 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Waymo Open Sim Agents Challenge
May 19, 2023In this work, we define the Waymo Open Sim Agents Challenge (WOSAC). Simulation with realistic, interactive agents represents a key task for autonomous vehicle software development. WOSAC is the first public challenge to tackle this task and propose corresponding metrics. The goal of the challenge is to stimulate the design of realistic simulators that can be used to evaluate and train a behavior model for autonomous driving. We outline our evaluation methodology and present preliminary results for a number of different baseline simulation agent methods.
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving
Oct 18, 2022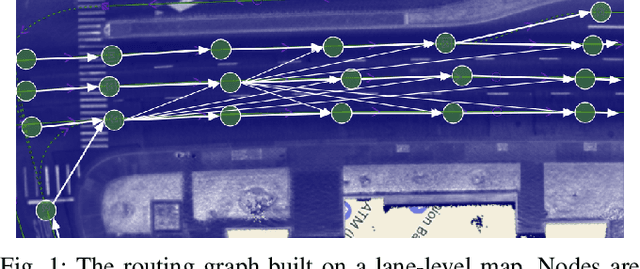
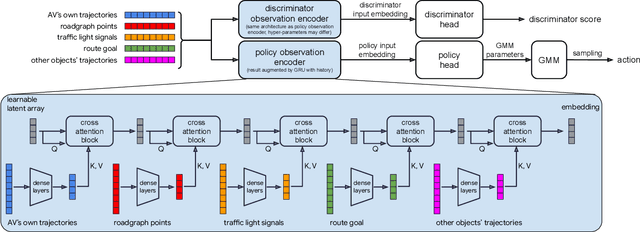
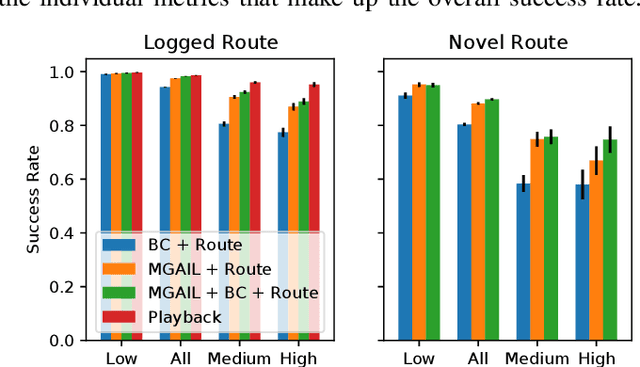
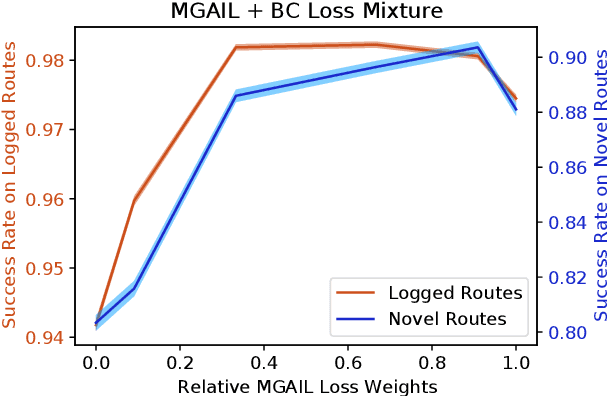
We demonstrate the first large-scale application of model-based generative adversarial imitation learning (MGAIL) to the task of dense urban self-driving. We augment standard MGAIL using a hierarchical model to enable generalization to arbitrary goal routes, and measure performance using a closed-loop evaluation framework with simulated interactive agents. We train policies from expert trajectories collected from real vehicles driving over 100,000 miles in San Francisco, and demonstrate a steerable policy that can navigate robustly even in a zero-shot setting, generalizing to synthetic scenarios with novel goals that never occurred in real-world driving. We also demonstrate the importance of mixing closed-loop MGAIL losses with open-loop behavior cloning losses, and show our best policy approaches the performance of the expert. We evaluate our imitative model in both average and challenging scenarios, and show how it can serve as a useful prior to plan successful trajectories.
