 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User's Casual Sketches
Aug 08, 2024



3D Content Generation is at the heart of many computer graphics applications, including video gaming, film-making, virtual and augmented reality, etc. This paper proposes a novel deep-learning based approach for automatically generating interactive and playable 3D game scenes, all from the user's casual prompts such as a hand-drawn sketch. Sketch-based input offers a natural, and convenient way to convey the user's design intention in the content creation process. To circumvent the data-deficient challenge in learning (i.e. the lack of large training data of 3D scenes), our method leverages a pre-trained 2D denoising diffusion model to generate a 2D image of the scene as the conceptual guidance. In this process, we adopt the isometric projection mode to factor out unknown camera poses while obtaining the scene layout. From the generated isometric image, we use a pre-trained image understanding method to segment the image into meaningful parts, such as off-ground objects, trees, and buildings, and extract the 2D scene layout. These segments and layouts are subsequently fed into a procedural content generation (PCG) engine, such as a 3D video game engine like Unity or Unreal, to create the 3D scene. The resulting 3D scene can be seamlessly integrated into a game development environment and is readily playable. Extensive tests demonstrate that our method can efficiently generate high-quality and interactive 3D game scenes with layouts that closely follow the user's intention.
A Sign Language Recognition System with Pepper, Lightweight-Transformer, and LLM
Sep 28, 2023This research explores using lightweight deep neural network architectures to enable the humanoid robot Pepper to understand American Sign Language (ASL) and facilitate non-verbal human-robot interaction. First, we introduce a lightweight and efficient model for ASL understanding optimized for embedded systems, ensuring rapid sign recognition while conserving computational resources. Building upon this, we employ large language models (LLMs) for intelligent robot interactions. Through intricate prompt engineering, we tailor interactions to allow the Pepper Robot to generate natural Co-Speech Gesture responses, laying the foundation for more organic and intuitive humanoid-robot dialogues. Finally, we present an integrated software pipeline, embodying advancements in a socially aware AI interaction model. Leveraging the Pepper Robot's capabilities, we demonstrate the practicality and effectiveness of our approach in real-world scenarios. The results highlight a profound potential for enhancing human-robot interaction through non-verbal interactions, bridging communication gaps, and making technology more accessible and understandable.
MAVIS: Multi-Camera Augmented Visual-Inertial SLAM using SE2(3) Based Exact IMU Pre-integration
Sep 18, 2023



We present a novel optimization-based Visual-Inertial SLAM system designed for multiple partially overlapped camera systems, named MAVIS. Our framework fully exploits the benefits of wide field-of-view from multi-camera systems, and the metric scale measurements provided by an inertial measurement unit (IMU). We introduce an improved IMU pre-integration formulation based on the exponential function of an automorphism of SE_2(3), which can effectively enhance tracking performance under fast rotational motion and extended integration time. Furthermore, we extend conventional front-end tracking and back-end optimization module designed for monocular or stereo setup towards multi-camera systems, and introduce implementation details that contribute to the performance of our system in challenging scenarios. The practical validity of our approach is supported by our experiments on public datasets. Our MAVIS won the first place in all the vision-IMU tracks (single and multi-session SLAM) on Hilti SLAM Challenge 2023 with 1.7 times the score compared to the second place.
Visual based Tomato Size Measurement System for an Indoor Farming Environment
Apr 12, 2023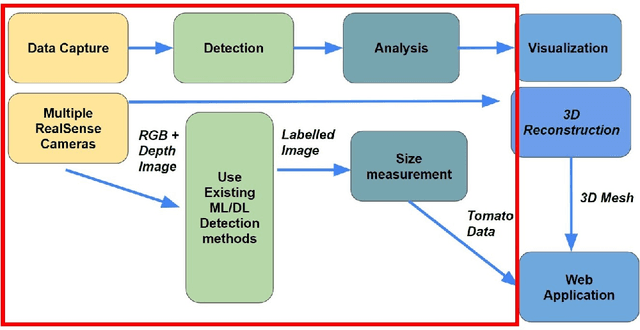
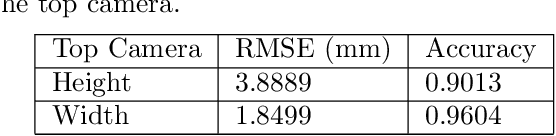

As technology progresses, smart automated systems will serve an increasingly important role in the agricultural industry. Current existing vision systems for yield estimation face difficulties in occlusion and scalability as they utilize a camera system that is large and expensive, which are unsuitable for orchard environments. To overcome these problems, this paper presents a size measurement method combining a machine learning model and depth images captured from three low cost RGBD cameras to detect and measure the height and width of tomatoes. The performance of the presented system is evaluated on a lab environment with real tomato fruits and fake leaves to simulate occlusion in the real farm environment. To improve accuracy by addressing fruit occlusion, our three-camera system was able to achieve a height measurement accuracy of 0.9114 and a width accuracy of 0.9443.
