 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Imitation Learning for Stochastic Environments
Sep 25, 2023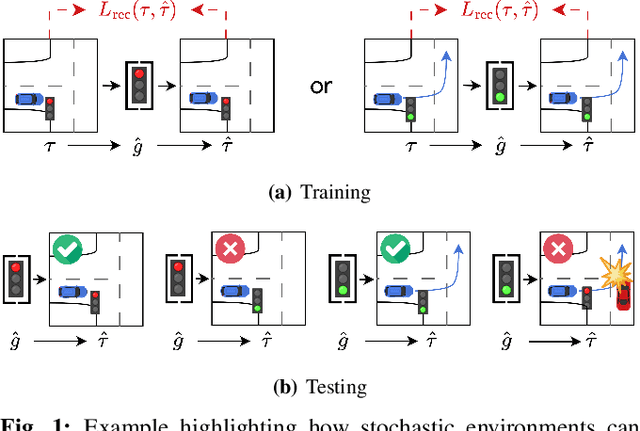
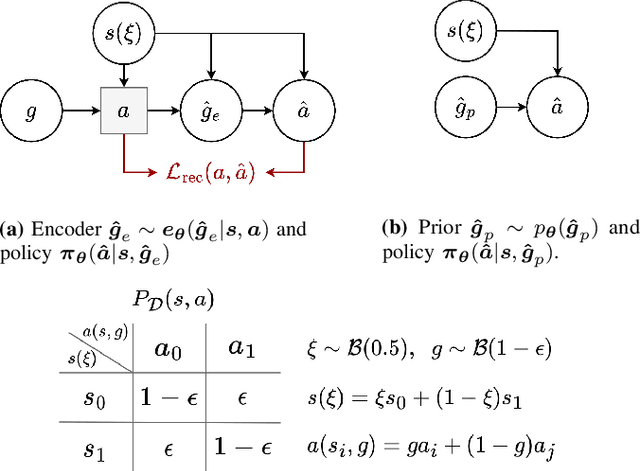
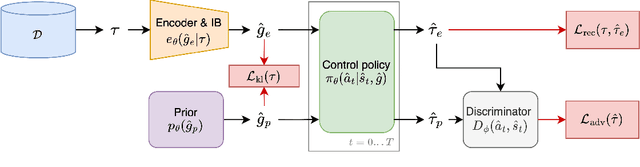
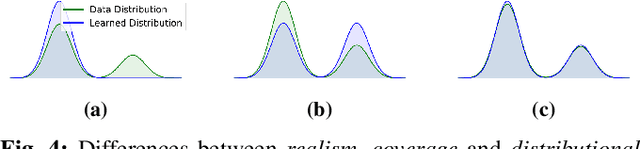
Many applications of imitation learning require the agent to generate the full distribution of behaviour observed in the training data. For example, to evaluate the safety of autonomous vehicles in simulation, accurate and diverse behaviour models of other road users are paramount. Existing methods that improve this distributional realism typically rely on hierarchical policies. These condition the policy on types such as goals or personas that give rise to multi-modal behaviour. However, such methods are often inappropriate for stochastic environments where the agent must also react to external factors: because agent types are inferred from the observed future trajectory during training, these environments require that the contributions of internal and external factors to the agent behaviour are disentangled and only internal factors, i.e., those under the agent's control, are encoded in the type. Encoding future information about external factors leads to inappropriate agent reactions during testing, when the future is unknown and types must be drawn independently from the actual future. We formalize this challenge as distribution shift in the conditional distribution of agent types under environmental stochasticity. We propose Robust Type Conditioning (RTC), which eliminates this shift with adversarial training under randomly sampled types. Experiments on two domains, including the large-scale Waymo Open Motion Dataset, show improved distributional realism while maintaining or improving task performance compared to state-of-the-art baselines.
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
Dec 02, 2022



ML-based motion planning is a promising approach to produce agents that exhibit complex behaviors, and automatically adapt to novel environments. In the context of autonomous driving, it is common to treat all available training data equally. However, this approach produces agents that do not perform robustly in safety-critical settings, an issue that cannot be addressed by simply adding more data to the training set - we show that an agent trained using only a 10% subset of the data performs just as well as an agent trained on the entire dataset. We present a method to predict the inherent difficulty of a driving situation given data collected from a fleet of autonomous vehicles deployed on public roads. We then demonstrate that this difficulty score can be used in a zero-shot transfer to generate curricula for an imitation-learning based planning agent. Compared to training on the entire unbiased training dataset, we show that prioritizing difficult driving scenarios both reduces collisions by 15% and increases route adherence by 14% in closed-loop evaluation, all while using only 10% of the training data.
Posetal Games: Efficiency, Existence, and Refinement of Equilibria in Games with Prioritized Metrics
Nov 13, 2021



Modern applications require robots to comply with multiple, often conflicting rules and to interact with the other agents. We present Posetal Games as a class of games in which each player expresses a preference over the outcomes via a partially ordered set of metrics. This allows one to combine hierarchical priorities of each player with the interactive nature of the environment. By contextualizing standard game theoretical notions, we provide two sufficient conditions on the preference of the players to prove existence of pure Nash Equilibria in finite action sets. Moreover, we define formal operations on the preference structures and link them to a refinement of the game solutions, showing how the set of equilibria can be systematically shrunk. The presented results are showcased in a driving game where autonomous vehicles select from a finite set of trajectories. The results demonstrate the interpretability of results in terms of minimum-rank-violation for each player.
A Holistic Motion Planning and Control Solution to Challenge a Professional Racecar Driver
Feb 28, 2021


