 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStow: Robotic Packing of Items into Fabric Pods
May 07, 2025



This paper presents a compliant manipulation system capable of placing items onto densely packed shelves. The wide diversity of items and strict business requirements for high producing rates and low defect generation have prohibited warehouse robotics from performing this task. Our innovations in hardware, perception, decision-making, motion planning, and control have enabled this system to perform over 500,000 stows in a large e-commerce fulfillment center. The system achieves human levels of packing density and speed while prioritizing work on overhead shelves to enhance the safety of humans working alongside the robots.
Pick Planning Strategies for Large-Scale Package Manipulation
Sep 23, 2023



Automating warehouse operations can reduce logistics overhead costs, ultimately driving down the final price for consumers, increasing the speed of delivery, and enhancing the resiliency to market fluctuations. This extended abstract showcases a large-scale package manipulation from unstructured piles in Amazon Robotics' Robot Induction (Robin) fleet, which is used for picking and singulating up to 6 million packages per day and so far has manipulated over 2 billion packages. It describes the various heuristic methods developed over time and their successor, which utilizes a pick success predictor trained on real production data. To the best of the authors' knowledge, this work is the first large-scale deployment of learned pick quality estimation methods in a real production system.
Large-Scale Package Manipulation via Learned Metrics of Pick Success
May 17, 2023



Automating warehouse operations can reduce logistics overhead costs, ultimately driving down the final price for consumers, increasing the speed of delivery, and enhancing the resiliency to workforce fluctuations. The past few years have seen increased interest in automating such repeated tasks but mostly in controlled settings. Tasks such as picking objects from unstructured, cluttered