deepNIR: Datasets for generating synthetic NIR images and improved fruit detection system using deep learning techniques
Mar 17, 2022
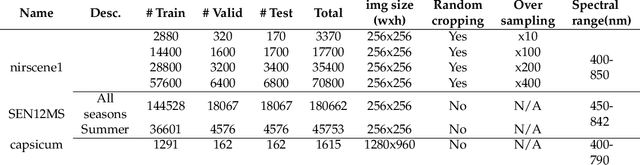
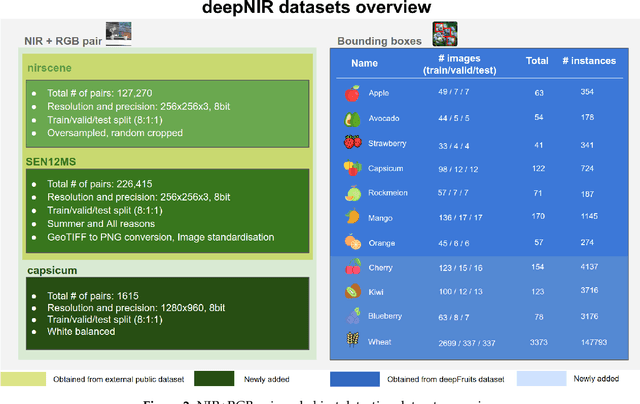
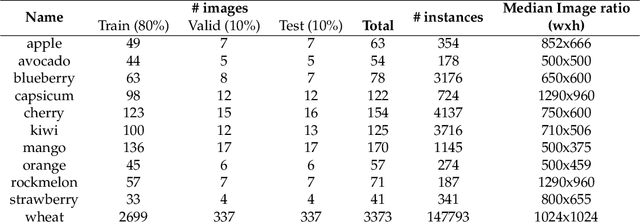
This paper presents datasets utilised for synthetic near-infrared (NIR) image generation and bounding-box level fruit detection systems. It is undeniable that high-calibre machine learning frameworks such as Tensorflow or Pytorch, and large-scale ImageNet or COCO datasets with the aid of accelerated GPU hardware have pushed the limit of machine learning techniques for more than decades. Among these breakthroughs, a high-quality dataset is one of the essential building blocks that can lead to success in model generalisation and the deployment of data-driven deep neural networks. In particular, synthetic data generation tasks often require more training samples than other supervised approaches. Therefore, in this paper, we share the NIR+RGB datasets that are re-processed from two public datasets (i.e., nirscene and SEN12MS) and our novel NIR+RGB sweet pepper(capsicum) dataset. We quantitatively and qualitatively demonstrate that these NIR+RGB datasets are sufficient to be used for synthetic NIR image generation. We achieved Frechet Inception Distance (FID) of 11.36, 26.53, and 40.15 for nirscene1, SEN12MS, and sweet pepper datasets respectively. In addition, we release manual annotations of 11 fruit bounding boxes that can be exported as various formats using cloud service. Four newly added fruits [blueberry, cherry, kiwi, and wheat] compound 11 novel bounding box datasets on top of our previous work presented in the deepFruits project [apple, avocado, capsicum, mango, orange, rockmelon, strawberry]. The total number of bounding box instances of the dataset is 162k and it is ready to use from cloud service. For the evaluation of the dataset, Yolov5 single stage detector is exploited and reported impressive mean-average-precision,mAP[0.5:0.95] results of[min:0.49, max:0.812]. We hope these datasets are useful and serve as a baseline for the future studies.
