 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorVLA: Anchored Diffusion for Efficient End-to-End Mobile Manipulation
Apr 02, 2026A central challenge in mobile manipulation is preserving multiple plausible action models while remaining reactive during execution. A bottle in a cluttered scene can often be approached and grasped in multiple valid ways. Robust behavior depends on preserving this action diversity while remaining reactive as the scene evolves. Diffusion policies are appealing because they model multimodal action distributions rather than collapsing to one solution. But in practice, full iterative denoising is costly at control time. Action chunking helps amortize inference, yet it also creates partially open-loop behavior, allowing small mismatches to accumulate into drift. We present AnchorVLA, a diffusion-based VLA policy for mobile manipulation built on the core insight that when sampling begins near a plausible solution manifold, extensive denoising is unnecessary to recover multimodal, valid actions. AnchorVLA combines a lightweight VLA adaptation backbone with an anchored diffusion action head, which denoises locally around anchor trajectories using a truncated diffusion schedule. This retains multimodal action generation while reducing inference cost for closed-loop control. Crucially, to mitigate chunking-induced drift, we introduce a test-time self-correction mechanism via a lightweight residual correction module that makes high-frequency, per-step adjustments during rollout. Across diverse mobile manipulation tasks, AnchorVLA improves success and stability under disturbances and distribution shifts while maintaining low-latency inference. The source code is made available at https://github.com/jason-lim26/AnchorVLA.
SPREAD: Subspace Representation Distillation for Lifelong Imitation Learning
Mar 09, 2026A key challenge in lifelong imitation learning (LIL) is enabling agents to acquire new skills from expert demonstrations while retaining prior knowledge. This requires preserving the low-dimensional manifolds and geometric structures that underlie task representations across sequential learning. Existing distillation methods, which rely on L2-norm feature matching in raw feature space, are sensitive to noise and high-dimensional variability, often failing to preserve intrinsic task manifolds. To address this, we introduce SPREAD, a geometry-preserving framework that employs singular value decomposition (SVD) to align policy representations across tasks within low-rank subspaces. This alignment maintains the underlying geometry of multimodal features, facilitating stable transfer, robustness, and generalization. Additionally, we propose a confidence-guided distillation strategy that applies a Kullback-Leibler divergence loss restricted to the top-M most confident action samples, emphasizing reliable modes and improving optimization stability. Experiments on the LIBERO, lifelong imitation learning benchmark, show that SPREAD substantially improves knowledge transfer, mitigates catastrophic forgetting, and achieves state-of-the-art performance.
RAPT: Model-Predictive Out-of-Distribution Detection and Failure Diagnosis for Sim-to-Real Humanoid Robots
Feb 02, 2026Deploying learned control policies on humanoid robots is challenging: policies that appear robust in simulation can execute confidently in out-of-distribution (OOD) states after Sim-to-Real transfer, leading to silent failures that risk hardware damage. Although anomaly detection can mitigate these failures, prior methods are often incompatible with high-rate control, poorly calibrated at the extremely low false-positive rates required for practical deployment, or operate as black boxes that provide a binary stop signal without explaining why the robot drifted from nominal behavior. We present RAPT, a lightweight, self-supervised deployment-time monitor for 50Hz humanoid control. RAPT learns a probabilistic spatio-temporal manifold of nominal execution from simulation and evaluates execution-time predictive deviation as a calibrated, per-dimension signal. This yields (i) reliable online OOD detection under strict false-positive constraints and (ii) a continuous, interpretable measure of Sim-to-Real mismatch that can be tracked over time to quantify how far deployment has drifted from training. Beyond detection, we introduce an automated post-hoc root-cause analysis pipeline that combines gradient-based temporal saliency derived from RAPT's reconstruction objective with LLM-based reasoning conditioned on saliency and joint kinematics to produce semantic failure diagnoses in a zero-shot setting. We evaluate RAPT on a Unitree G1 humanoid across four complex tasks in simulation and on physical hardware. In large-scale simulation, RAPT improves True Positive Rate (TPR) by 37% over the strongest baseline at a fixed episode-level false positive rate of 0.5%. On real-world deployments, RAPT achieves a 12.5% TPR improvement and provides actionable interpretability, reaching 75% root-cause classification accuracy across 16 real-world failures using only proprioceptive data.
