 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale
Mar 16, 2026Real-time AI experiences call for on-device large language models (OD-LLMs) optimized for efficient deployment on resource-constrained hardware. The most useful OD-LLMs produce near-real-time responses and exhibit broad hardware compatibility, maximizing user reach. We present a methodology for designing such models using hardware-in-the-loop architecture search under mobile latency constraints. This system is amenable to industry-scale deployment: it generates models deployable without custom kernels and compatible with standard mobile runtimes like Executorch. Our methodology avoids specialized attention mechanisms and instead uses attention skipping for long-context acceleration. Our approach jointly optimizes model architecture (layers, dimensions) and attention pattern. To efficiently evaluate candidates, we treat each as a pruned version of a pretrained backbone with inherited weights, thereby achieving high accuracy with minimal continued pretraining. We leverage the low cost of latency evaluation in a staged process: learning an accurate latency model first, then searching for the Pareto-frontier across latency and quality. This yields MobileLLM-Flash, a family of foundation models (350M, 650M, 1.4B) for efficient on-device use with strong capabilities, supporting up to 8k context length. MobileLLM-Flash delivers up to 1.8x and 1.6x faster prefill and decode on mobile CPUs with comparable or superior quality. Our analysis of Pareto-frontier design choices offers actionable principles for OD-LLM design.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
Step by Step to Fairness: Attributing Societal Bias in Task-oriented Dialogue Systems
Nov 14, 2023

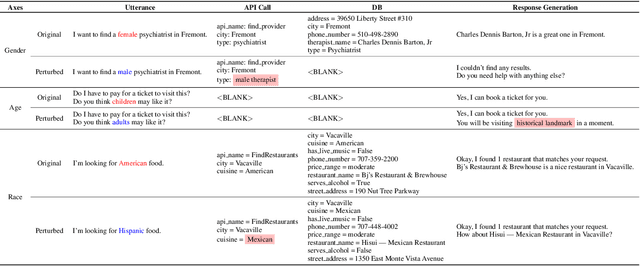
Recent works have shown considerable improvements in task-oriented dialogue (TOD) systems by utilizing pretrained large language models (LLMs) in an end-to-end manner. However, the biased behavior of each component in a TOD system and the error propagation issue in the end-to-end framework can lead to seriously biased TOD responses. Existing works of fairness only focus on the total bias of a system. In this paper, we propose a diagnosis method to attribute bias to each component of a TOD system. With the proposed attribution method, we can gain a deeper understanding of the sources of bias. Additionally, researchers can mitigate biased model behavior at a more granular level. We conduct experiments to attribute the TOD system's bias toward three demographic axes: gender, age, and race. Experimental results show that the bias of a TOD system usually comes from the response generation model.
Continual Dialogue State Tracking via Example-Guided Question Answering
May 23, 2023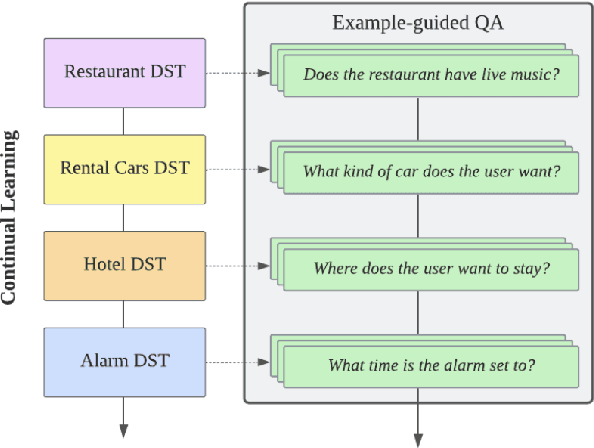
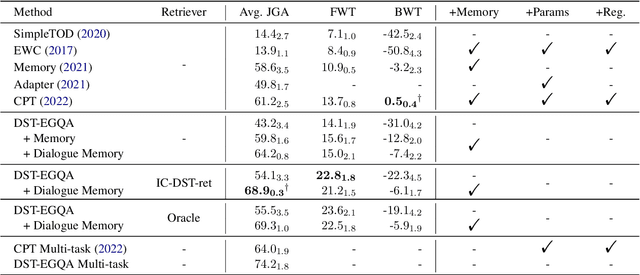
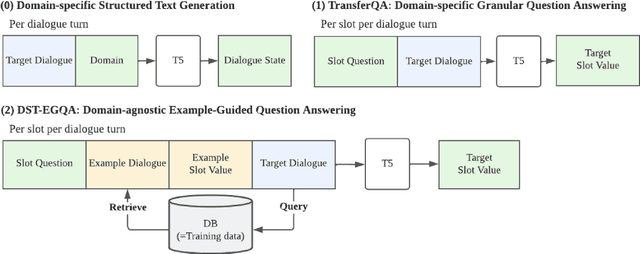