Subsentence Extraction from Text Using Coverage-Based Deep Learning Language Models
May 07, 2021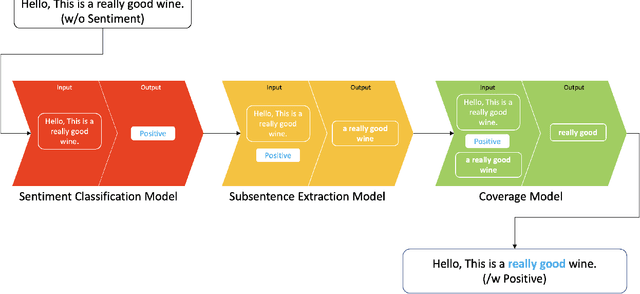
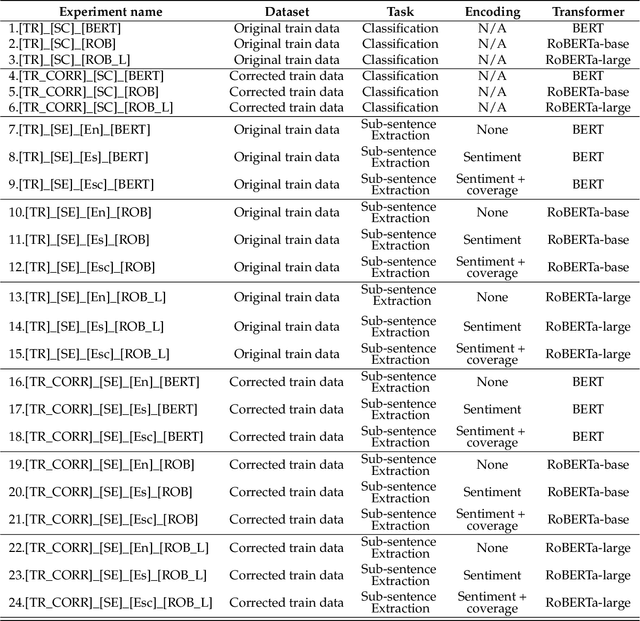
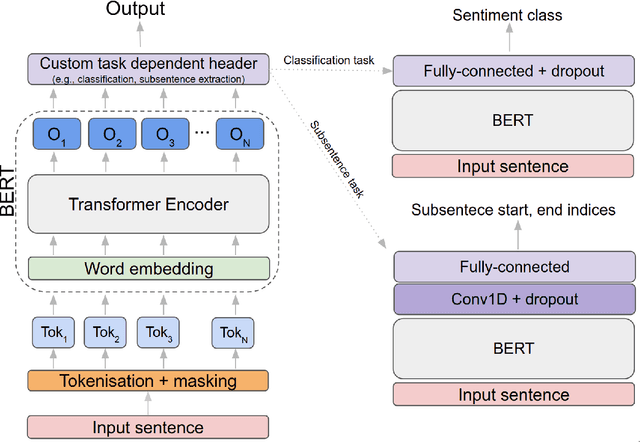
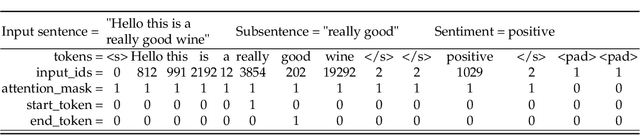
Sentiment prediction remains a challenging and unresolved task in various research fields, including psychology, neuroscience, and computer science. This stems from its high degree of subjectivity and limited input sources that can effectively capture the actual sentiment. This can be even more challenging with only text-based input. Meanwhile, the rise of deep learning and an unprecedented large volume of data have paved the way for artificial intelligence to perform impressively accurate predictions or even human-level reasoning. Drawing inspiration from this, we propose a coverage-based sentiment and subsentence extraction system that estimates a span of input text and recursively feeds this information back to the networks. The predicted subsentence consists of auxiliary information expressing a sentiment. This is an important building block for enabling vivid and epic sentiment delivery (within the scope of this paper) and for other natural language processing tasks such as text summarisation and Q&A. Our approach outperforms the state-of-the-art approaches by a large margin in subsentence prediction (i.e., Average Jaccard scores from 0.72 to 0.89). For the evaluation, we designed rigorous experiments consisting of 24 ablation studies. Finally, our learned lessons are returned to the community by sharing software packages and a public dataset that can reproduce the results presented in this paper.