piles have only recently become robust enough for large-scale deployment with minimal human intervention. This paper demonstrates a large-scale package manipulation from unstructured piles in Amazon Robotics' Robot Induction (Robin) fleet, which utilizes a pick success predictor trained on real production data. Specifically, the system was trained on over 394K picks. It is used for singulating up to 5~million packages per day and has manipulated over 200~million packages during this paper's evaluation period. The developed learned pick quality measure ranks various pick alternatives in real-time and prioritizes the most promising ones for execution. The pick success predictor aims to estimate from prior experience the success probability of a desired pick by the deployed industrial robotic arms in cluttered scenes containing deformable and rigid objects with partially known properties. It is a shallow machine learning model, which allows us to evaluate which features are most important for the prediction. An online pick ranker leverages the learned success predictor to prioritize the most promising picks for the robotic arm, which are then assessed for collision avoidance. This learned ranking process is demonstrated to overcome the limitations and outperform the performance of manually engineered and heuristic alternatives. To the best of the authors' knowledge, this paper presents the first large-scale deployment of learned pick quality estimation methods in a real production system.
Heterogeneous Ground and Air Platforms, Homogeneous Sensing: Team CSIRO Data61's Approach to the DARPA Subterranean Challenge
Apr 19, 2021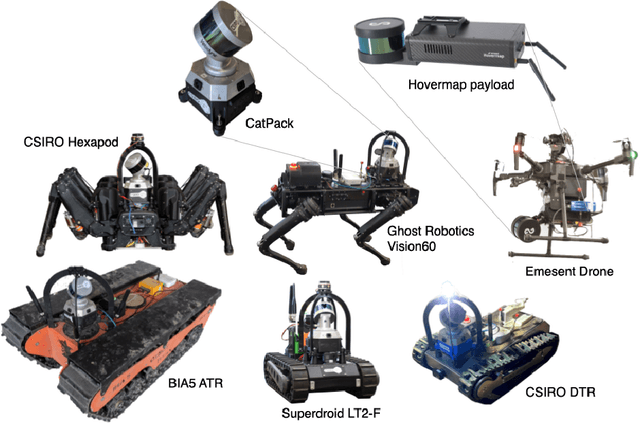
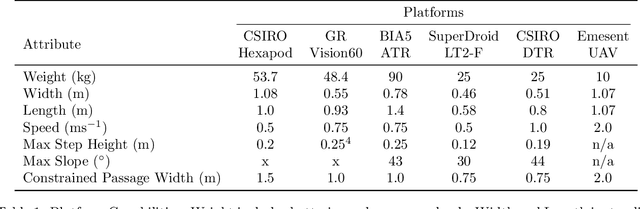
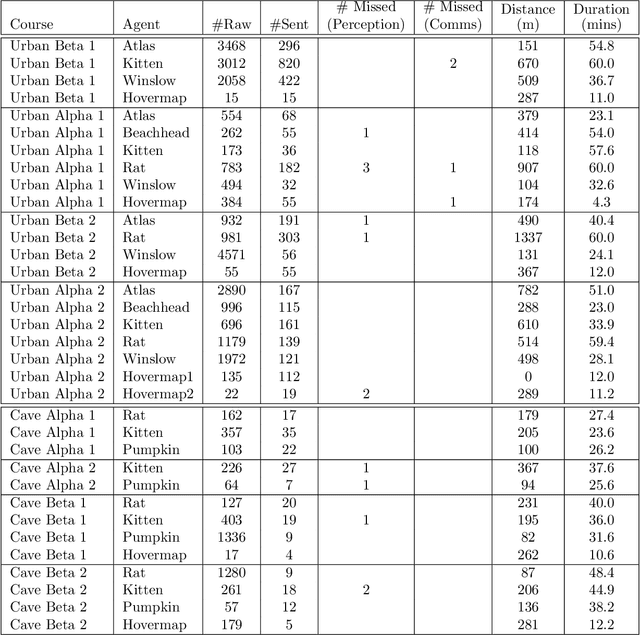
Heterogeneous teams of robots, leveraging a balance between autonomy and human interaction, bring powerful capabilities to the problem of exploring dangerous, unstructured subterranean environments. Here we describe the solution developed by Team CSIRO Data61, consisting of CSIRO, Emesent and Georgia Tech, during the DARPA Subterranean