboration
Jan 25, 2024This article presents an implementation of a natural-language speech interface and a haptic feedback interface that enables a human supervisor to provide guidance to, request information, and receive status updates from a Spot robot. We provide insights gained during preliminary user testing of the interface in a realistic robot exploration scenario.
Learning to Simulate Tree-Branch Dynamics for Manipulation
Jun 06, 2023We propose to use a simulation driven inverse inference approach to model the joint dynamics of tree branches under manipulation. Learning branch dynamics and gaining the ability to manipulate deformable vegetation can help with occlusion-prone tasks, such as fruit picking in dense foliage, as well as moving overhanging vines and branches for navigation in dense vegetation. The underlying deformable tree geometry is encapsulated as coarse spring abstractions executed on parallel, non-differentiable simulators. The implicit statistical model defined by the simulator, reference trajectories obtained by actively probing the ground truth, and the Bayesian formalism, together guide the spring parameter posterior density estimation. Our non-parametric inference algorithm, based on Stein Variational Gradient Descent, incorporates biologically motivated assumptions into the inference process as neural network driven learnt joint priors; moreover, it leverages the finite difference scheme for gradient approximations. Real and simulated experiments confirm that our model can predict deformation trajectories, quantify the estimation uncertainty, and it can perform better when base-lined against other inference algorithms, particularly from the Monte Carlo family. The model displays strong robustness properties in the presence of heteroscedastic sensor noise; furthermore, it can generalise to unseen grasp locations.
Heterogeneous robot teams with unified perception and autonomy: How Team CSIRO Data61 tied for the top score at the DARPA Subterranean Challenge
Feb 26, 2023



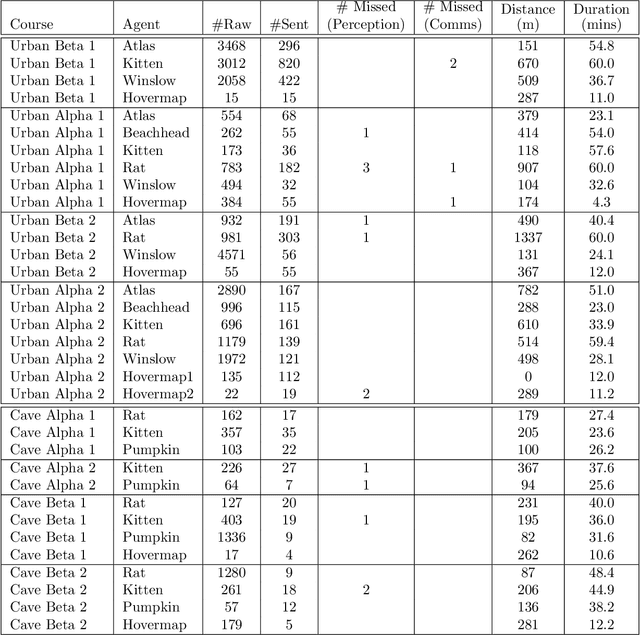
The DARPA Subterranean Challenge was designed for competitors to develop and deploy teams of autonomous robots to explore difficult unknown underground environments. Categorised in to human-made tunnels, underground urban infrastructure and natural caves, each of these subdomains had many challenging elements for robot perception, locomotion, navigation and autonomy. These included degraded wireless communication, poor visibility due to smoke, narrow passages and doorways, clutter, uneven ground, slippery and loose terrain, stairs, ledges, overhangs, dripping water, and dynamic obstacles that move to block paths among others. In the Final Event of this challenge held in September 2021, the course consisted of all three subdomains. The task was for the robot team to perform a scavenger hunt for a number of pre-defined artefacts within a limited time frame. Only one human supervisor was allowed to communicate with the robots once they were in the course. Points were scored when accurate detections and their locations were communicated back to the scoring server. A total of 8 teams competed in the finals held at the Mega Cavern in Louisville, KY, USA. This article describes the systems deployed by Team CSIRO Data61 that tied for the top score and won second place at the event.
