 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGen: Unified Modeling of Initial Agent States and Trajectories for Generating Autonomous Driving Scenarios
May 06, 2024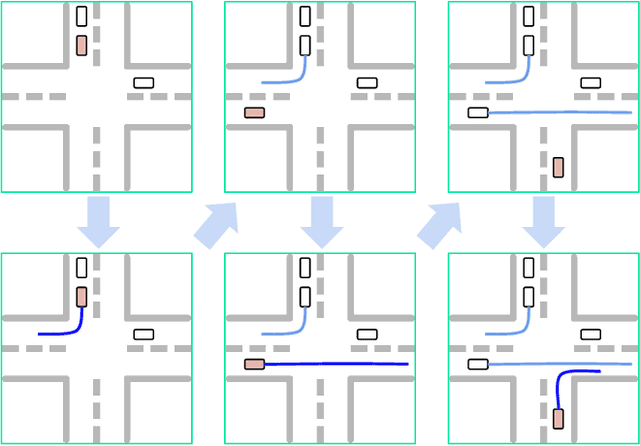
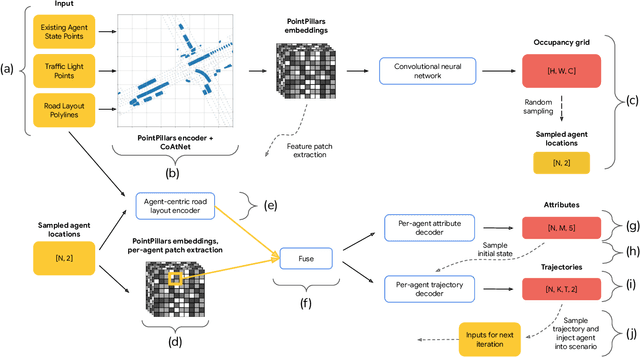
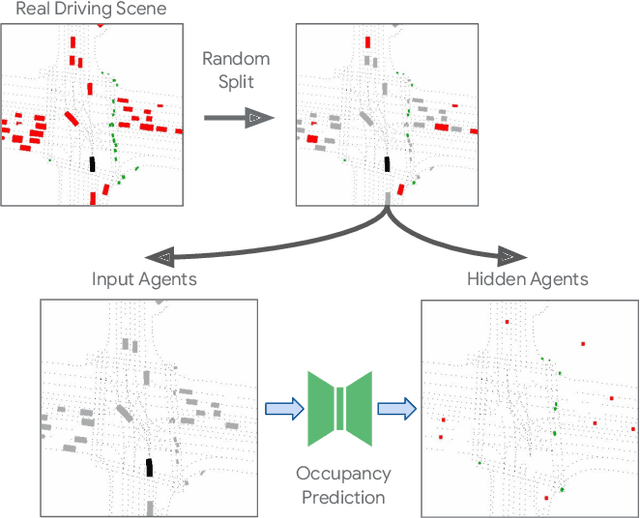

This paper introduces UniGen, a novel approach to generating new traffic scenarios for evaluating and improving autonomous driving software through simulation. Our approach models all driving scenario elements in a unified model: the position of new agents, their initial state, and their future motion trajectories. By predicting the distributions of all these variables from a shared global scenario embedding, we ensure that the final generated scenario is fully conditioned on all available context in the existing scene. Our unified modeling approach, combined with autoregressive agent injection, conditions the placement and motion trajectory of every new agent on all existing agents and their trajectories, leading to realistic scenarios with low collision rates. Our experimental results show that UniGen outperforms prior state of the art on the Waymo Open Motion Dataset.