Symphony: Learning Realistic and Diverse Agents for Autonomous Driving Simulation
May 06, 2022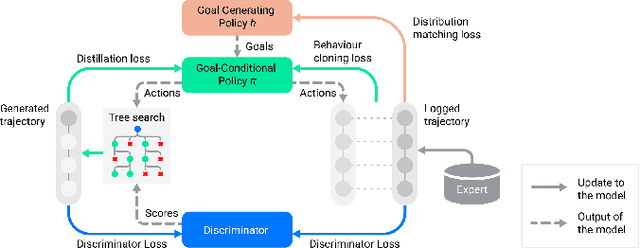
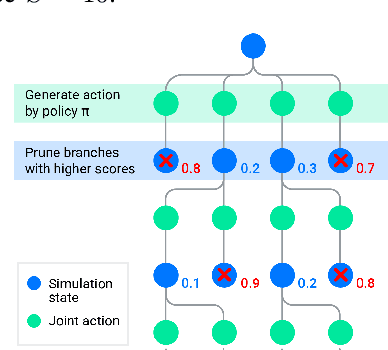
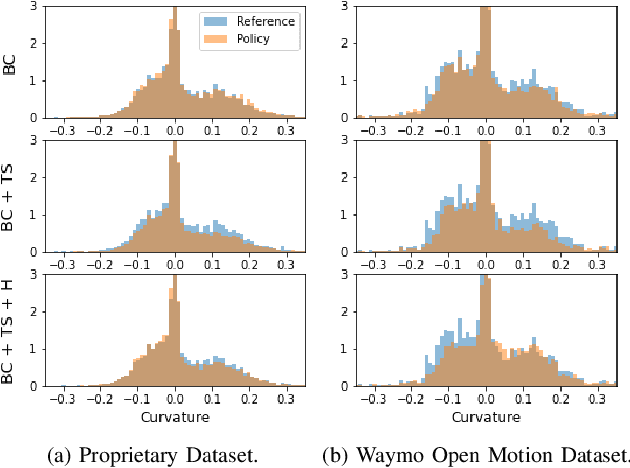
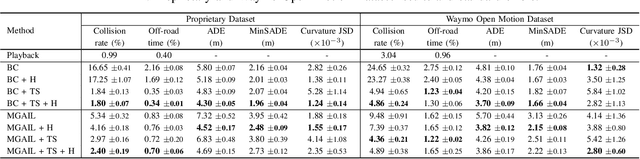
Simulation is a crucial tool for accelerating the development of autonomous vehicles. Making simulation realistic requires models of the human road users who interact with such cars. Such models can be obtained by applying learning from demonstration (LfD) to trajectories observed by cars already on the road. However, existing LfD methods are typically insufficient, yielding policies that frequently collide or drive off the road. To address this problem, we propose Symphony, which greatly improves realism by combining conventional policies with a parallel beam search. The beam search refines these policies on the fly by pruning branches that are unfavourably evaluated by a discriminator. However, it can also harm diversity, i.e., how well the agents cover the entire distribution of realistic behaviour, as pruning can encourage mode collapse. Symphony addresses this issue with a hierarchical approach, factoring agent behaviour into goal generation and goal conditioning. The use of such goals ensures that agent diversity neither disappears during adversarial training nor is pruned away by the beam search. Experiments on both proprietary and open Waymo datasets confirm that Symphony agents learn more realistic and diverse behaviour than several baselines.
Depth by Poking: Learning to Estimate Depth from Self-Supervised Grasping
Jun 16, 2020


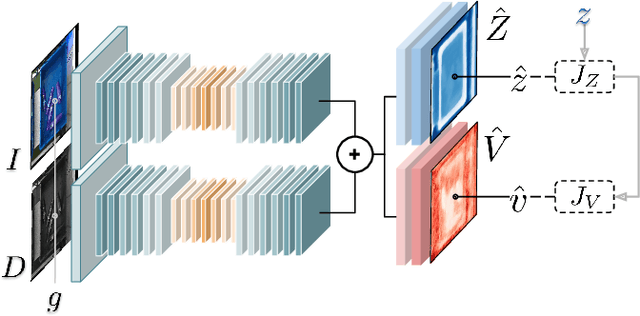
Accurate depth estimation remains an open problem for robotic manipulation; even state of the art techniques including structured light and LiDAR sensors fail on reflective or transparent surfaces. We address this problem by training a neural network model to estimate depth from RGB-D images, using labels from physical interactions between a robot and its environment. Our network predicts, for each pixel in an input image, the z position that a robot's end effector would reach if it attempted to grasp or poke at the corresponding position. Given an autonomous grasping policy, our approach is self-supervised as end effector position labels can be recovered through forward kinematics, without human annotation. Although gathering such physical interaction data is expensive, it is necessary for training and routine operation of state of the art manipulation systems. Therefore, this depth estimator comes ``for free'' while collecting data for other tasks (e.g., grasping, pushing, placing). We show our approach achieves significantly lower root mean squared error than traditional structured light sensors and unsupervised deep learning methods on difficult, industry-scale jumbled bin datasets.