Challenge. These presented systems were fielded in the Tunnel Circuit in August 2019, the Urban Circuit in February 2020, and in our own Cave event, conducted in September 2020. A unique capability of the fielded team is the homogeneous sensing of the platforms utilised, which is leveraged to obtain a decentralised multi-agent SLAM solution on each platform (both ground agents and UAVs) using peer-to-peer communications. This enabled a shift in focus from constructing a pervasive communications network to relying on multi-agent autonomy, motivated by experiences in early circuit events. These experiences also showed the surprising capability of rugged tracked platforms for challenging terrain, which in turn led to the heterogeneous team structure based on a BIA5 OzBot Titan ground robot and an Emesent Hovermap UAV, supplemented by smaller tracked or legged ground robots. The ground agents use a common CatPack perception module, which allowed reuse of the perception and autonomy stack across all ground agents with minimal adaptation.
Passing Through Narrow Gaps with Deep Reinforcement Learning
Mar 06, 2021
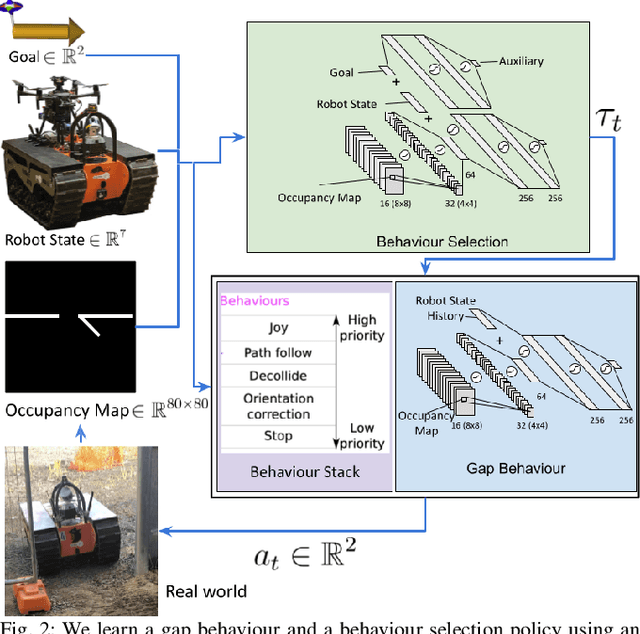
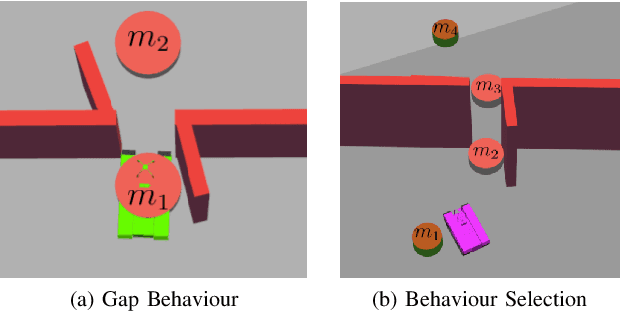
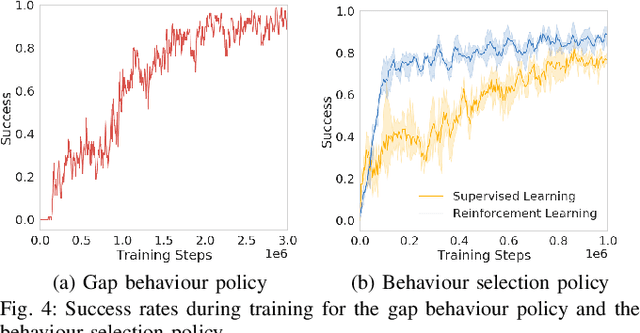
The DARPA subterranean challenge requires teams of robots to traverse difficult and diverse underground environments. Traversing small gaps is one of the challenging scenarios that robots encounter. Imperfect sensor information makes it difficult for classical navigation methods, where behaviours require significant manual fine tuning. In this paper we present a deep reinforcement learning method for autonomously navigating through small gaps, where contact between the robot and the gap may be required. We first learn a gap behaviour policy to get through small gaps (only centimeters wider than the robot). We then learn a goal-conditioned behaviour selection policy that determines when to activate the gap behaviour policy. We train our policies in simulation and demonstrate their effectiveness with a large tracked robot in simulation and