 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-Informed Discovery via Bayesian Adaptive Multifidelity Sampling
Nov 26, 2024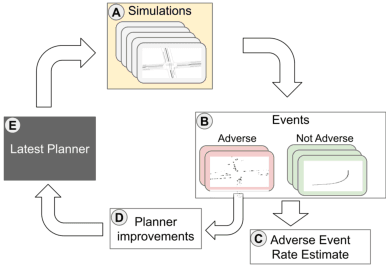
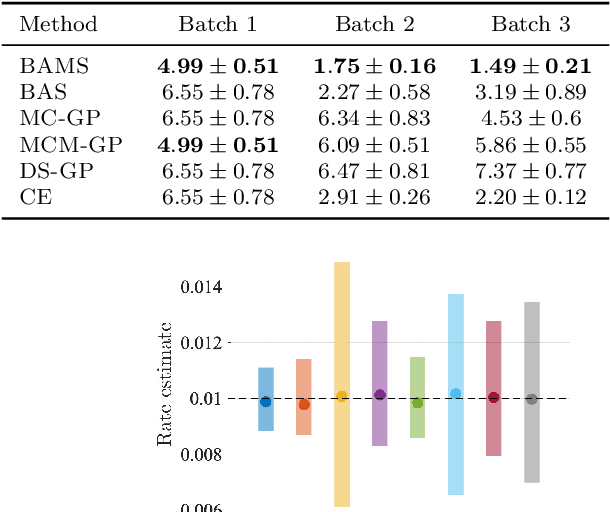
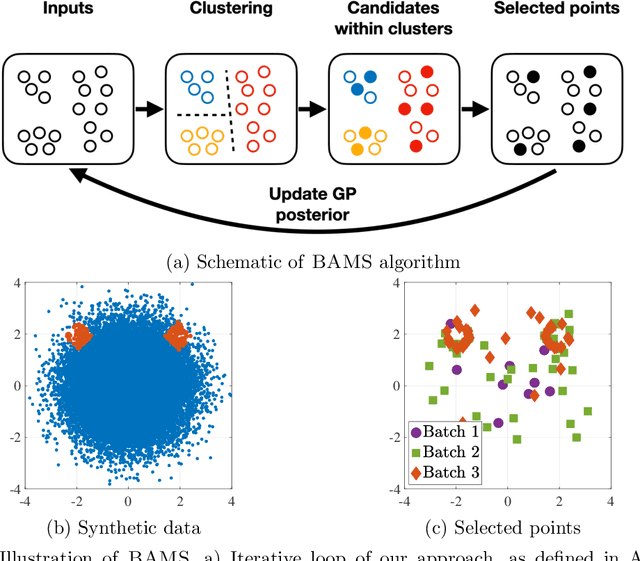
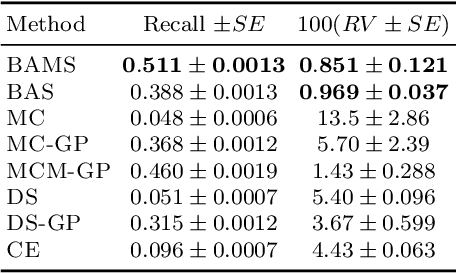
Ensuring the safety of autonomous vehicles (AVs) requires both accurate estimation of their performance and efficient discovery of potential failure cases. This paper introduces Bayesian adaptive multifidelity sampling (BAMS), which leverages the power of adaptive Bayesian sampling to achieve efficient discovery while simultaneously estimating the rate of adverse events. BAMS prioritizes exploration of regions with potentially low performance, leading to the identification of novel and critical scenarios that traditional methods might miss. Using real-world AV data we demonstrate that BAMS discovers 10 times as many issues as Monte Carlo (MC) and importance sampling (IS) baselines, while at the same time generating rate estimates with variances 15 and 6 times narrower than MC and IS baselines respectively.