Modeling Human Driving Behavior through Generative Adversarial Imitation Learning
Jun 10, 2020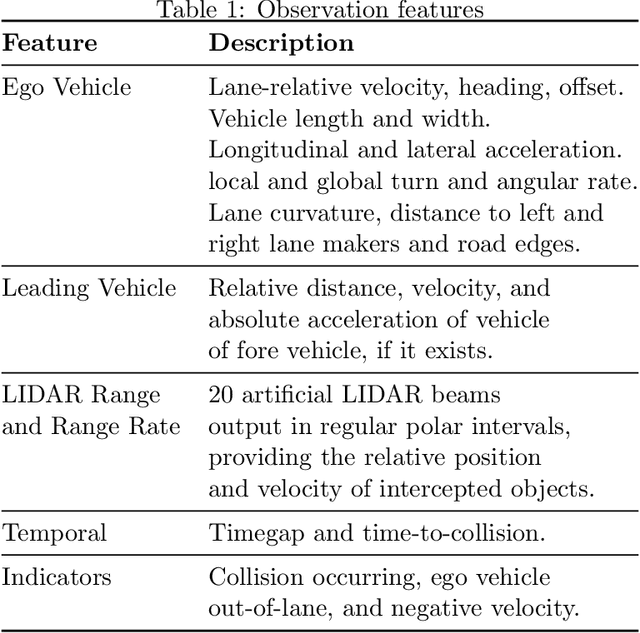
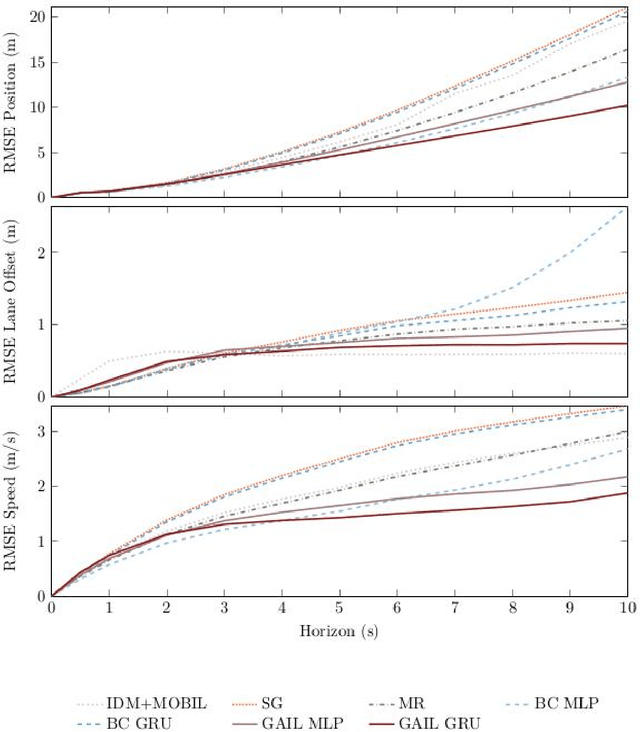
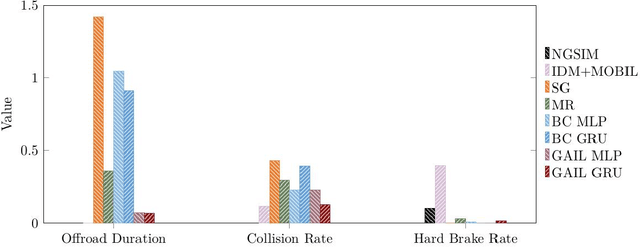
Imitation learning is an approach for generating intelligent behavior when the cost function is unknown or difficult to specify. Building upon work in inverse reinforcement learning (IRL), Generative Adversarial Imitation Learning (GAIL) aims to provide effective imitation even for problems with large or continuous state and action spaces. Driver modeling is one example of a problem where the state and action spaces are continuous. Human driving behavior is characterized by non-linearity and stochasticity, and the underlying cost function is unknown. As a result, learning from human driving demonstrations is a promising approach for generating human-like driving behavior. This article describes the use of GAIL for learning-based driver modeling. Because driver modeling is inherently a multi-agent problem, where the interaction between agents needs to be modeled, this paper describes a parameter-sharing extension of GAIL called PS-GAIL to tackle multi-agent driver modeling. In addition, GAIL is domain agnostic, making it difficult to encode specific knowledge relevant to driving in the learning process. This paper describes Reward Augmented Imitation Learning (RAIL), which modifies the reward signal to provide