Human-Robot Team Performance Compared to Full Robot Autonomy in 16 Real-World Search and Rescue Missions: Adaptation of the DARPA Subterranean Challenge
Dec 11, 2022
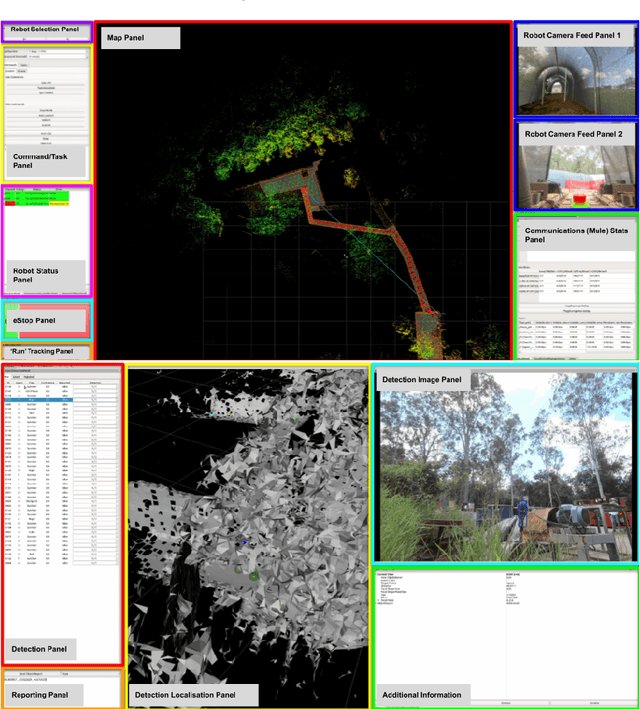
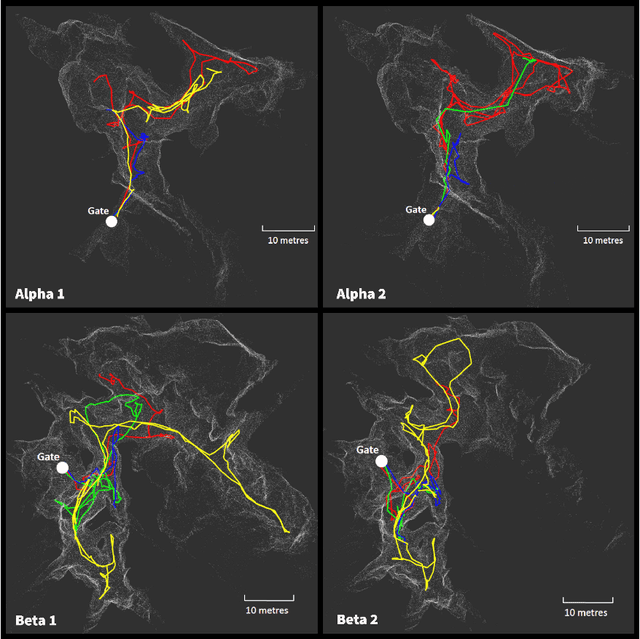

Human operators in human-robot teams are commonly perceived to be critical for mission success. To explore the direct and perceived impact of operator input on task success and team performance, 16 real-world missions (10 hrs) were conducted based on the DARPA Subterranean Challenge. These missions were to deploy a heterogeneous team of robots for a search task to locate and identify artifacts such as climbing rope, drills and mannequins representing human survivors. Two conditions were evaluated: human operators that could control the robot team with state-of-the-art autonomy (Human-Robot Team) compared to autonomous missions without human operator input (Robot-Autonomy). Human-Robot Teams were often in directed autonomy mode (70% of mission time), found more items, traversed more distance, covered more unique ground, and had a higher time between safety-related events. Human-Robot Teams were faster at finding the first artifact, but slower to respond to information from the robot team. In routine conditions, scores were comparable for artifacts, distance, and coverage. Reasons for intervention included creating waypoints to prioritise high-yield areas, and to navigate through error-prone spaces. After observing robot autonomy, operators reported increases in robot competency and trust, but that robot behaviour was not always transparent and understandable, even after high mission performance.