* 27 pages, 16 figures
Heterogeneous Ground and Air Platforms, Homogeneous Sensing: Team CSIRO Data61's Approach to the DARPA Subterranean Challenge
Apr 19, 2021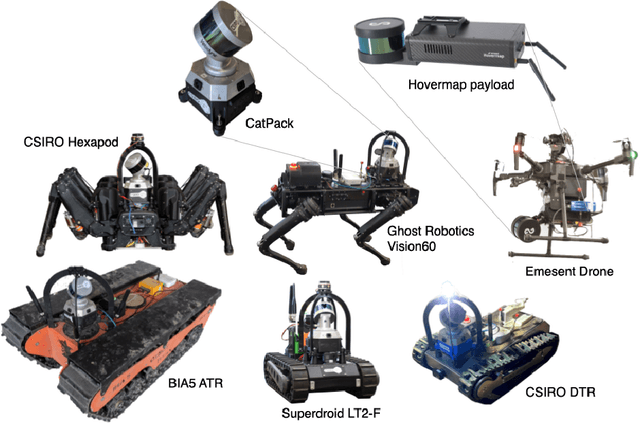
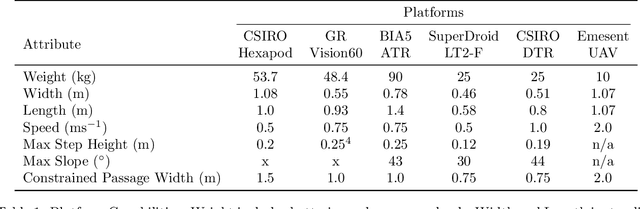
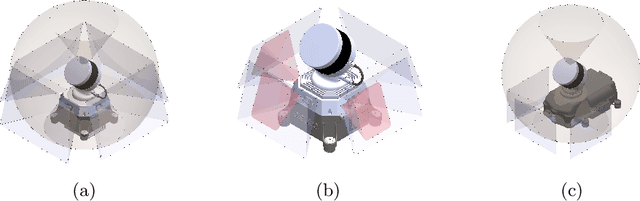
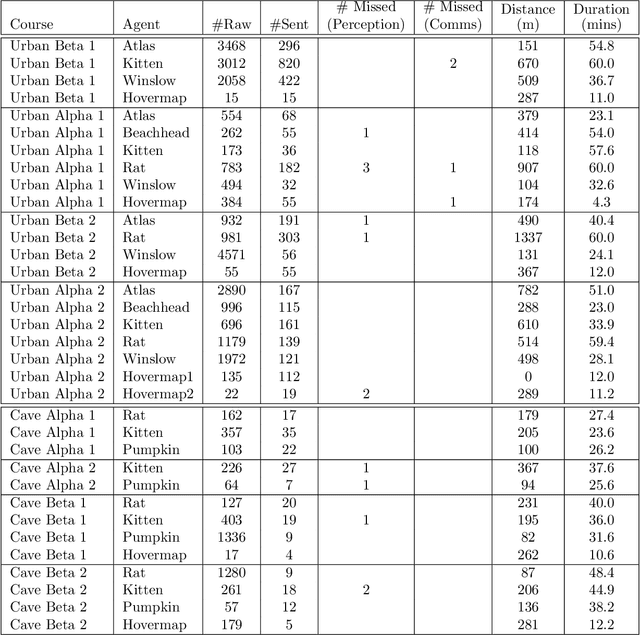
Heterogeneous teams of robots, leveraging a balance between autonomy and human interaction, bring powerful capabilities to the problem of exploring dangerous, unstructured subterranean environments. Here we describe the solution developed by Team CSIRO Data61, consisting of CSIRO, Emesent and Georgia Tech, during the DARPA Subterranean Challenge. These presented systems were fielded in the Tunnel Circuit in August 2019, the Urban Circuit in February 2020, and in our own Cave event, conducted in September 2020. A unique capability of the fielded team is the homogeneous sensing of the platforms utilised, which is leveraged to obtain a decentralised multi-agent SLAM solution on each platform (both ground agents and UAVs) using peer-to-peer communications. This enabled a shift in focus from constructing a pervasive communications network to relying on multi-agent autonomy, motivated by experiences in early circuit events. These experiences also showed the surprising capability of rugged tracked platforms for challenging terrain, which in turn led to the heterogeneous team structure based on a BIA5 OzBot Titan ground robot and an Emesent Hovermap UAV, supplemented by smaller tracked or legged ground robots. The ground agents use a common CatPack perception module, which allowed reuse of the perception and autonomy stack across all ground agents with minimal adaptation.
