 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth by Poking: Learning to Estimate Depth from Self-Supervised Grasping
Jun 16, 2020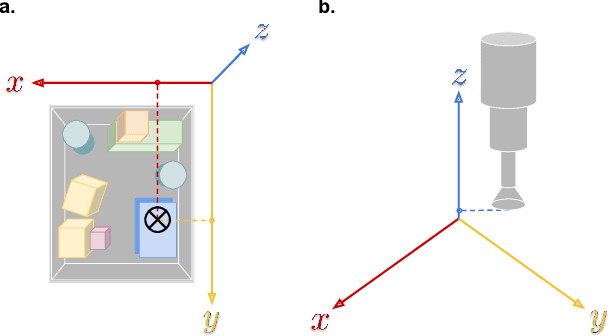


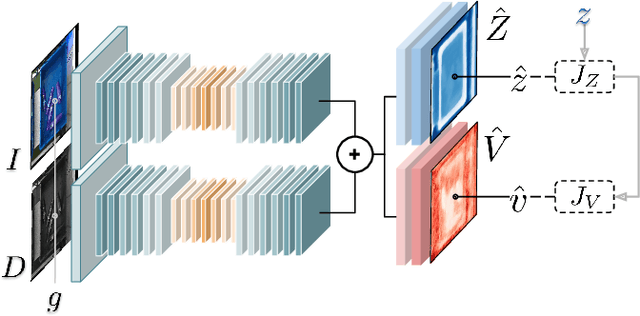
Accurate depth estimation remains an open problem for robotic manipulation; even state of the art techniques including structured light and LiDAR sensors fail on reflective or transparent surfaces. We address this problem by training a neural network model to estimate depth from RGB-D images, using labels from physical interactions between a robot and its environment. Our network predicts, for each pixel in an input image, the z position that a robot's end effector would reach if it attempted to grasp or poke at the corresponding position. Given an autonomous grasping policy, our approach is self-supervised as end effector position labels can be recovered through forward kinematics, without human annotation. Although gathering such physical interaction data is expensive, it is necessary for training and routine operation of state of the art manipulation systems. Therefore, this depth estimator comes ``for free'' while collecting data for other tasks (e.g., grasping, pushing, placing). We show our approach achieves significantly lower root mean squared error than traditional structured light sensors and unsupervised deep learning methods on difficult, industry-scale jumbled bin datasets.
Neural Assistant: Joint Action Prediction, Response Generation, and Latent Knowledge Reasoning
Oct 31, 2019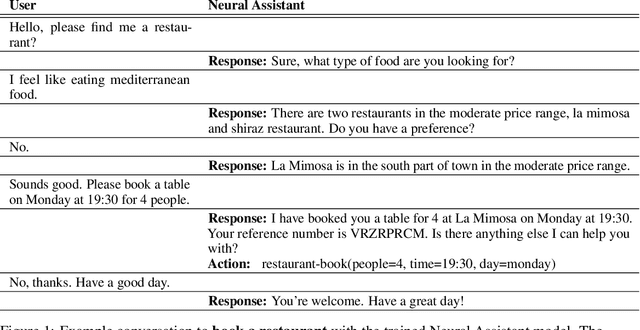
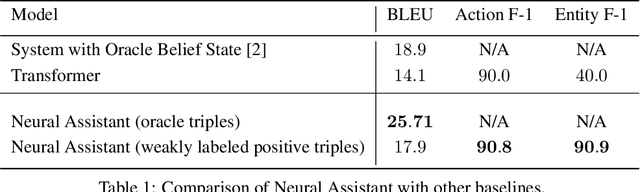
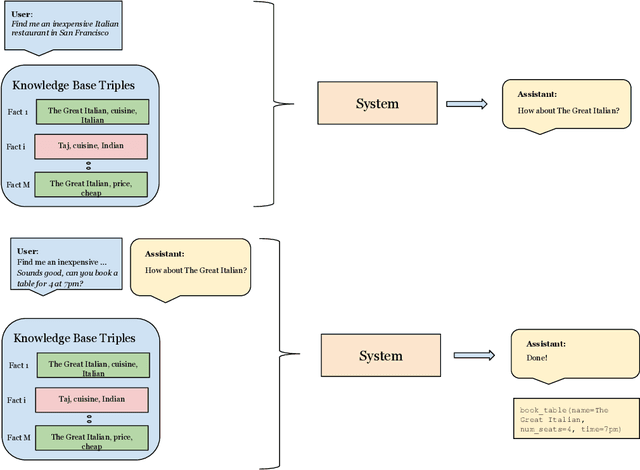
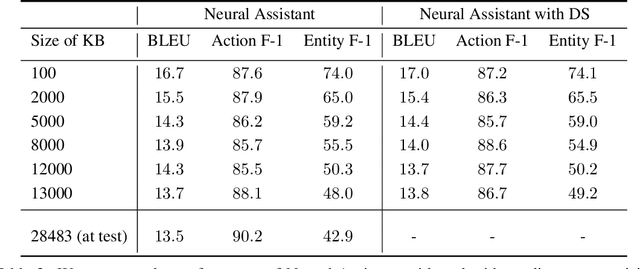
Task-oriented dialog presents a difficult challenge encompassing multiple problems including multi-turn language understanding and generation, knowledge retrieval and reasoning, and action prediction. Modern dialog systems typically begin by converting conversation history to a symbolic object referred to as belief state by using supervised learning. The belief state is then used to reason on an