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Oct 12, 2023
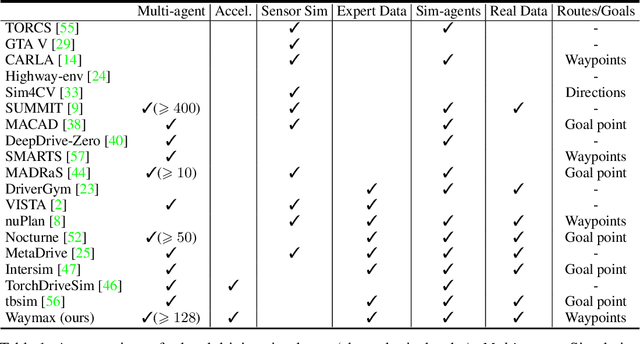
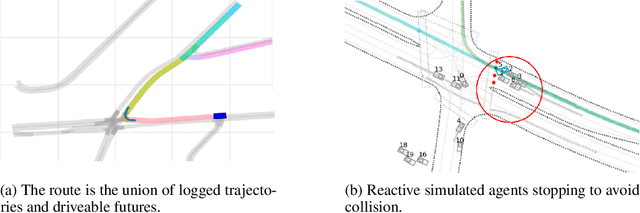
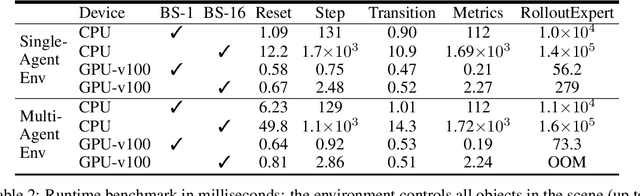
Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of nuanced and complex multi-agent interactive behaviors. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
Hierarchical Imitation Learning for Stochastic Environments
Sep 25, 2023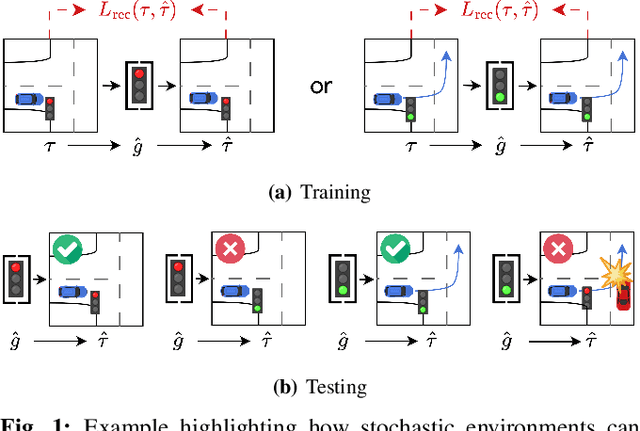
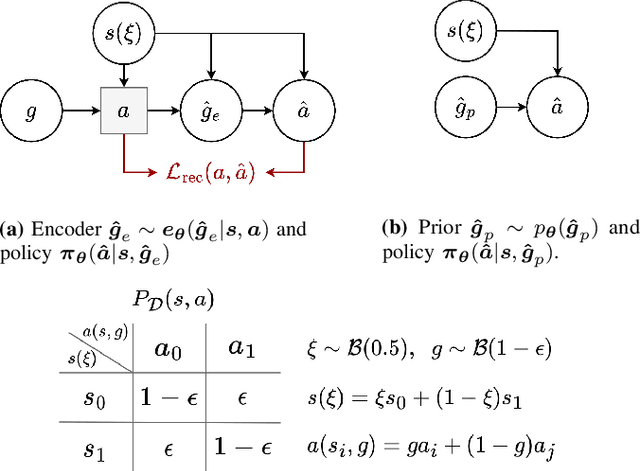
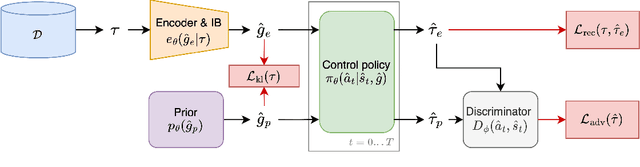
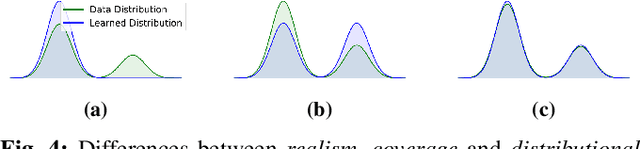
Many applications of imitation learning require the agent to generate the full distribution of behaviour observed in the training data. For example, to evaluate the safety of autonomous vehicles in simulation, accurate and diverse behaviour models of other road users are paramount. Existing methods that improve this distributional realism typically rely on hierarchical policies. These condition the policy on types such as goals or personas that give rise to multi-modal behaviour. However, such methods are often inappropriate for stochastic environments where the agent must also react to external factors: because agent types are inferred from the observed future trajectory during training, these environments require that the contributions of internal and external factors to the agent behaviour are disentangled and only internal factors, i.e., those under the agent's control, are encoded in the type. Encoding future information about external factors leads to inappropriate agent reactions during testing, when the future is unknown and types must be drawn independently from the actual future. We formalize this challenge as distribution shift in the conditional distribution of agent types under environmental stochasticity. We propose Robust Type Conditioning (RTC), which eliminates this shift with adversarial training under randomly sampled types. Experiments on two domains, including the large-scale Waymo Open Motion Dataset, show improved distributional realism while maintaining or improving task performance compared to state-of-the-art baselines.