Virtual Surfaces and Attitude Aware Planning and Behaviours for Negative Obstacle Navigation
Oct 30, 2020

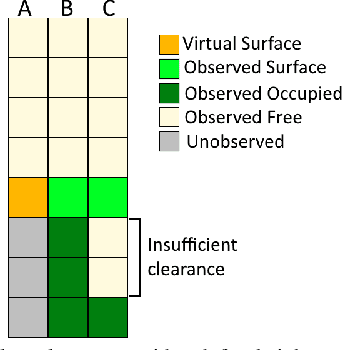
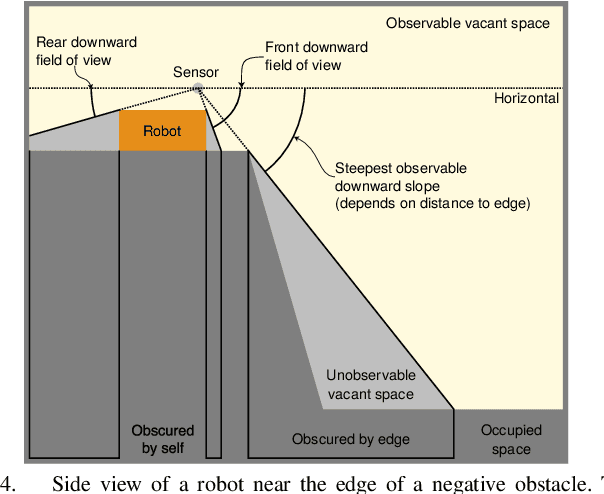
This paper presents an autonomous navigation system for ground robots traversing aggressive unstructured terrain through a cohesive arrangement of mapping, deliberative planning and reactive behaviour modules. All systems are aware of terrain slope, visibility and vehicle orientation, enabling robots to recognize, plan and react around unobserved areas and overcome negative obstacles, slopes, steps, overhangs and narrow passageways. This is the first work to explicitly couple mapping, planning and reactive components in dealing with negative obstacles. The system was deployed on three heterogeneous ground robots for the DARPA Subterranean Challenge, and we present results in Urban and Cave environments, along with simulated scenarios, that demonstrate this approach.
End-to-End Velocity Estimation For Autonomous Racing
Mar 15, 2020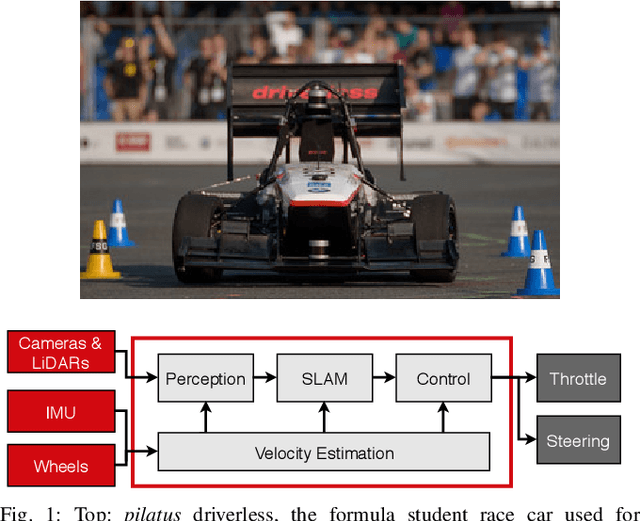
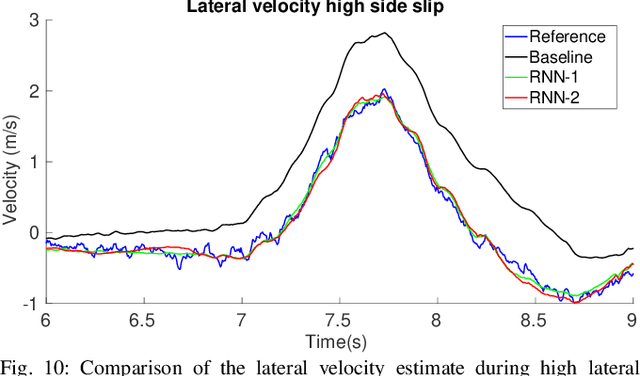
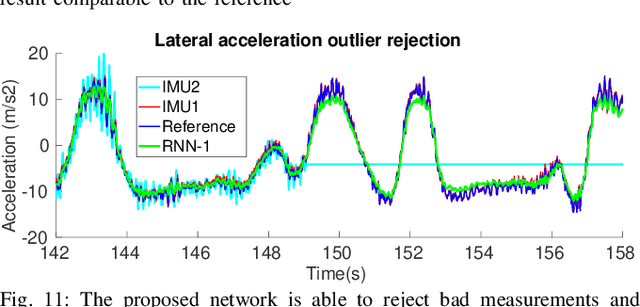
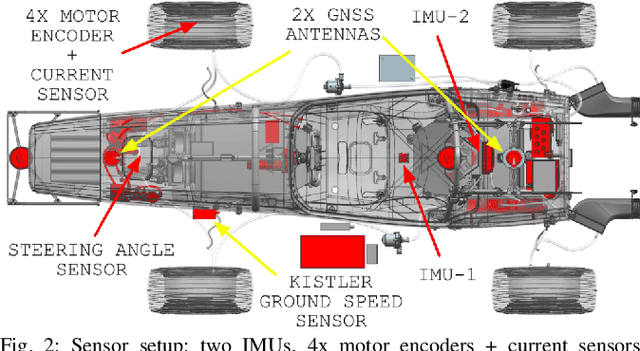
Velocity estimation plays a central role in driverless vehicles, but standard and affordable methods struggle to cope with extreme scenarios like aggressive maneuvers due to the presence of high sideslip. To solve this, autonomous race cars are usually equipped with expensive external velocity sensors. In this paper, we present an end-to-end recurrent neural network that takes available raw sensors as input (IMU, wheel odometry, and motor currents) and outputs velocity estimates. The results are compared to two state-of-the-art Kalman filters, which respectively include and exclude expensive velocity sensors. All methods have been extensively tested on a formula student driverless race car with very high sideslip (10{\deg} at the rear axle) and slip ratio (~20%), operating close to the limits of handling. The proposed network is able to estimate lateral velocity up to 15x better than the Kalman filter with the equivalent sensor input and matches (0.06 m/s RMSE) the Kalman filter with the expensive velocity sensor setup.