Wildcat: Online Continuous-Time 3D Lidar-Inertial SLAM
May 25, 2022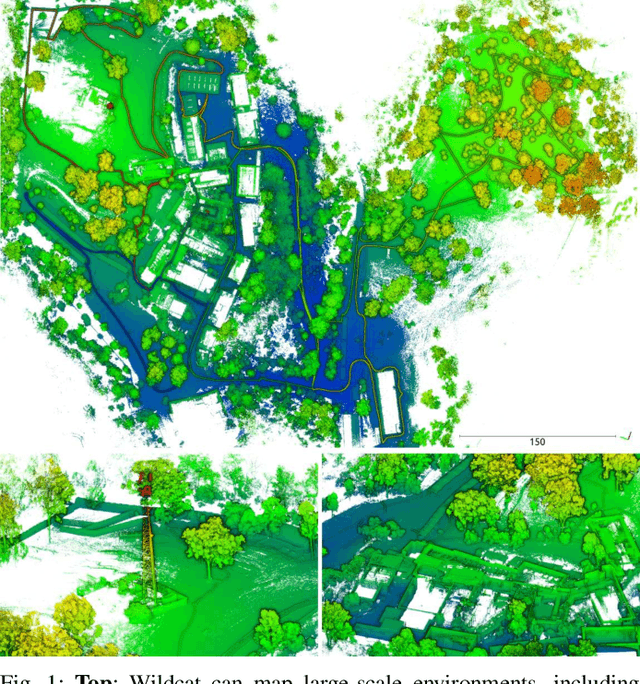
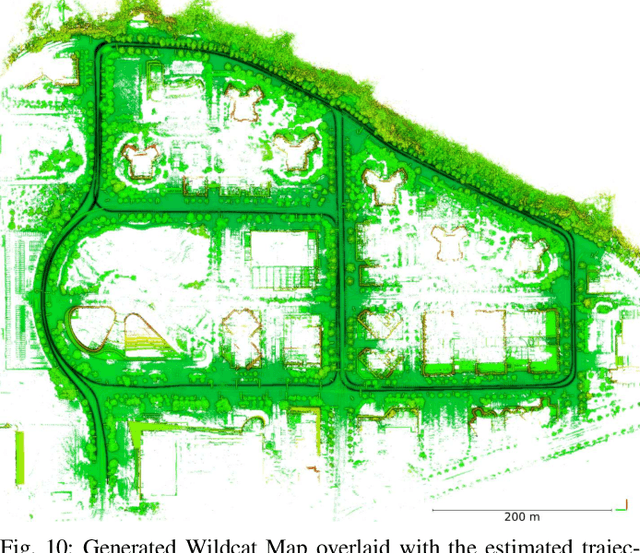
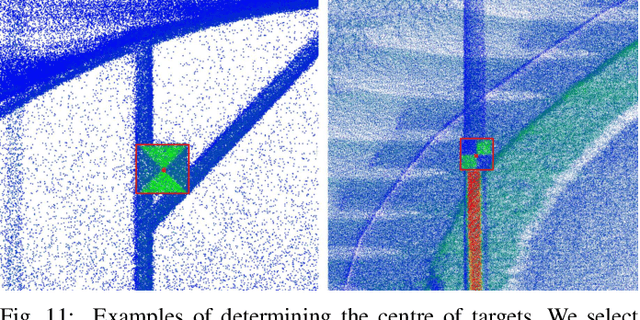
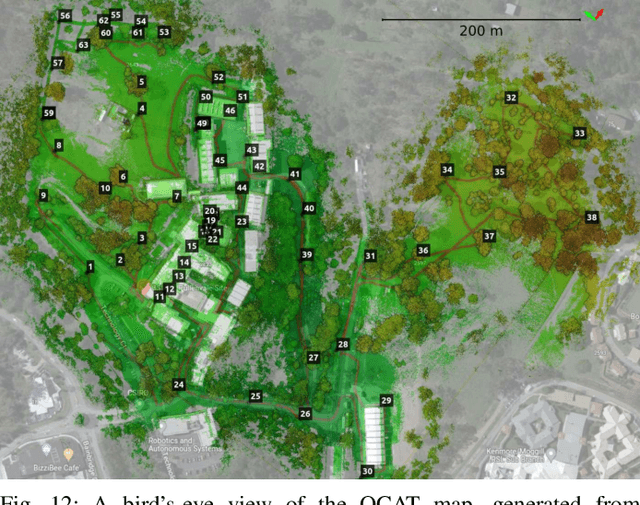
We present Wildcat, a novel online 3D lidar-inertial SLAM system with exceptional versatility and robustness. At its core, Wildcat combines a robust real-time lidar-inertial odometry module, utilising a continuous-time trajectory representation, with an efficient pose-graph optimisation module that seamlessly supports both the single- and multi-agent settings. The robustness of Wildcat was recently demonstrated in the DARPA Subterranean Challenge where it outperformed other SLAM systems across various types of sensing-degraded and perceptually challenging environments. In this paper, we extensively evaluate Wildcat in a diverse set of new and publicly available real-world datasets and showcase its superior robustness and versatility over two existing state-of-the-art lidar-inertial SLAM systems.
DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition in Virtual Assistants
Aug 15, 2021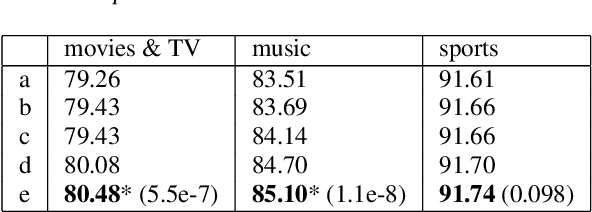
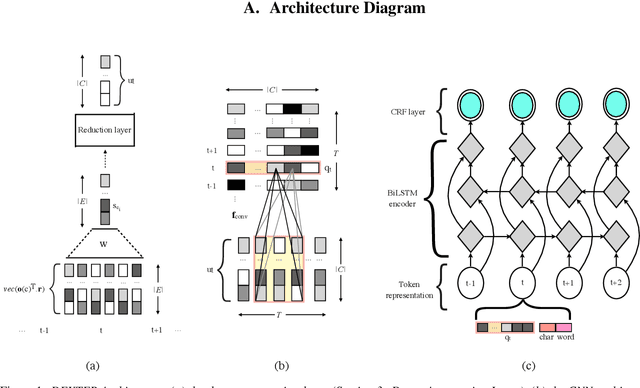
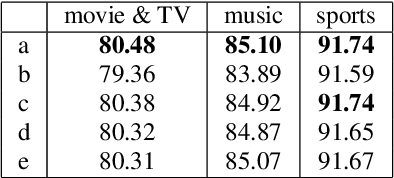
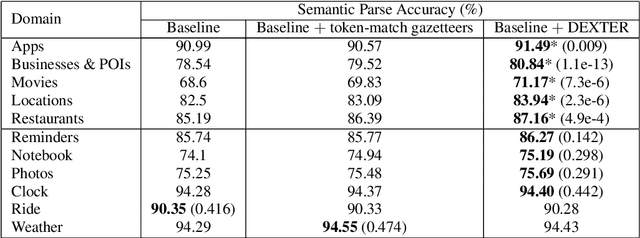
Named entity recognition (NER) is usually developed and tested on text from well-written sources. However, in intelligent voice assistants, where NER is an important component, input to NER may be noisy because of user or speech recognition error. In applications, entity labels may change frequently, and non-textual properties like topicality or popularity may be needed to choose among alternatives. We describe a NER system intended to address these problems. We test and train this system on a proprietary user-derived dataset. We compare with a baseline text-only NER system; the baseline enhanced with external gazetteers; and the baseline enhanced with the search and indirect labelling techniques we describe below. The final configuration gives around 6% reduction in NER error rate. We also show that this technique improves related tasks, such as semantic parsing, with an improvement of up to 5% in error rate.
Heterogeneous Ground and Air Platforms, Homogeneous Sensing: Team CSIRO Data61's Approach to the DARPA Subterranean Challenge
Apr 19, 2021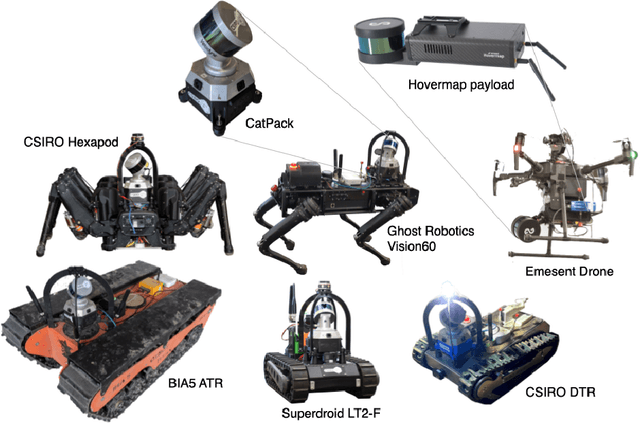
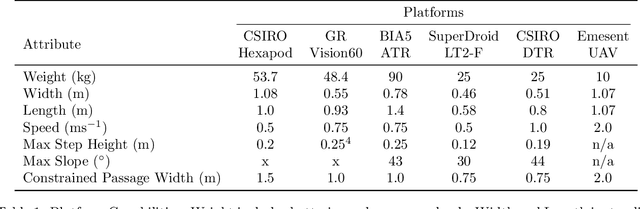
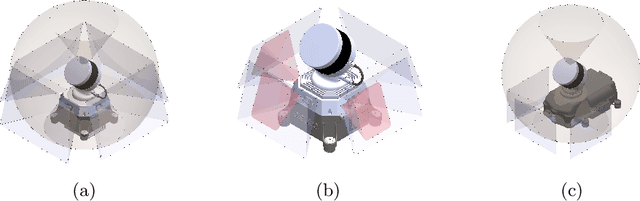
Heterogeneous teams of robots, leveraging a balance between autonomy and human interaction, bring powerful capabilities to the problem of exploring dangerous, unstructured subterranean environments. Here we describe the solution developed by Team CSIRO Data61, consisting of CSIRO, Emesent and Georgia Tech, during the DARPA Subterranean Challenge. These presented systems were fielded in the Tunnel Circuit in August 2019, the Urban Circuit in February 2020, and in our own Cave event, conducted in September 2020. A unique capability of the fielded team is the homogeneous sensing of the platforms utilised, which is leveraged to obtain a decentralised multi-agent SLAM solution on each platform (both ground agents and UAVs) using peer-to-peer communications. This enabled a shift in focus from constructing a pervasive communications network to