The Waymo Open Sim Agents Challenge
May 19, 2023In this work, we define the Waymo Open Sim Agents Challenge (WOSAC). Simulation with realistic, interactive agents represents a key task for autonomous vehicle software development. WOSAC is the first public challenge to tackle this task and propose corresponding metrics. The goal of the challenge is to stimulate the design of realistic simulators that can be used to evaluate and train a behavior model for autonomous driving. We outline our evaluation methodology and present preliminary results for a number of different baseline simulation agent methods.
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving
Oct 18, 2022
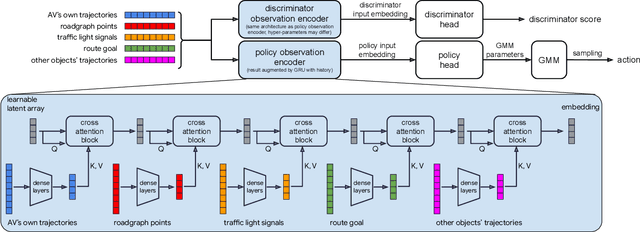
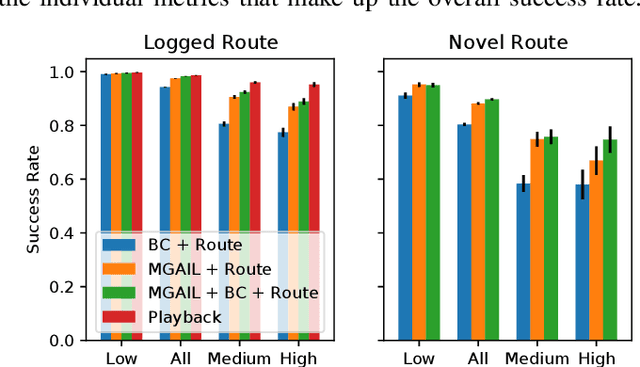
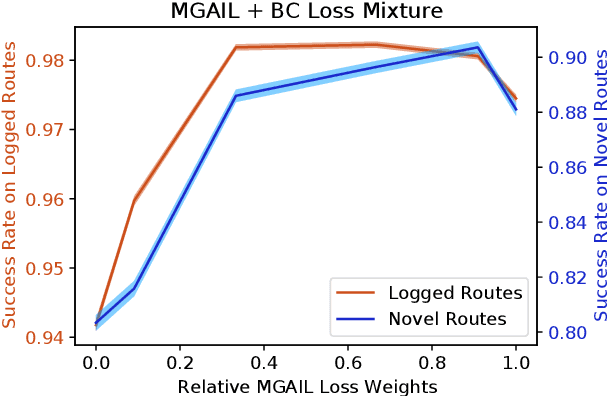
We demonstrate the first large-scale application of model-based generative adversarial imitation learning (MGAIL) to the task of dense urban self-driving. We augment standard MGAIL using a hierarchical model to enable generalization to arbitrary goal routes, and measure performance using a closed-loop evaluation framework with simulated interactive agents. We train policies from expert trajectories collected from real vehicles driving over 100,000 miles in San Francisco, and demonstrate a steerable policy that can navigate robustly even in a zero-shot setting, generalizing to synthetic scenarios with novel goals that never occurred in real-world driving. We also demonstrate the importance of mixing closed-loop MGAIL losses with open-loop behavior cloning losses, and show our best policy approaches the performance of the expert. We evaluate our imitative model in both average and challenging scenarios, and show how it can serve as a useful prior to plan successful trajectories.