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
Dec 02, 2022



ML-based motion planning is a promising approach to produce agents that exhibit complex behaviors, and automatically adapt to novel environments. In the context of autonomous driving, it is common to treat all available training data equally. However, this approach produces agents that do not perform robustly in safety-critical settings, an issue that cannot be addressed by simply adding more data to the training set - we show that an agent trained using only a 10% subset of the data performs just as well as an agent trained on the entire dataset. We present a method to predict the inherent difficulty of a driving situation given data collected from a fleet of autonomous vehicles deployed on public roads. We then demonstrate that this difficulty score can be used in a zero-shot transfer to generate curricula for an imitation-learning based planning agent. Compared to training on the entire unbiased training dataset, we show that prioritizing difficult driving scenarios both reduces collisions by 15% and increases route adherence by 14% in closed-loop evaluation, all while using only 10% of the training data.
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving
Oct 18, 2022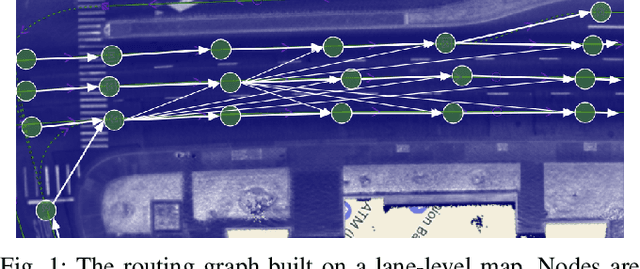
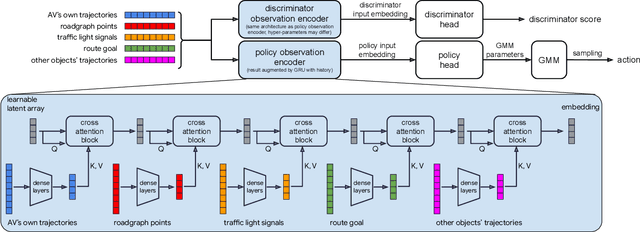
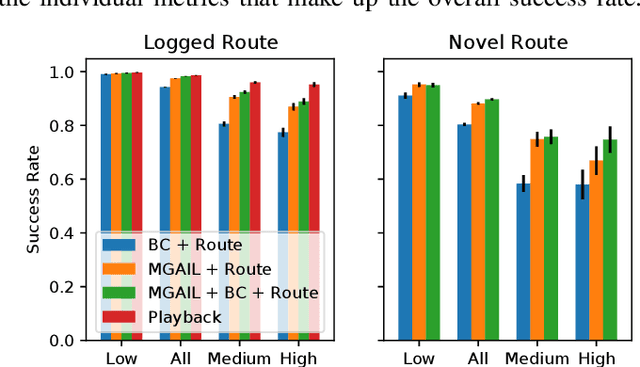
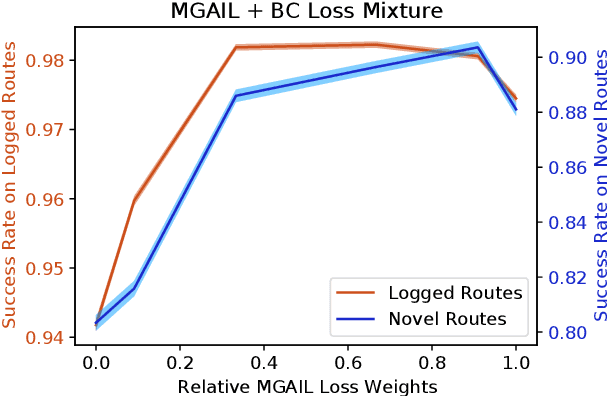
We demonstrate the first large-scale application of model-based generative adversarial imitation learning (MGAIL) to the task of dense urban self-driving. We augment standard MGAIL using a hierarchical model to enable generalization to arbitrary goal routes, and measure performance using a closed-loop evaluation framework with simulated interactive agents. We train policies from expert trajectories collected from real vehicles driving over 100,000 miles in San Francisco, and demonstrate a steerable policy that can navigate robustly even in a zero-shot setting, generalizing to synthetic scenarios with novel goals that never occurred in real-world driving. We also demonstrate the importance of mixing closed-loop MGAIL losses with open-loop behavior cloning losses, and show our best policy approaches the performance of the expert. We evaluate our imitative model in both average and challenging scenarios, and show how it can serve as a useful prior to plan successful trajectories.