on the real platform. In simulation experiments, our approach achieves 93% success rate when the gap behaviour is activated manually by an operator, and 67% with autonomous activation using the behaviour selection policy. In real robot experiments, our approach achieves a success rate of 73% with manual activation, and 40% with autonomous behaviour selection. While we show the feasibility of our approach in simulation, the difference in performance between simulated and real world scenarios highlight the difficulty of direct sim-to-real transfer for deep reinforcement learning policies. In both the simulated and real world environments alternative methods were unable to traverse the gap.
Learning Setup Policies: Reliable Transition Between Locomotion Behaviours
Jan 23, 2021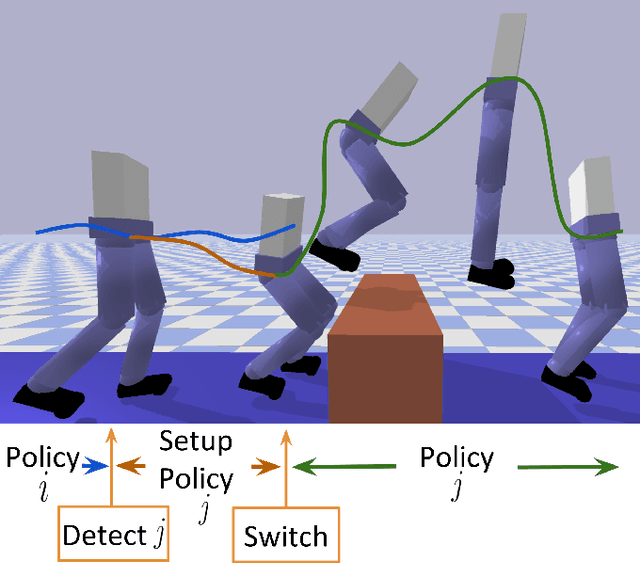
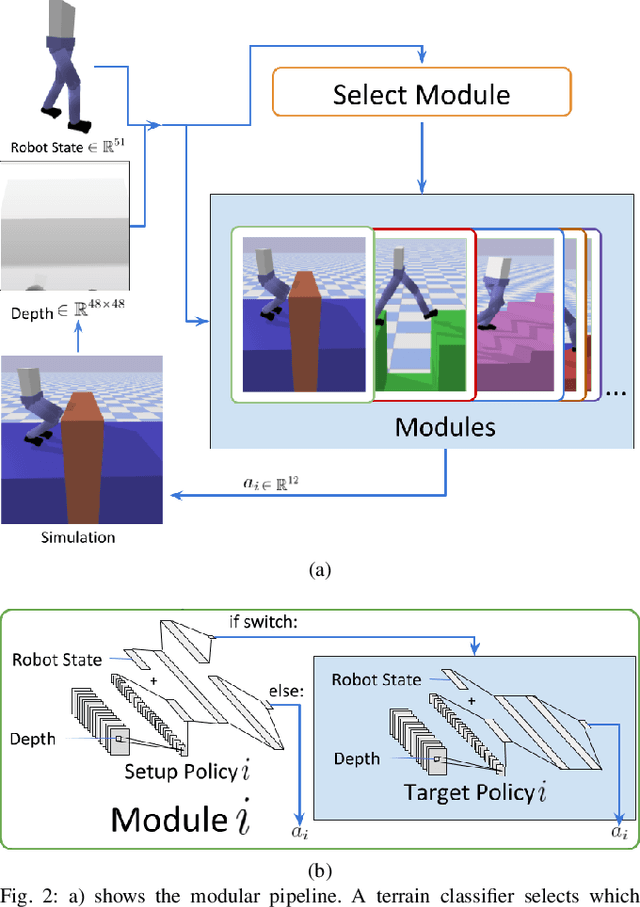
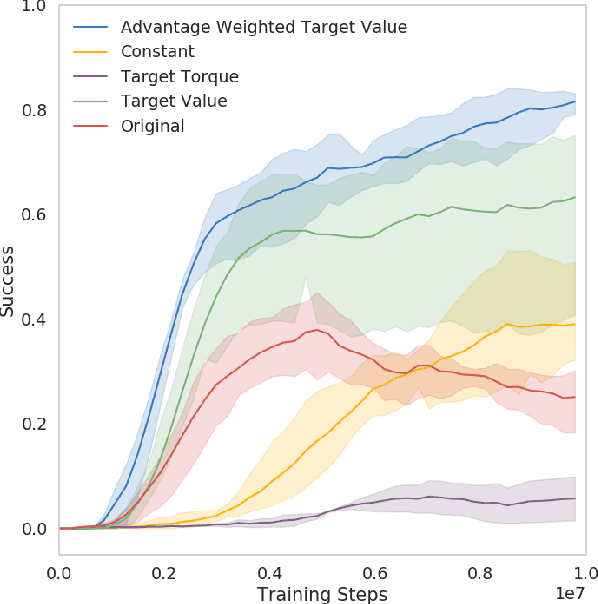

Dynamic platforms that operate over manyunique terrain conditions typically require multiple controllers.To transition safely between controllers, there must be anoverlap of states between adjacent controllers. We developa novel method for training Setup Policies that bridge thetrajectories between pre-trained Deep Reinforcement Learning(DRL) policies. We demonstrate our method with a simulatedbiped traversing a difficult jump terrain, where a single policyfails to learn the task, and switching between pre-trainedpolicies without Setup Policies also fails. We perform anablation of key components of our system, and show thatour method outperforms others that learn transition policies.We demonstrate our method with several difficult and diverseterrain types, and show that we can use Setup Policies as partof a modular control suite to successfully traverse a sequence ofcomplex terrains. We show that using Setup Policies improvesthe success rate for traversing a single difficult jump terrain(from 1.5%success rate without Setup Policies to 82%), and asequence of various terrains (from 6.5%without Setup Policiesto 29.1%).
Semi-supervised Gated Recurrent Neural Networks for Robotic Terrain Classification