Scalable Multi-Objective Robot Reinforcement Learning through Gradient Conflict Resolution
Sep 18, 2025Reinforcement Learning (RL) robot controllers usually aggregate many task objectives into one scalar reward. While large-scale proximal policy optimisation (PPO) has enabled impressive results such as robust robot locomotion in the real world, many tasks still require careful reward tuning and are brittle to local optima. Tuning cost and sub-optimality grow with the number of objectives, limiting scalability. Modelling reward vectors and their trade-offs can address these issues; however, multi-objective methods remain underused in RL for robotics because of computational cost and optimisation difficulty. In this work, we investigate the conflict between gradient contributions for each objective that emerge from scalarising the task objectives. In particular, we explicitly address the conflict between task-based rewards and terms that regularise the policy towards realistic behaviour. We propose GCR-PPO, a modification to actor-critic optimisation that decomposes the actor update into objective-wise gradients using a multi-headed critic and resolves conflicts based on the objective priority. Our methodology, GCR-PPO, is evaluated on the well-known IsaacLab manipulation and locomotion benchmarks and additional multi-objective modifications on two related tasks. We show superior scalability compared to parallel PPO (p = 0.04), without significant computational overhead. We also show higher performance with more conflicting tasks. GCR-PPO improves on large-scale PPO with an average improvement of 9.5%, with high-conflict tasks observing a greater improvement. The code is available at https://github.com/humphreymunn/GCR-PPO.
Improving Generalization Ability of Robotic Imitation Learning by Resolving Causal Confusion in Observations
Jul 30, 2025Recent developments in imitation learning have considerably advanced robotic manipulation. However, current techniques in imitation learning can suffer from poor generalization, limiting performance even under relatively minor domain shifts. In this work, we aim to enhance the generalization capabilities of complex imitation learning algorithms to handle unpredictable changes from the training environments to deployment environments. To avoid confusion caused by observations that are not relevant to the target task, we propose to explicitly learn the causal relationship between observation components and expert actions, employing a framework similar to [6], where a causal structural function is learned by intervention on the imitation learning policy. Disentangling the feature representation from image input as in [6] is hard to satisfy in complex imitation learning process in robotic manipulation, we theoretically clarify that this requirement is not necessary in causal relationship learning. Therefore, we propose a simple causal structure learning framework that can be easily embedded in recent imitation learning architectures, such as the Action Chunking Transformer [31]. We demonstrate our approach using a simulation of the ALOHA [31] bimanual robot arms in Mujoco, and show that the method can considerably mitigate the generalization problem of existing complex imitation learning algorithms.
Whole-Body Dynamic Throwing with Legged Manipulators
Oct 08, 2024



Most robotic behaviours focus on either manipulation or locomotion, where tasks that require the integration of both, such as full-body throwing, remain under-explored. Throwing with a robot involves complex coordination between object manipulation and legged locomotion, which is crucial for advanced real-world interactions. This work investigates the challenge of full-body throwing in robotic systems and highlights the advantages of utilising the robot's entire body. We propose a deep reinforcement learning (RL) approach that leverages the robot's body to enhance throwing performance through a strategically designed curriculum to avoid local optima and sparse but informative reward functions to improve policy flexibility. The robot's body learns to generate additional momentum and fine-tune the projectile release velocity. Our full-body method achieves on average 47% greater throwing distance and 34% greater throwing accuracy than the arm alone, across two robot morphologies - an armed quadruped and a humanoid. We also extend our method to optimise robot stability during throws. The learned policy effectively generalises throwing to targets at any 3D point in space within a specified range, which has not previously been achieved and does so with human-level throwing accuracy. We successfully transferred this approach from simulation to a real robot using sim2real techniques, demonstrating its practical viability.
Alternative Interfaces for Human-initiated Natural Language Communication and Robot-initiated Haptic Feedback: Towards Better Situational Awareness in Human-Robot Collaboration
Jan 25, 2024This article presents an implementation of a natural-language speech interface and a haptic feedback interface that enables a human supervisor to provide guidance to, request information, and receive status updates from a Spot robot. We provide insights gained during preliminary user testing of the interface in a realistic robot exploration scenario.