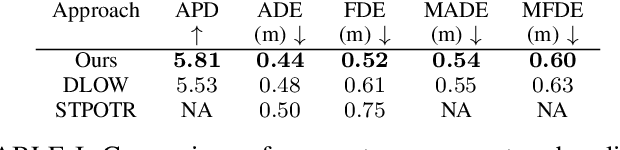
STPOTR: Simultaneous Human Trajectory and Pose Prediction Using a Non-Autoregressive Transformer for Robot Following Ahead
Sep 27, 2022
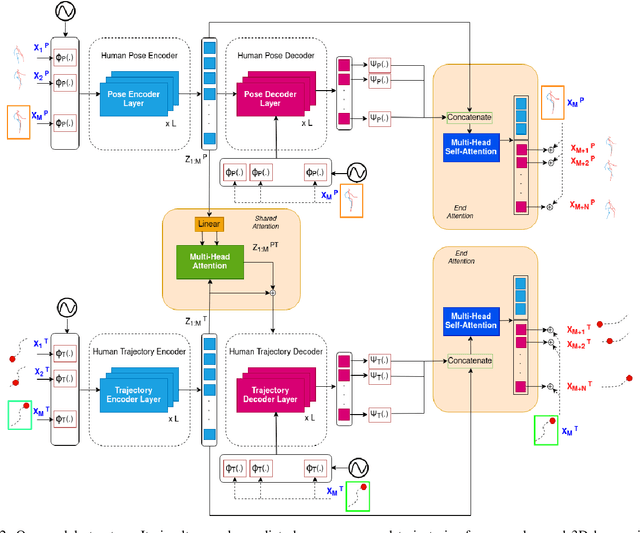


In this paper, we develop a neural network model to predict future human motion from an observed human motion history. We propose a non-autoregressive transformer architecture to leverage its parallel nature for easier training and fast, accurate predictions at test time. The proposed architecture divides human motion prediction into two parts: 1) the human trajectory, which is the hip joint 3D position over time and 2) the human pose which is the all other joints 3D positions over time with respect to a fixed hip joint. We propose to make the two predictions simultaneously, as the shared representation can improve the model performance. Therefore, the model consists of two sets of encoders and decoders. First, a multi-head attention module applied to encoder outputs improves human trajectory. Second, another multi-head self-attention module applied to encoder outputs concatenated with decoder outputs facilitates learning of temporal dependencies. Our model is well-suited for robotic applications in terms of test accuracy and speed, and compares favorably with respect to state-of-the-art methods. We demonstrate the real-world applicability of our work via the Robot Follow-Ahead task, a challenging yet practical case study for our proposed model.