relying on multi-agent autonomy, motivated by experiences in early circuit events. These experiences also showed the surprising capability of rugged tracked platforms for challenging terrain, which in turn led to the heterogeneous team structure based on a BIA5 OzBot Titan ground robot and an Emesent Hovermap UAV, supplemented by smaller tracked or legged ground robots. The ground agents use a common CatPack perception module, which allowed reuse of the perception and autonomy stack across all ground agents with minimal adaptation.
Generating Natural Questions from Images for Multimodal Assistants
Nov 17, 2020
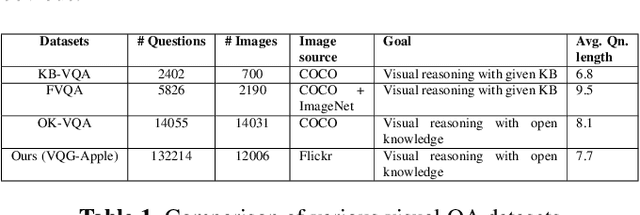

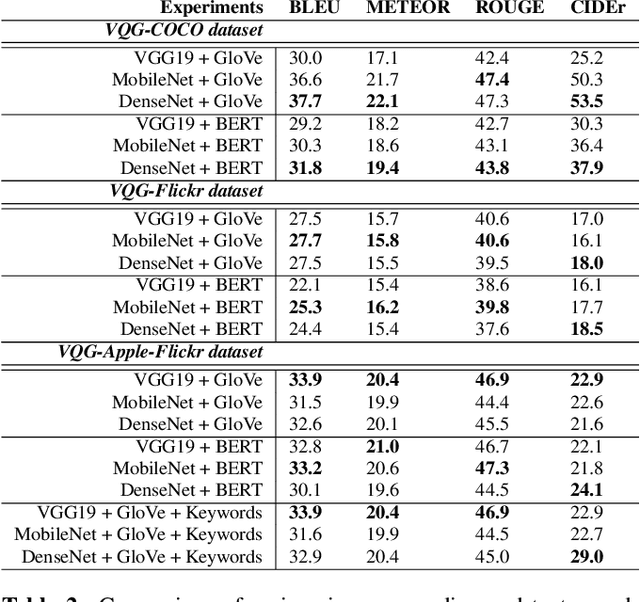
Generating natural, diverse, and meaningful questions from images is an essential task for multimodal assistants as it confirms whether they have understood the object and scene in the images properly. The research in visual question answering (VQA) and visual question generation (VQG) is a great step. However, this research does not capture questions that a visually-abled person would ask multimodal assistants. Recently published datasets such as KB-VQA, FVQA, and OK-VQA try to collect questions that look for external knowledge which makes them appropriate for multimodal assistants. However, they still contain many obvious and common-sense questions that humans would not usually ask a digital assistant. In this paper, we provide a new benchmark dataset that contains questions generated by human annotators keeping in mind what they would ask multimodal digital assistants. Large scale annotations for several hundred thousand images are expensive and time-consuming, so we also present an effective way of automatically generating questions from unseen images. In this paper, we present an approach for generating diverse and meaningful questions that consider image content and metadata of image (e.g., location, associated keyword). We evaluate our approach using standard evaluation metrics such as BLEU, METEOR, ROUGE, and CIDEr to show the relevance of generated questions with human-provided questions. We also measure the diversity of generated questions using generative strength and inventiveness metrics. We report new state-of-the-art results on the public and our datasets.