external knowledge source whose result along with the conversation history is used in action prediction and response generation tasks independently. Such a pipeline of individually optimized components not only makes the development process cumbersome but also makes it non-trivial to leverage session-level user reinforcement signals. In this paper, we develop Neural Assistant: a single neural network model that takes conversation history and an external knowledge source as input and jointly produces both text response and action to be taken by the system as output. The model learns to reason on the provided knowledge source with weak supervision signal coming from the text generation and the action prediction tasks, hence removing the need for belief state annotations. In the MultiWOZ dataset, we study the effect of distant supervision, and the size of knowledge base on model performance. We find that the Neural Assistant without belief states is able to incorporate external knowledge information achieving higher factual accuracy scores compared to Transformer. In settings comparable to reported baseline systems, Neural Assistant when provided with oracle belief state significantly improves language generation performance.
Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset
Sep 01, 2019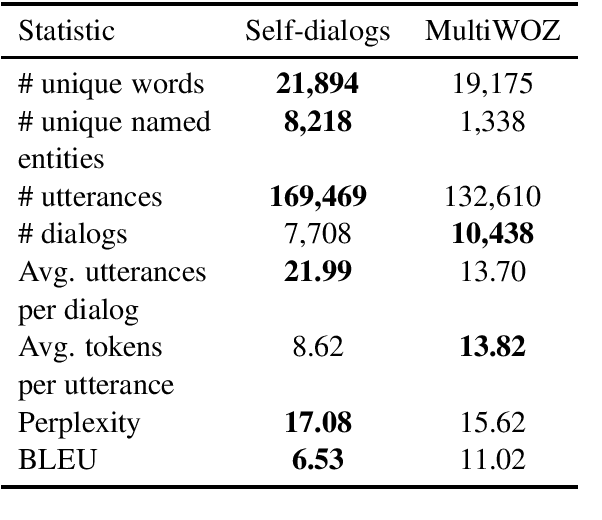

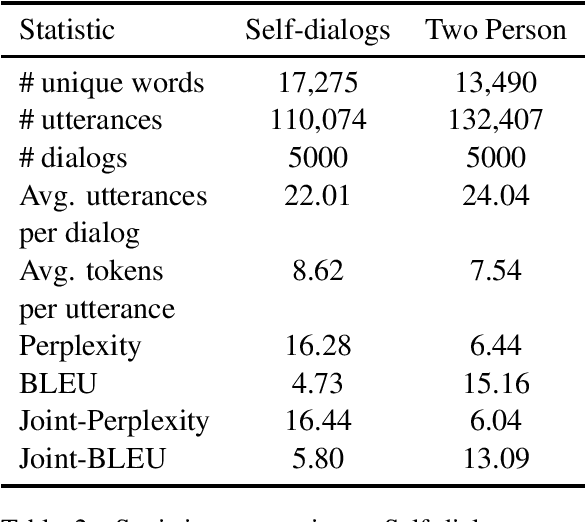
A significant barrier to progress in data-driven approaches to building dialog systems is the lack of high quality, goal-oriented conversational data. To help satisfy this elementary requirement, we introduce the initial release of the Taskmaster-1 dataset which includes 13,215 task-based dialogs comprising six domains. Two procedures were used to create this collection, each with unique advantages. The first involves a two-person, spoken "Wizard of Oz" (WOz) approach in which trained agents and crowdsourced workers interact to complete the task while the second is "self-dialog" in which crowdsourced workers write the entire dialog themselves. We do not restrict the workers to detailed scripts or to a