domain-specific knowledge to the agent. Finally, human demonstrations are dependent upon latent factors that may not be captured by GAIL. This paper describes Burn-InfoGAIL, which allows for disentanglement of latent variability in demonstrations. Imitation learning experiments are performed using NGSIM, a real-world highway driving dataset. Experiments show that these modifications to GAIL can successfully model highway driving behavior, accurately replicating human demonstrations and generating realistic, emergent behavior in the traffic flow arising from the interaction between driving agents.
Multi-Agent Imitation Learning for Driving Simulation
Mar 02, 2018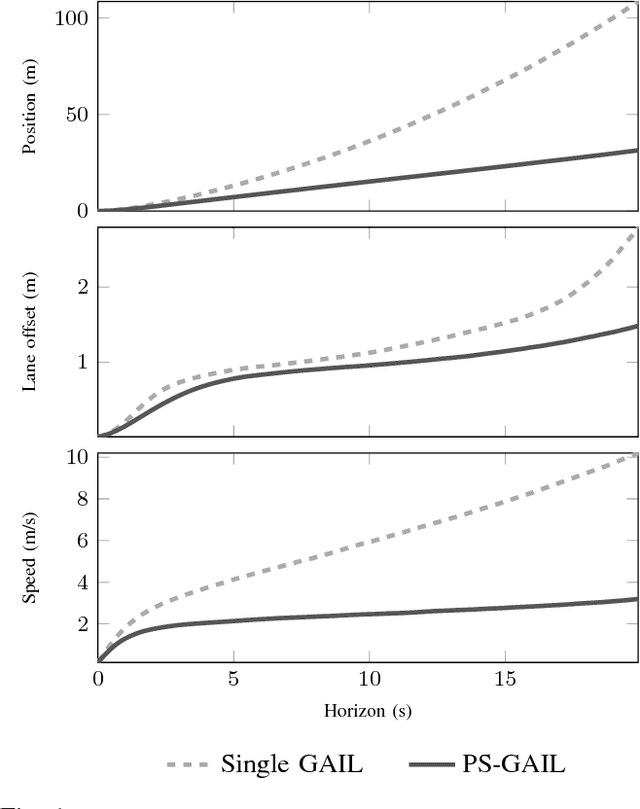
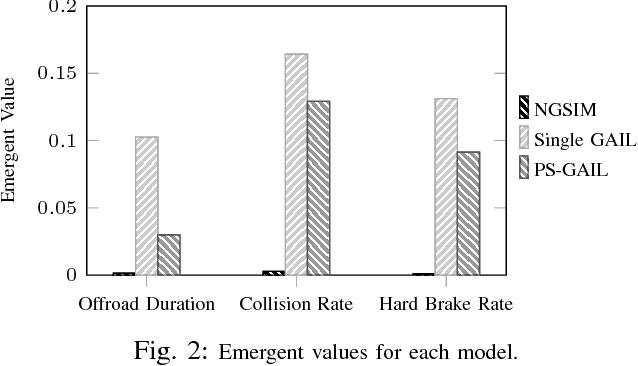
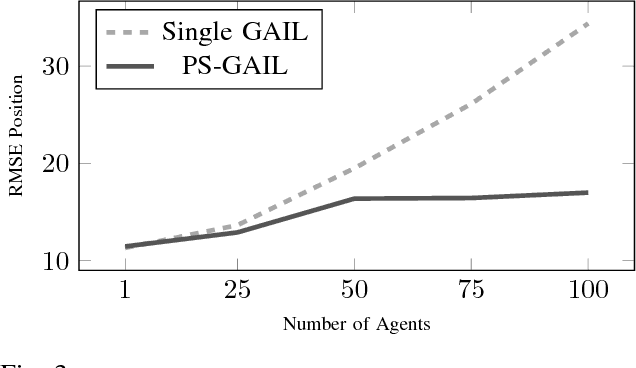
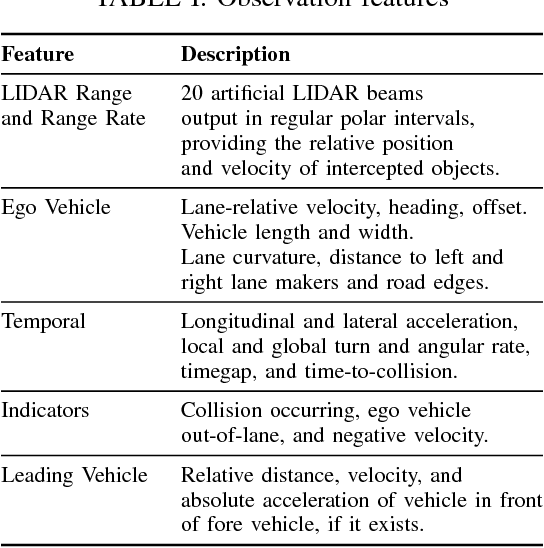
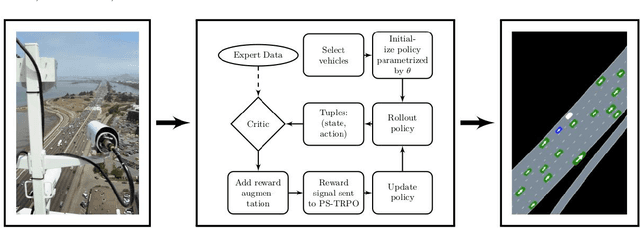
Simulation is an appealing option for validating the safety of autonomous vehicles. Generative Adversarial Imitation Learning (GAIL) has recently been shown to learn representative human driver models. These human driver models were learned through training in single-agent environments, but they have difficulty in generalizing to multi-agent driving scenarios. We argue these difficulties arise because observations at training and test time are sampled from different distributions. This difference makes such models unsuitable for the simulation of driving scenes, where