Elasticity Meets Continuous-Time: Map-Centric Dense 3D LiDAR SLAM
Aug 05, 2020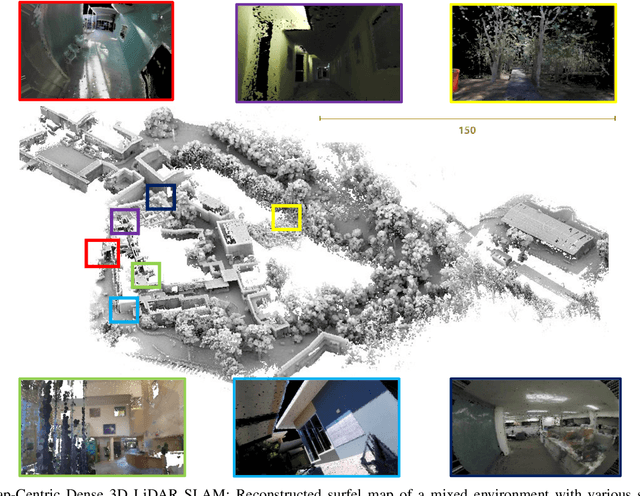

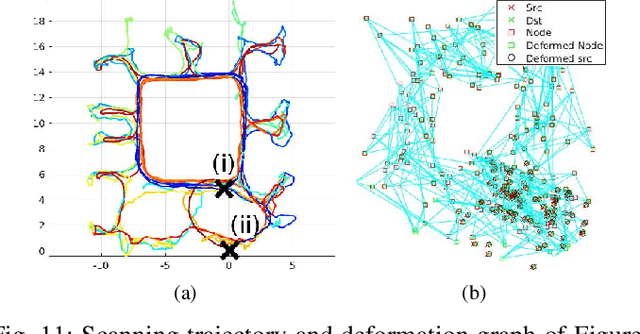
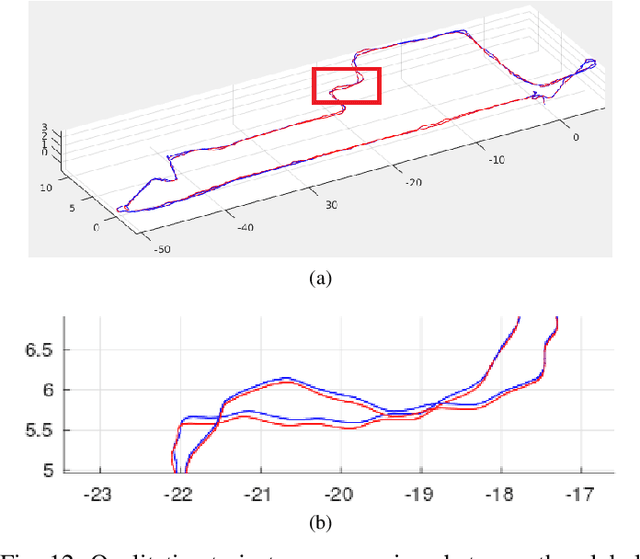
Map-centric SLAM utilizes elasticity as a means of loop closure. This approach reduces the cost of loop closure while still provides large-scale fusion-based dense maps, when compared to the trajectory-centric SLAM approaches. In this paper, we present a novel framework for 3D LiDAR-based map-centric SLAM. Having the advantages of a map-centric approach, our method exhibits new features to overcome the shortcomings of existing systems, associated with multi-modal sensor fusion and LiDAR motion distortion. This is accomplished through the use of a local Continuous-Time (CT) trajectory representation. Also, our surface resolution preservative matching algorithm and Wishart-based surfel fusion model enables non-redundant yet dense mapping. Furthermore, we present a robust metric loop closure model to make the approach stable regardless of where the loop closure occurs. Finally, we demonstrate our approach through both simulation and real data experiments using multiple sensor payload configurations and environments to illustrate its utility and robustness.