Building an Aerial-Ground Robotics System for Precision Farming
Nov 08, 2019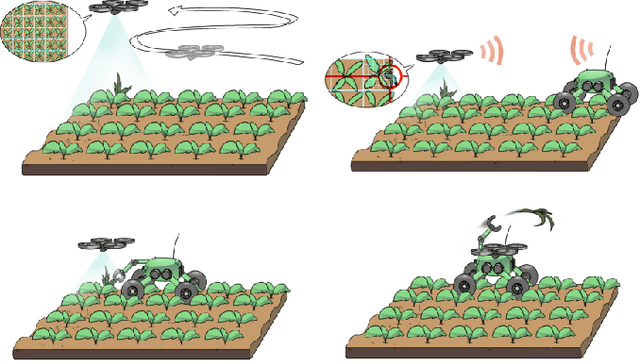

The application of autonomous robots in agriculture is gaining more and more popularity thanks to the high impact it may have on food security, sustainability, resource use efficiency, reduction of chemical treatments, minimization of the human effort and maximization of yield. The Flourish research project faced this challenge by developing an adaptable robotic solution for precision farming that combines the aerial survey capabilities of small autonomous unmanned aerial vehicles (UAVs) with flexible targeted intervention performed by multi-purpose agricultural unmanned ground vehicles (UGVs). This paper presents an exhaustive overview of the scientific and technological advances and outcomes obtained in the Flourish project. We introduce multi-spectral perception algorithms and aerial and ground based systems developed to monitor crop density, weed pressure, crop nitrogen nutrition status, and to accurately classify and locate weeds. We then introduce the navigation and mapping systems to deal with the specificity of the employed robots and of the agricultural environment, highlighting the collaborative modules that enable the UAVs and UGVs to collect and share information in a unified environment model. We finally present the ground intervention hardware, software solutions, and interfaces we implemented and tested in different field conditions and with different crops. We describe here a real use case in which a UAV collaborates with a UGV to monitor the field and to perform selective spraying treatments in a totally autonomous way.