multiple agents must interact realistically over long time horizons. We extend GAIL to address these shortcomings through a parameter-sharing approach grounded in curriculum learning. Compared with single-agent GAIL policies, policies generated by our PS-GAIL method prove superior at interacting stably in a multi-agent setting and capturing the emergent behavior of human drivers.
Burn-In Demonstrations for Multi-Modal Imitation Learning
Oct 13, 2017
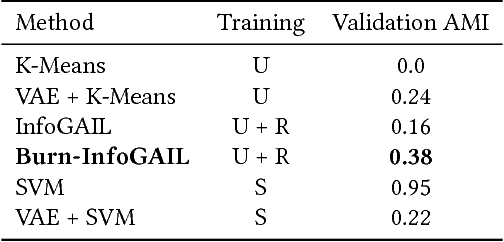
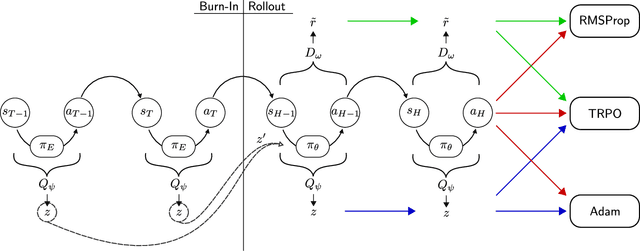
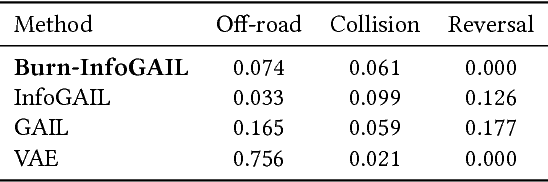
Recent work on imitation learning has generated policies that reproduce expert behavior from multi-modal data. However, past approaches have focused only on recreating a small number of distinct, expert maneuvers, or have relied on supervised learning techniques that produce unstable policies. This work extends InfoGAIL, an algorithm for multi-modal imitation learning, to reproduce behavior over an extended period of time. Our approach involves reformulating the typical imitation learning setting to include "burn-in demonstrations" upon which policies are conditioned at test time. We demonstrate that our approach outperforms standard InfoGAIL in maximizing the mutual information between predicted and unseen style labels in road scene simulations, and we show that our method leads to policies that imitate expert autonomous driving systems over long time horizons.