Symphony: Learning Realistic and Diverse Agents for Autonomous Driving Simulation
May 06, 2022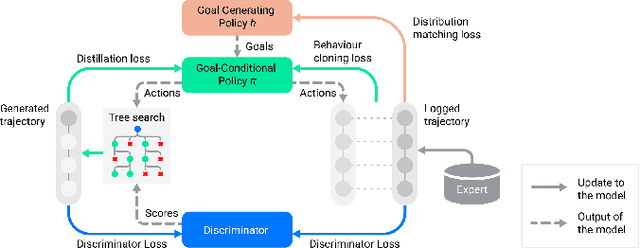
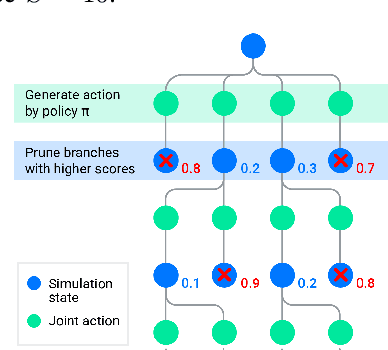
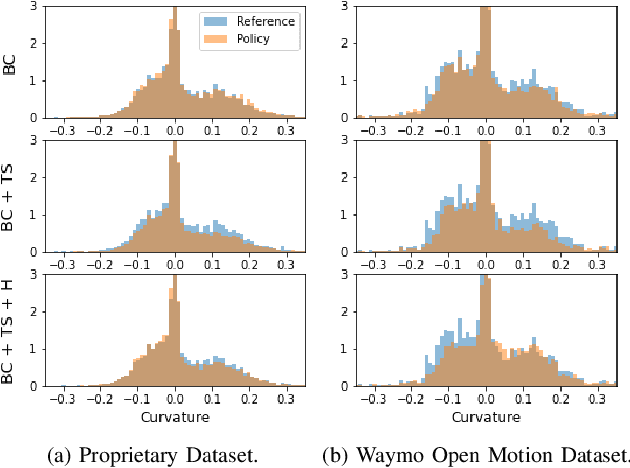
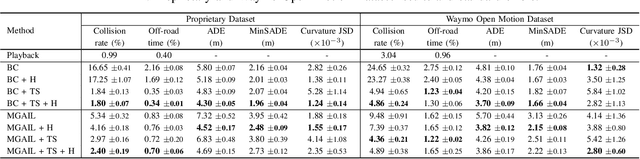
Simulation is a crucial tool for accelerating the development of autonomous vehicles. Making simulation realistic requires models of the human road users who interact with such cars. Such models can be obtained by applying learning from demonstration (LfD) to trajectories observed by cars already on the road. However, existing LfD methods are typically insufficient, yielding policies that frequently collide or drive off the road. To address this problem, we propose Symphony, which greatly improves realism by combining conventional policies with a parallel beam search. The beam search refines these policies on the fly by pruning branches that are unfavourably evaluated by a discriminator. However, it can also harm diversity, i.e., how well the agents cover the entire distribution of realistic behaviour, as pruning can encourage mode collapse. Symphony addresses this issue with a hierarchical approach, factoring agent behaviour into goal generation and goal conditioning. The use of such goals ensures that agent diversity neither disappears during adversarial training nor is pruned away by the beam search. Experiments on both proprietary and open Waymo datasets confirm that Symphony agents learn more realistic and diverse behaviour than several baselines.