small knowledge base and hence we observe that our dataset contains more realistic and diverse conversations in comparison to existing datasets. We offer several baseline models including state of the art neural seq2seq architectures with benchmark performance as well as qualitative human evaluations. Dialogs are labeled with API calls and arguments, a simple and cost effective approach which avoids the requirement of complex annotation schema. The layer of abstraction between the dialog model and the service provider API allows for a given model to interact with multiple services that provide similar functionally. Finally, the dataset will evoke interest in written vs. spoken language, discourse patterns, error handling and other linguistic phenomena related to dialog system research, development and design.
Parallel Scheduled Sampling
Jun 11, 2019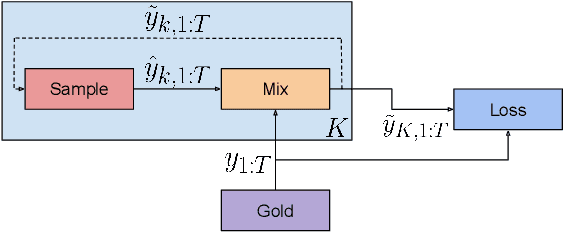
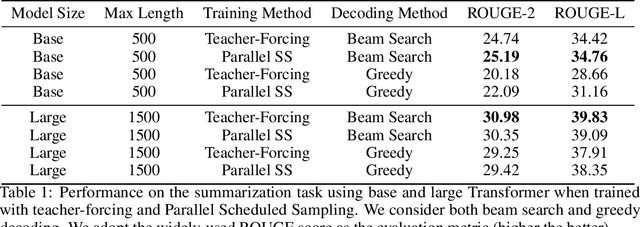
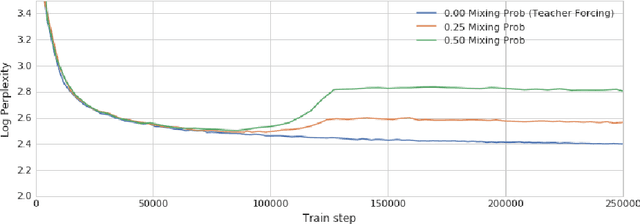
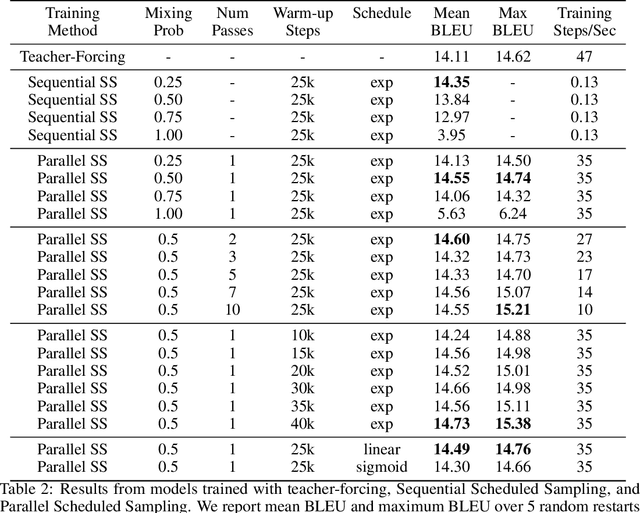
Auto-regressive models are widely used in sequence generation problems. The output sequence is typically generated in a predetermined order, one discrete unit (pixel or word or character) at a time. The models are trained by teacher-forcing where ground-truth history is fed to the model as input, which at test time is replaced by the model prediction. Scheduled Sampling aims to mitigate this discrepancy between train and test time by randomly replacing some discrete units in the history with the model's prediction. While teacher-forced training works well with ML accelerators as the computation can be parallelized across time, Scheduled Sampling involves undesirable sequential processing. In this paper, we introduce a simple technique to parallelize Scheduled Sampling across time. We find that in most cases our technique leads to better empirical performance on summarization and dialog generation tasks compared to teacher-forced training. Further, we discuss the effects of different hyper-parameters associated with Scheduled Sampling on the model performance.