Imitating Driver Behavior with Generative Adversarial Networks
Jan 24, 2017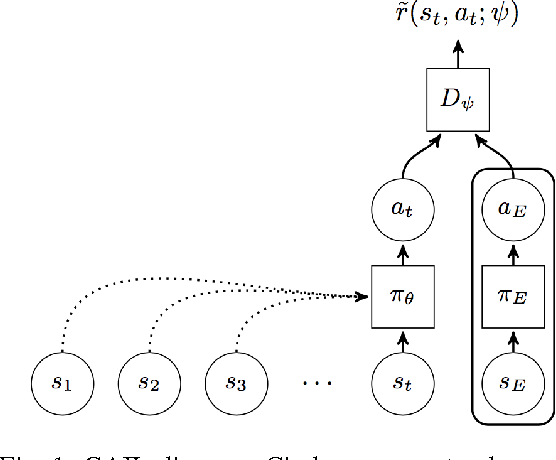
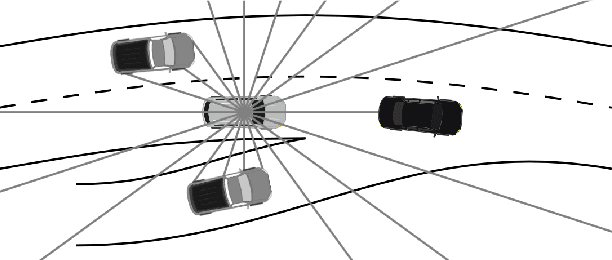
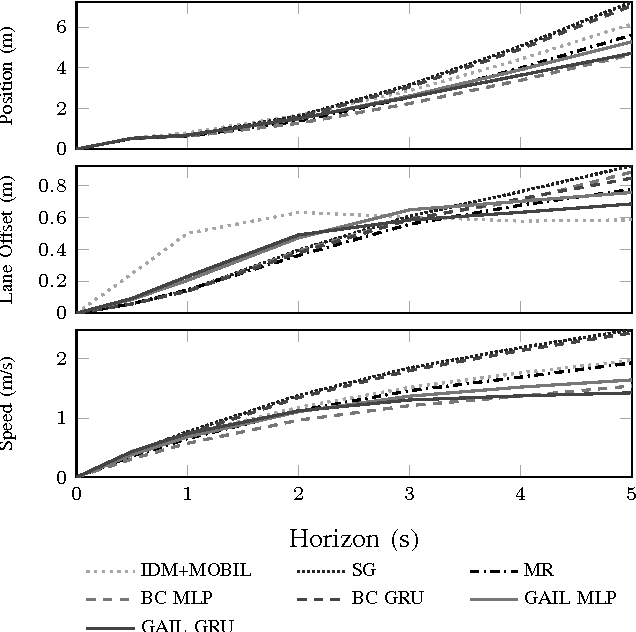
The ability to accurately predict and simulate human driving behavior is critical for the development of intelligent transportation systems. Traditional modeling methods have employed simple parametric models and behavioral cloning. This paper adopts a method for overcoming the problem of cascading errors inherent in prior approaches, resulting in realistic behavior that is robust to trajectory perturbations. We extend Generative Adversarial Imitation Learning to the training of recurrent policies, and we demonstrate that our model outperforms rule-based controllers and maximum likelihood models in realistic highway simulations. Our model both reproduces emergent behavior of human drivers, such as lane change rate, while maintaining realistic control over long time horizons.