Robotic Vision for Human-Robot Interaction and Collaboration: A Survey and Systematic Review
Jul 28, 2023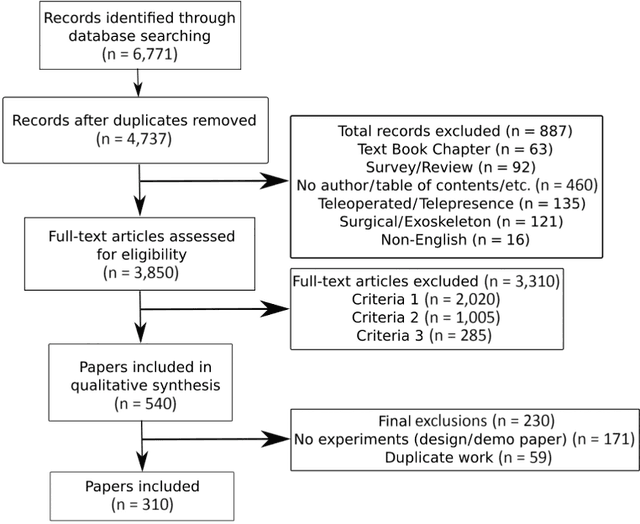

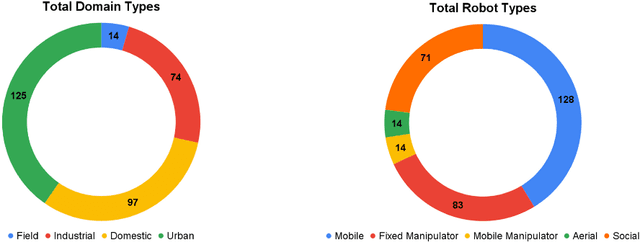
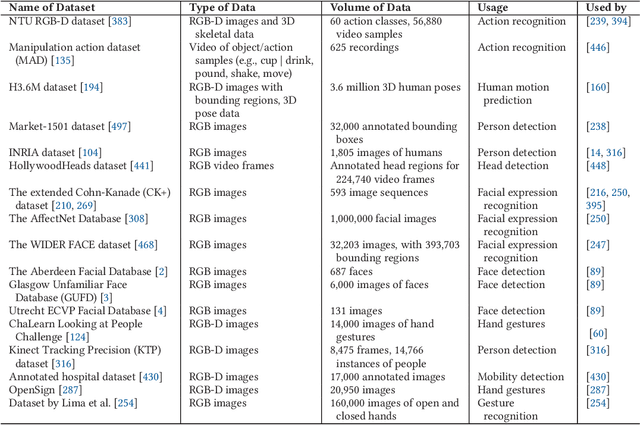
Robotic vision for human-robot interaction and collaboration is a critical process for robots to collect and interpret detailed information related to human actions, goals, and preferences, enabling robots to provide more useful services to people. This survey and systematic review presents a comprehensive analysis on robotic vision in human-robot interaction and collaboration over the last 10 years. From a detailed search of 3850 articles, systematic extraction and evaluation was used to identify and explore 310 papers in depth. These papers described robots with some level of autonomy using robotic vision for locomotion, manipulation and/or visual communication to collaborate or interact with people. This paper provides an in-depth analysis of current trends, common domains, methods and procedures, technical processes, data sets and models, experimental testing, sample populations, performance metrics and future challenges. This manuscript found that robotic vision was often used in action and gesture recognition, robot movement in human spaces, object handover and collaborative actions, social communication and learning from demonstration. Few high-impact and novel techniques from the computer vision field had been translated into human-robot interaction and collaboration. Overall, notable advancements have been made on how to develop and deploy robots to assist people.
Learning Visuo-Motor Behaviours for Robot Locomotion Over Difficult Terrain
Mar 02, 2023



As mobile robots become useful performing everyday tasks in complex real-world environments, they must be able to traverse a range of difficult terrain types such as stairs, stepping stones, gaps, jumps and narrow passages. This work investigated traversing these types of environments with a bipedal robot (simulation experiments), and a tracked robot (real world). Developing a traditional monolithic controller for traversing all terrain types is challenging, and for large physical robots realistic test facilities are required and safety must be ensured. An alternative is a suite of simple behaviour controllers that can be composed to achieve complex tasks. This work efficiently trained complex behaviours to enable mobile robots to traverse difficult terrain. By minimising retraining as new behaviours became available, robots were able to traverse increasingly complex terrain sets, leading toward the development of scalable behaviour libraries.
Heterogeneous robot teams with unified perception and autonomy: How Team CSIRO Data61 tied for the top score at the DARPA Subterranean Challenge
Feb 26, 2023



The DARPA Subterranean Challenge was designed for competitors to develop and deploy teams of autonomous robots to explore difficult unknown underground environments. Categorised in to human-made tunnels, underground urban infrastructure and natural caves, each of these subdomains had many challenging elements for robot perception, locomotion, navigation and autonomy. These included degraded wireless communication, poor visibility due to smoke, narrow passages and doorways, clutter, uneven ground, slippery and loose terrain, stairs, ledges, overhangs, dripping water, and dynamic obstacles that move to block paths among others. In the Final Event of this challenge held in September 2021, the course consisted of all three subdomains. The task was for the robot team to perform a scavenger hunt for a number of pre-defined artefacts within a limited time frame. Only one human supervisor was allowed to communicate with the robots once they were in the course. Points were scored when accurate detections and their locations were communicated back to the scoring server. A total of 8 teams competed in the finals held at the Mega Cavern in Louisville, KY, USA. This article describes the systems deployed by Team CSIRO Data61 that tied for the top score and won second place at the event.