Nov 24, 2020

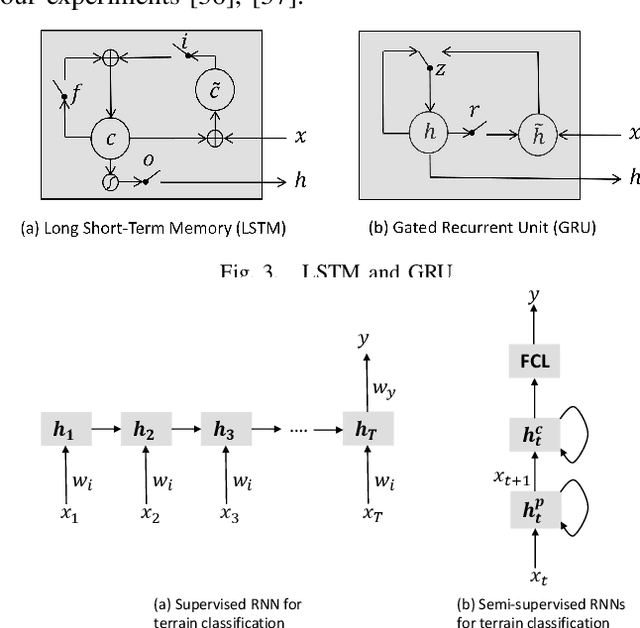
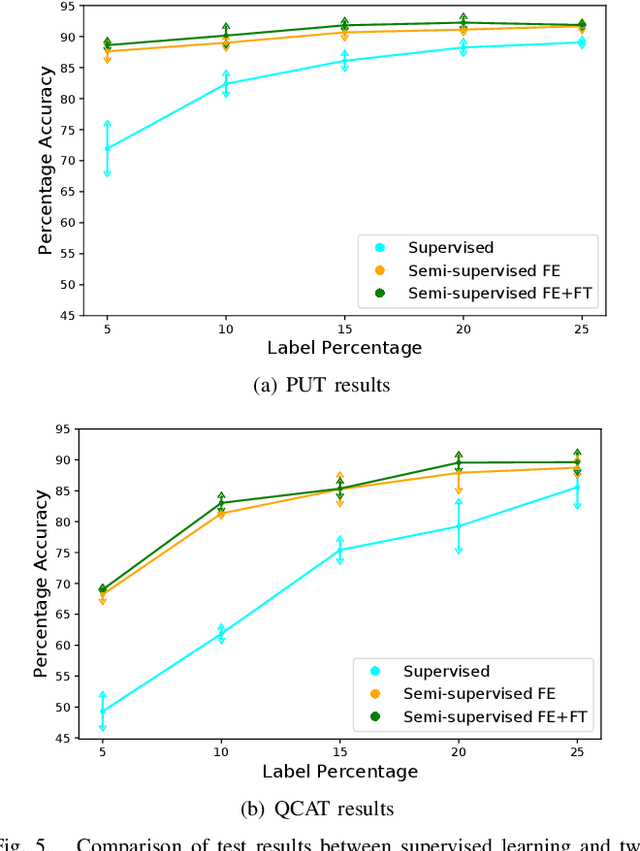
Legged robots are popular candidates for missions in challenging terrains due to the wide variety of locomotion strategies they can employ. Terrain classification is a key enabling technology for autonomous legged robots, as it allows the robot to harness their innate flexibility to adapt their behaviour to the demands of their operating environment. In this paper, we show how highly capable machine learning techniques, namely gated recurrent neural networks, allow our target legged robot to correctly classify the terrain it traverses in both supervised and semi-supervised fashions. Tests on a benchmark data set shows that our time-domain classifiers are well capable of dealing with raw and variable-length data with small amount of labels and perform to a level far exceeding the frequency-domain classifiers. The classification results on our own extended data set opens up a range of high-performance behaviours that are specific to those environments. Furthermore, we show how raw unlabelled data is used to improve significantly the classification results in a semi-supervised model.
Bruce -- Design and Development of a Dynamic Hexapod Robot
Nov 01, 2020

This paper introduces Bruce, the CSIRO Dynamic Hexapod Robot capable of autonomous, dynamic locomotion over difficult terrain. This robot is built around Apptronik linear series elastic actuators, and went from design to deployment in under a year by using approximately 80\% 3D printed structural (joints and link) parts. The robot has so far demonstrated rough terrain traversal over grass, rocks and rubble at 0.3m/s, and flat-ground speeds up to 0.5m/s. This was achieved with a simple controller, inspired by RHex, with a central pattern generator, task-frame impedance control for individual legs and no foot contact detection. The robot is designed to move at up to 1.0m/s on flat ground with appropriate control, and was deployed into the the DARPA SubT Challenge Tunnel circuit event in August 2019.