DMMGAN: Diverse Multi Motion Prediction of 3D Human Joints using Attention-Based Generative Adverserial Network
Sep 13, 2022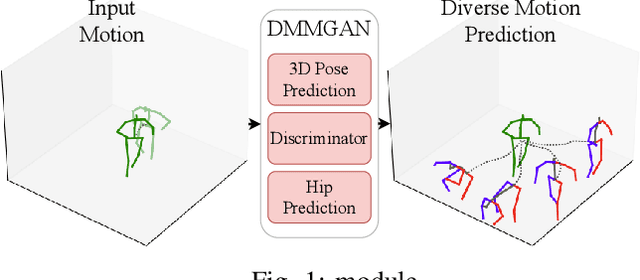
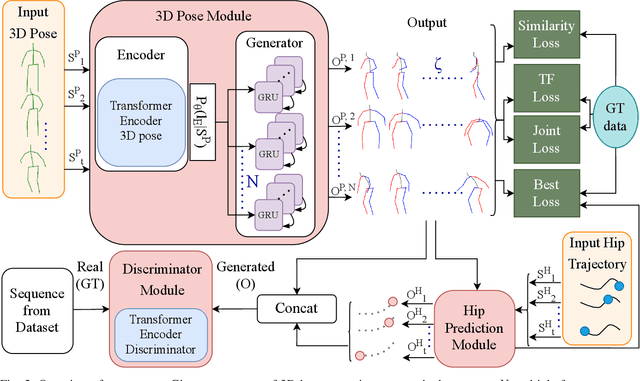
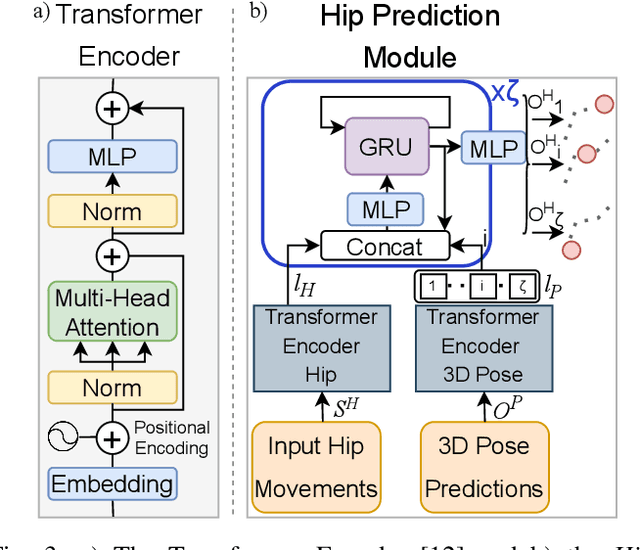
Human motion prediction is a fundamental part of many human-robot applications. Despite the recent progress in human motion prediction, most studies simplify the problem by predicting the human motion relative to a fixed joint and/or only limit their model to predict one possible future motion. While due to the complex nature of human motion, a single output cannot reflect all the possible actions one can do. Also, for any robotics application, we need the full human motion including the user trajectory not a 3d pose relative to the hip joint. In this paper, we try to address these two issues by proposing a transformer-based generative model for forecasting multiple diverse human motions. Our model generates \textit{N} future possible motion by querying a history of human motion. Our model first predicts the pose of the body relative to the hip joint. Then the \textit{Hip Prediction Module} predicts the trajectory of the hip movement for each predicted pose frame. To emphasize on the diverse future motions we introduce a similarity loss that penalizes the pairwise sample distance. We show that our system outperforms the state-of-the-art in human motion prediction while it can predict diverse multi-motion future trajectories with hip movements
LBGP: Learning Based Goal Planning for Autonomous Following in Front
Nov 05, 2020



This paper investigates a hybrid solution which combines deep reinforcement learning (RL) and classical trajectory planning for the following in front application. Here, an autonomous robot aims to stay ahead of a person as the person freely walks around. Following in front is a challenging problem as the user's intended trajectory is unknown and needs to be estimated, explicitly or implicitly, by the robot. In addition, the robot needs to find a feasible way to safely navigate ahead of human trajectory. Our deep RL module implicitly estimates human trajectory and produces short-term navigational goals to guide the robot. These goals are used by a trajectory planner to smoothly navigate the robot to the short-term goals, and eventually in front of the user. We employ curriculum learning in the deep RL module to efficiently achieve a high return. Our system outperforms the state-of-the-art in following ahead and is more reliable compared to end-to-end alternatives in both the simulation and real world experiments. In contrast to a pure deep RL approach, we demonstrate zero-shot transfer of the trained policy from simulation to the real world.