Assessing The Factual Accuracy of Generated Text
May 30, 2019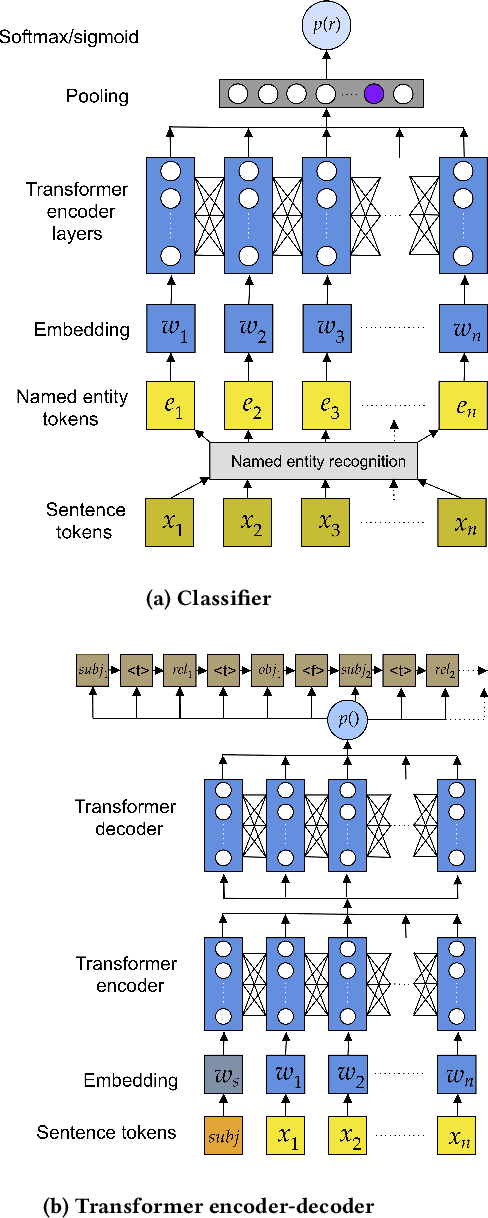
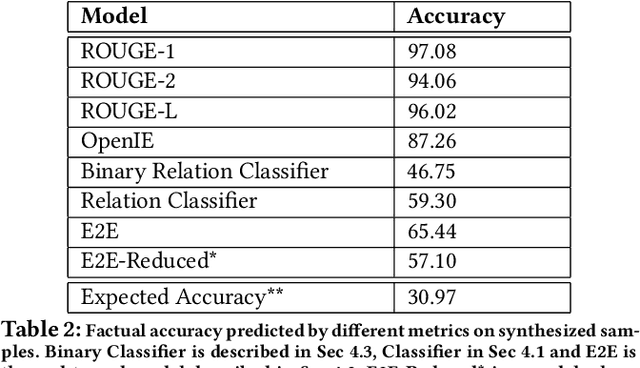

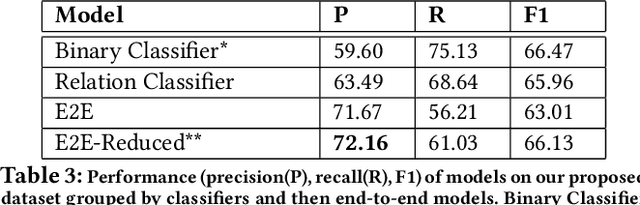
We propose a model-based metric to estimate the factual accuracy of generated text that is complementary to typical scoring schemes like ROUGE (Recall-Oriented Understudy for Gisting Evaluation) and BLEU (Bilingual Evaluation Understudy). We introduce and release a new large-scale dataset based on Wikipedia and Wikidata to train relation classifiers and end-to-end fact extraction models. The end-to-end models are shown to be able to extract complete sets of facts from datasets with full pages of text. We then analyse multiple models that estimate factual accuracy on a Wikipedia text summarization task, and show their efficacy compared to ROUGE and other model-free variants by conducting a human evaluation study.