Learning When to Switch: Composing Controllers to Traverse a Sequence of Terrain Artifacts
Nov 01, 2020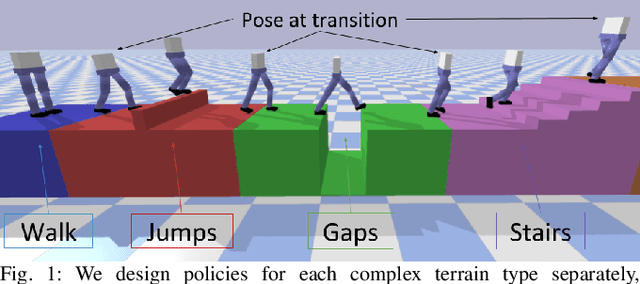
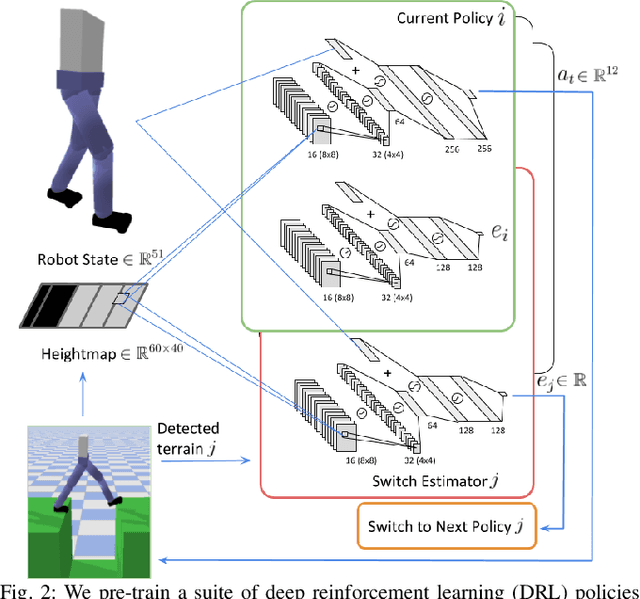
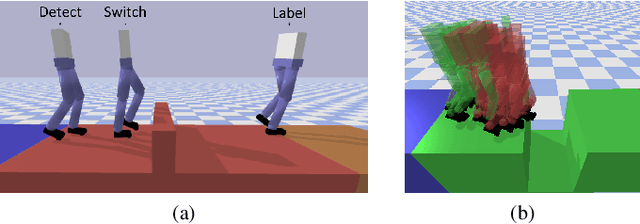
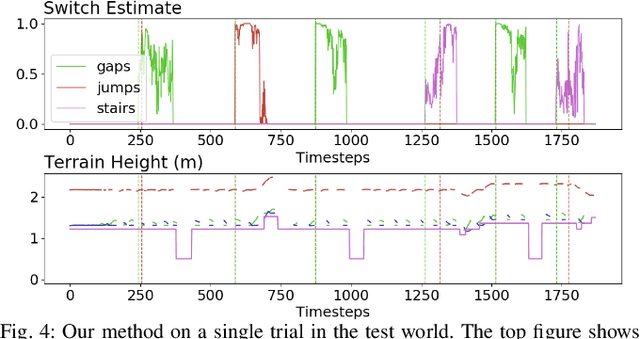
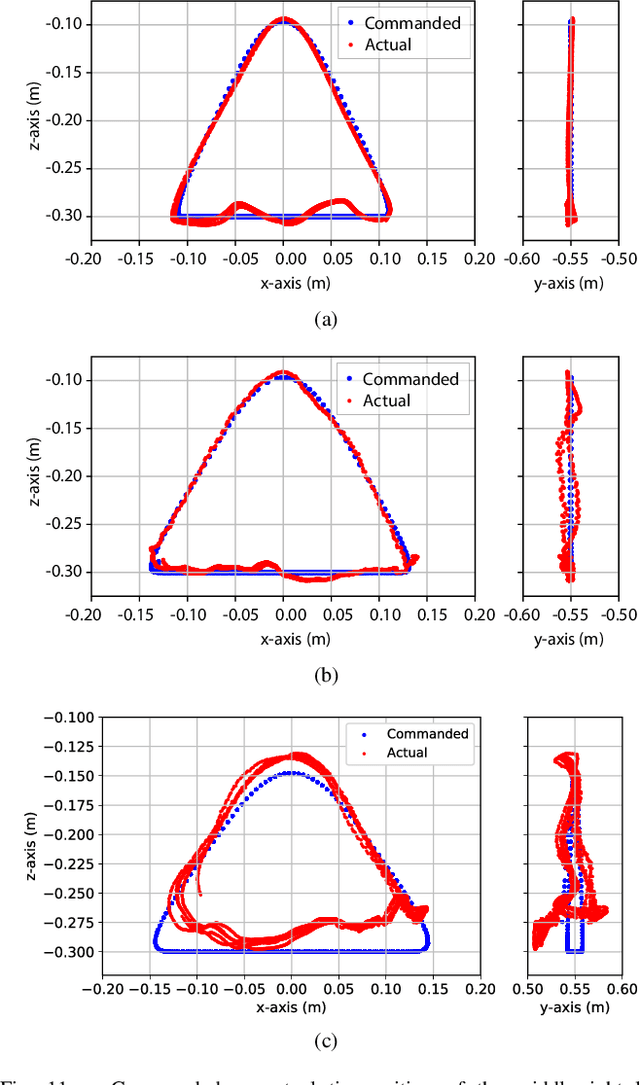
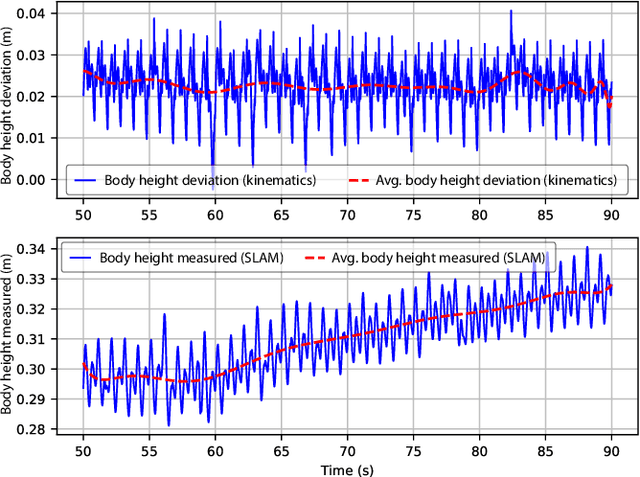
Legged robots often use separate control policies that are highly engineered for traversing difficult terrain such as stairs, gaps, and steps, where switching between policies is only possible when the robot is in a region that is common to adjacent controllers. Deep Reinforcement Learning (DRL) is a promising alternative to hand-crafted control design, though typically requires the full set of test conditions to be known before training. DRL policies can result in complex (often unrealistic) behaviours that have few or no overlapping regions between adjacent policies, making it difficult to switch behaviours. In this work we develop multiple DRL policies with Curriculum Learning (CL), each that can traverse a single respective terrain condition, while ensuring an overlap between policies. We then train a network for each destination policy that estimates the likelihood of successfully switching from any other policy. We evaluate our switching method on a previously unseen combination of terrain artifacts and show that it