Relational Graph Learning for Crowd Navigation
Oct 01, 2019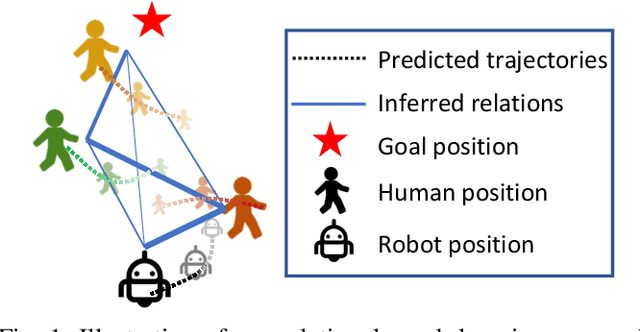
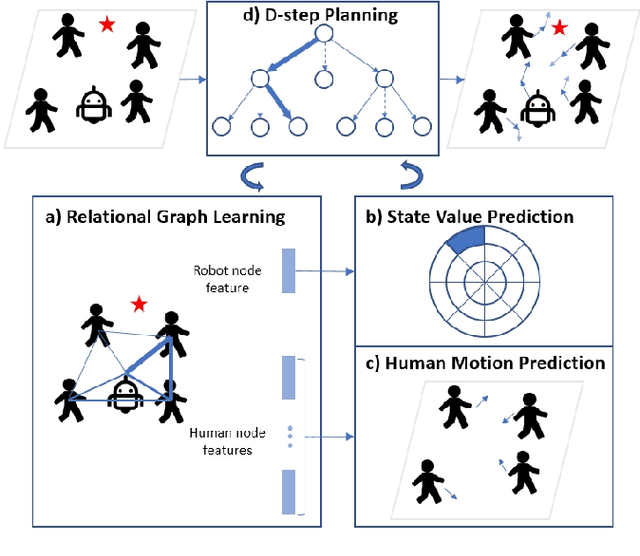
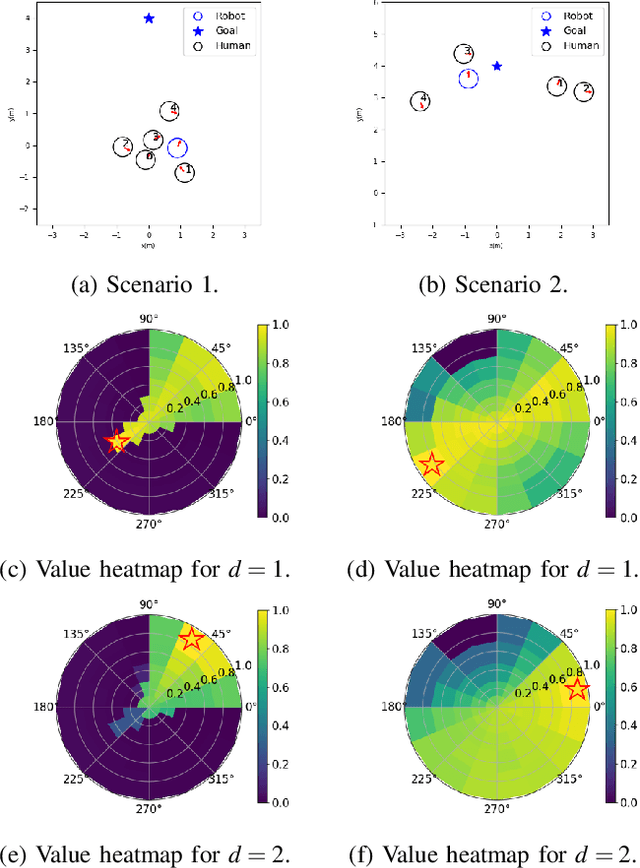

We present a relational graph learning approach for robotic crowd navigation using model-based deep reinforcement learning that plans actions by looking into the future. Our approach reasons about the relations between all agents based on their latent features and uses a Graph Convolutional Network to encode higher-order interactions in each agent's state representation, which is subsequently leveraged for state prediction and value estimation. The ability to predict human motion allows us to perform multi-step lookahead planning, taking into account the temporal evolution of human crowds. We evaluate our approach against a state-of-the-art baseline for crowd navigation and ablations of our model to demonstrate that navigation with our approach is more efficient, results in fewer collisions, and avoids failure cases involving oscillatory and freezing behaviors.