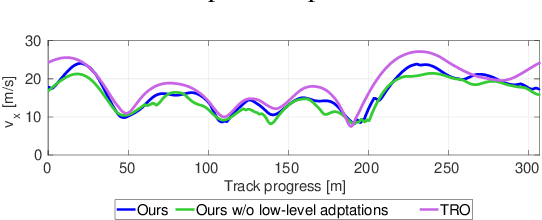
We present a holistically designed three layer control architecture capable of outperforming a professional driver racing the same car. Our approach focuses on the co-design of the motion planning and control layers, extracting the full potential of the connected system. First, a high-level planner computes an optimal trajectory around the track, then in real-time the mid-level nonlinear model predictive controller follows this path using the high-level information as guidance. Finally a high frequency, low-level controller tracks the states predicted by the mid-level controller. Tracking the predicted behavior has two advantages: it reduces the mismatch between the model used in the upper layers and the real car, and allows for a torque vectoring command to be optimized by the higher level motion planners. The tailored design of the low-level controller proved to be crucial for bridging the gap between planning and control, unlocking unseen performance in autonomous racing. The proposed approach was verified on a full size racecar, resulting in a considerable improvement over the state-of-the-art results achieved on the same vehicle. Finally, we also show that the proposed co-design approach outperforms a professional racecar driver.
End-to-End Velocity Estimation For Autonomous Racing
Mar 15, 2020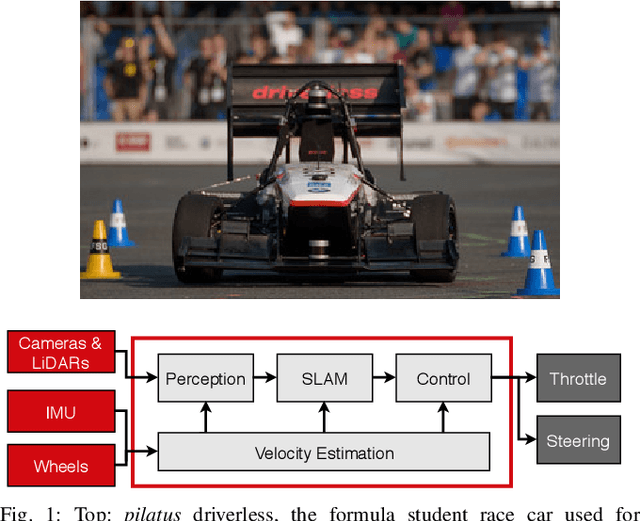
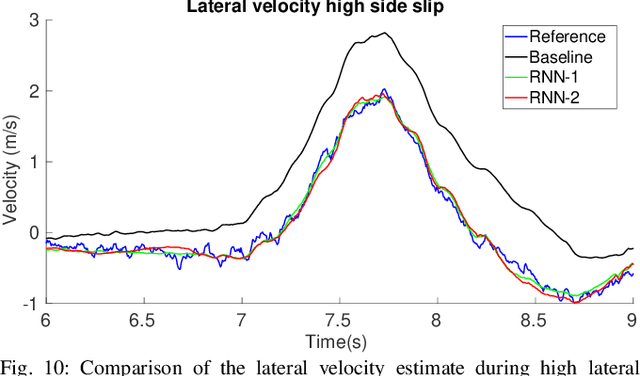
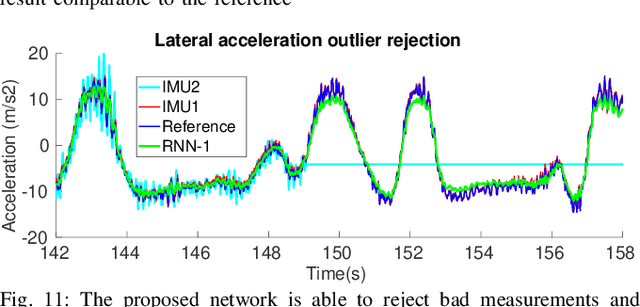
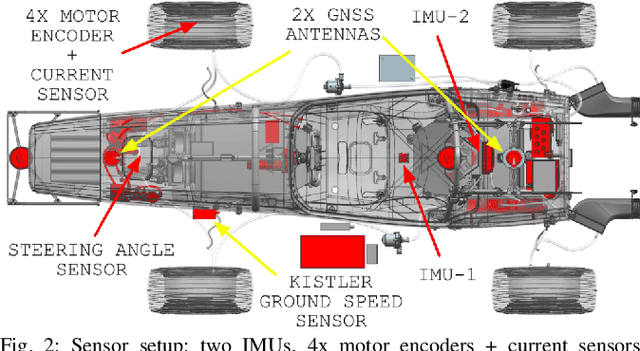
Velocity estimation plays a central role in driverless vehicles, but standard and affordable methods struggle to cope with extreme scenarios like aggressive maneuvers due to the presence of high sideslip. To solve this, autonomous race cars are usually equipped with expensive external velocity sensors. In this paper, we present an end-to-end recurrent neural network that takes available raw sensors as input (IMU, wheel odometry, and motor currents) and outputs velocity estimates. The results are compared to two state-of-the-art Kalman filters, which respectively include and exclude expensive velocity sensors. All methods have been extensively tested on a formula student driverless race car with very high sideslip (10{\deg} at the rear axle) and slip ratio (~20%), operating close to the limits of handling. The proposed network is able to estimate lateral velocity up to 15x better than the Kalman filter with the equivalent sensor input and matches (0.06 m/s RMSE) the Kalman filter with the expensive velocity sensor setup.