performs better than heuristic methods. While our method is trained on individual terrain types, it performs comparably to a Deep Q Network trained on the full set of terrain conditions. This approach allows the development of separate policies in constrained conditions with embedded prior knowledge about each behaviour, that is scalable to any number of behaviours, and prepares DRL methods for applications in the real world
Virtual Surfaces and Attitude Aware Planning and Behaviours for Negative Obstacle Navigation
Oct 30, 2020

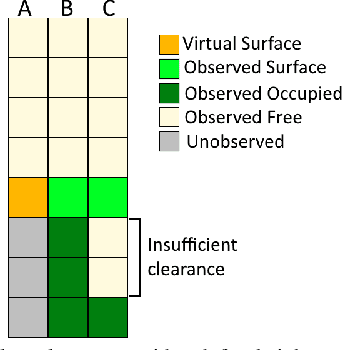
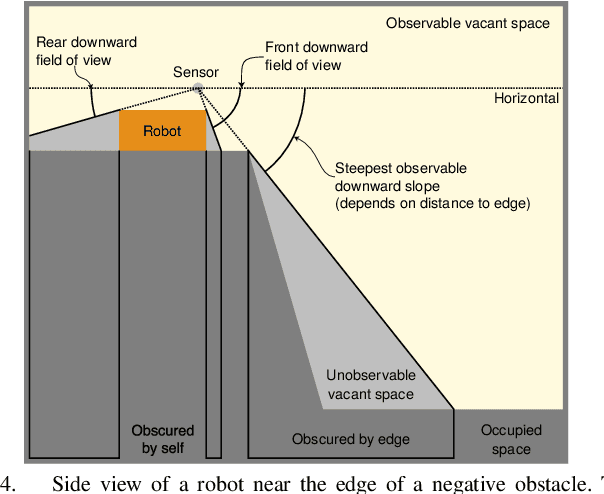
This paper presents an autonomous navigation system for ground robots traversing aggressive unstructured terrain through a cohesive arrangement of mapping, deliberative planning and reactive behaviour modules. All systems are aware of terrain slope, visibility and vehicle orientation, enabling robots to recognize, plan and react around unobserved areas and overcome negative obstacles, slopes, steps, overhangs and narrow passageways. This is the first work to explicitly couple mapping, planning and reactive components in dealing with negative obstacles. The system was deployed on three heterogeneous ground robots for the DARPA Subterranean Challenge, and we present results in Urban and Cave environments, along with simulated scenarios, that demonstrate this approach.