Recognizing and Tracking High-Level, Human-Meaningful Navigation Features of Occupancy Grid Maps
Mar 08, 2019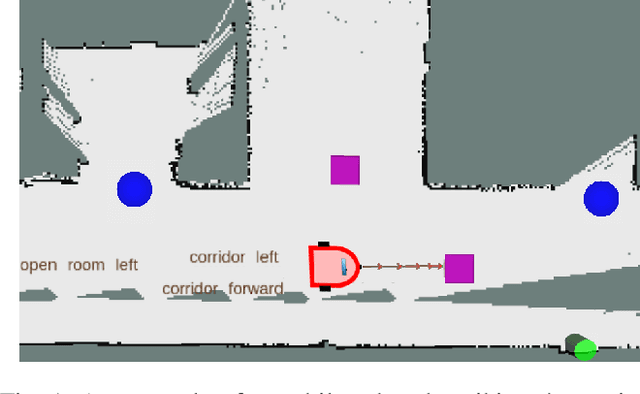
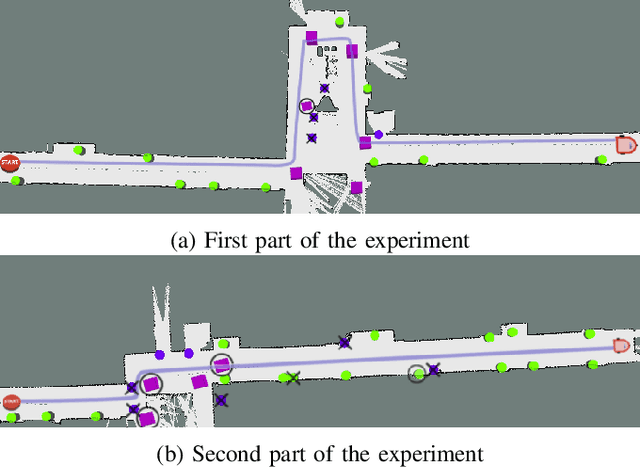
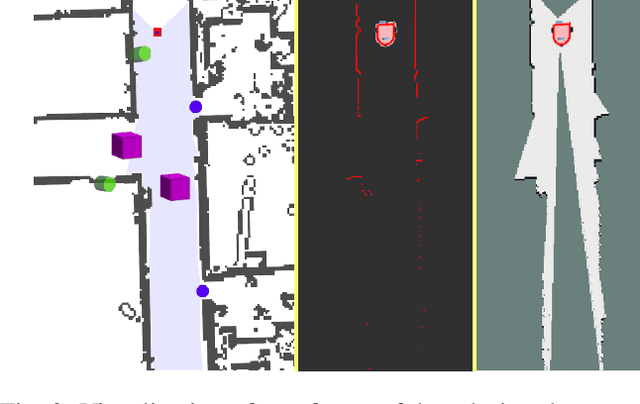
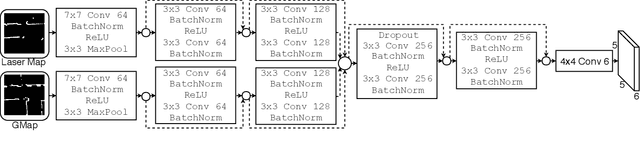
This paper describes a system whereby a robot detects and track human-meaningful navigational cues as it navigates in an indoor environment. It is intended as the sensor front-end for a mobile robot system that can communicate its navigational context with human users. From simulated LiDAR scan data we construct a set of 2D occupancy grid bitmaps, then hand-label these with human-scale navigational features such as closed doors, open corridors and intersections. We train a Convolutional Neural Network (CNN) to recognize these features on input bitmaps. In our demonstration system, these features are detected at every time step then passed to a tracking module that does frame-to-frame data association to improve detection accuracy and identify stable unique features. We evaluate the system in both simulation and the real world. We compare the performance of using input occupancy grids obtained directly from LiDAR data, or incrementally constructed with SLAM, and their combination.