Generating Wikipedia by Summarizing Long Sequences
Jan 30, 2018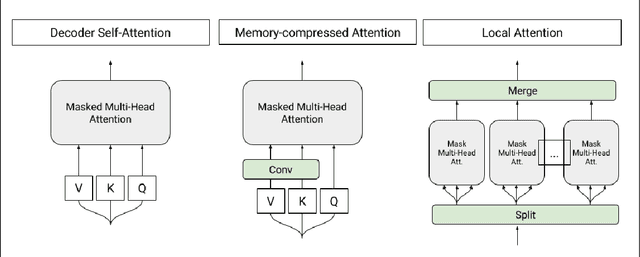

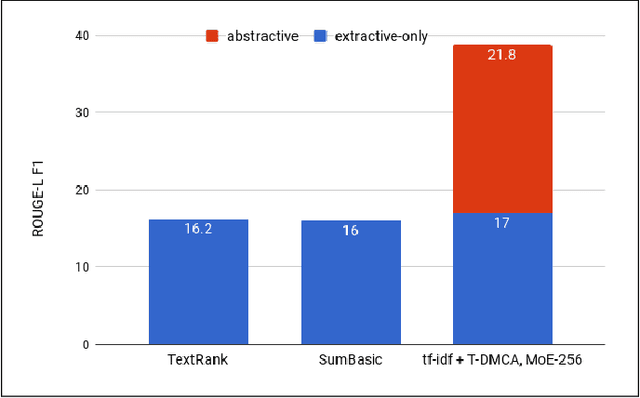

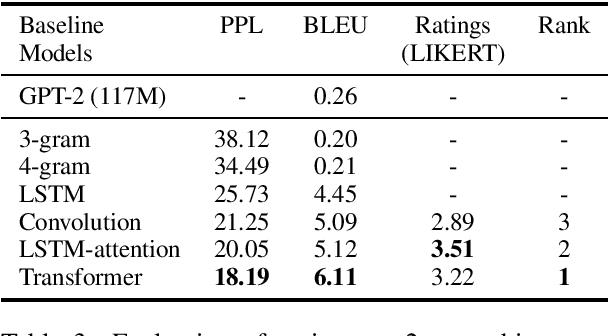
We show that generating English Wikipedia articles can be approached as a multi- document summarization of source documents. We use extractive summarization to coarsely identify salient information and a neural abstractive model to generate the article. For the abstractive model, we introduce a decoder-only architecture that can scalably attend to very long sequences, much longer than typical encoder- decoder architectures used in sequence transduction. We show that this model can generate fluent, coherent multi-sentence paragraphs and even whole Wikipedia articles. When given reference documents, we show it can extract relevant factual information as reflected in perplexity, ROUGE scores and human evaluations.