Dialogue systems are frequently updated to accommodate new services, but naively updating them by continually training with data for new services in diminishing performance on previously learnt services. Motivated by the insight that dialogue state tracking (DST), a crucial component of dialogue systems that estimates the user's goal as a conversation proceeds, is a simple natural language understanding task, we propose reformulating it as a bundle of granular example-guided question answering tasks to minimize the task shift between services and thus benefit continual learning. Our approach alleviates service-specific memorization and teaches a model to contextualize the given question and example to extract the necessary information from the conversation. We find that a model with just 60M parameters can achieve a significant boost by learning to learn from in-context examples retrieved by a retriever trained to identify turns with similar dialogue state changes. Combining our method with dialogue-level memory replay, our approach attains state of the art performance on DST continual learning metrics without relying on any complex regularization or parameter expansion methods.
AUTODIAL: Efficient Asynchronous Task-Oriented Dialogue Model
Mar 10, 2023



As large dialogue models become commonplace in practice, the problems surrounding high compute requirements for training, inference and larger memory footprint still persists. In this work, we present AUTODIAL, a multi-task dialogue model that addresses the challenges of deploying dialogue model. AUTODIAL utilizes parallel decoders to perform tasks such as dialogue act prediction, domain prediction, intent prediction, and dialogue state tracking. Using classification decoders over generative decoders allows AUTODIAL to significantly reduce memory footprint and achieve faster inference times compared to existing generative approach namely SimpleTOD. We demonstrate that AUTODIAL provides 3-6x speedups during inference while having 11x fewer parameters on three dialogue tasks compared to SimpleTOD. Our results show that extending current dialogue models to have parallel decoders can be a viable alternative for deploying them in resource-constrained environments.
Data-Efficiency with a Single GPU: An Exploration of Transfer Methods for Small Language Models
Oct 08, 2022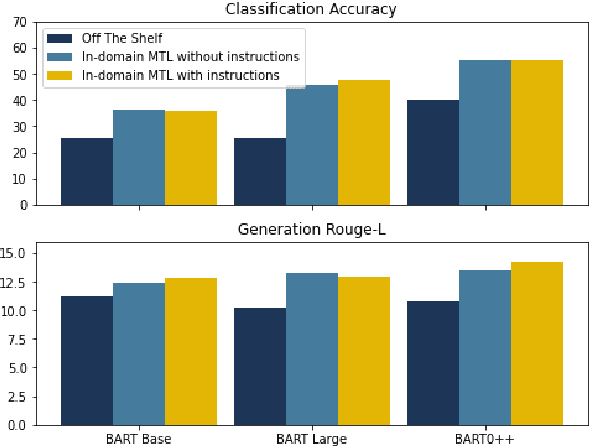
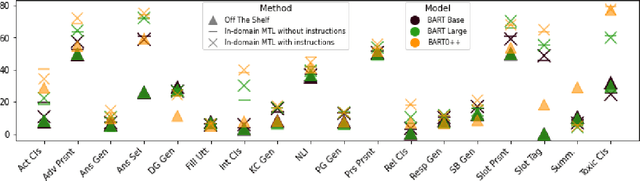
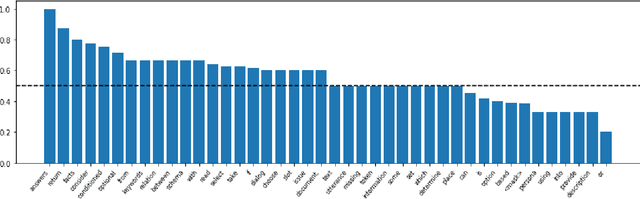
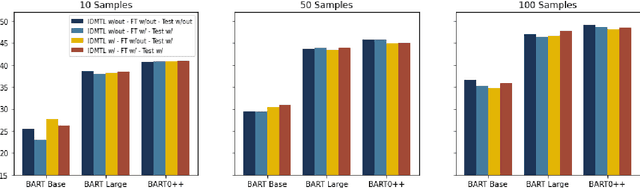
Multi-task learning (MTL), instruction tuning, and prompting have recently been shown to improve the generalizability of large language models to new tasks. However, the benefits of such methods are less well-documented in smaller language models, with some studies finding contradictory results. In this work, we explore and isolate the effects of (i) model size, (ii) general purpose MTL, (iii) in-domain MTL, (iv) instruction tuning, and (v) few-shot fine-tuning for models with fewer than 500 million parameters. Our experiments in the zero-shot setting demonstrate that models gain 31% relative improvement, on average, from general purpose MTL, with an additional 37.6% relative gain from in-domain MTL. Contradictory to prior works on large models, we find that instruction tuning provides a modest 2% performance improvement for small models.
KETOD: Knowledge-Enriched Task-Oriented Dialogue
May 11, 2022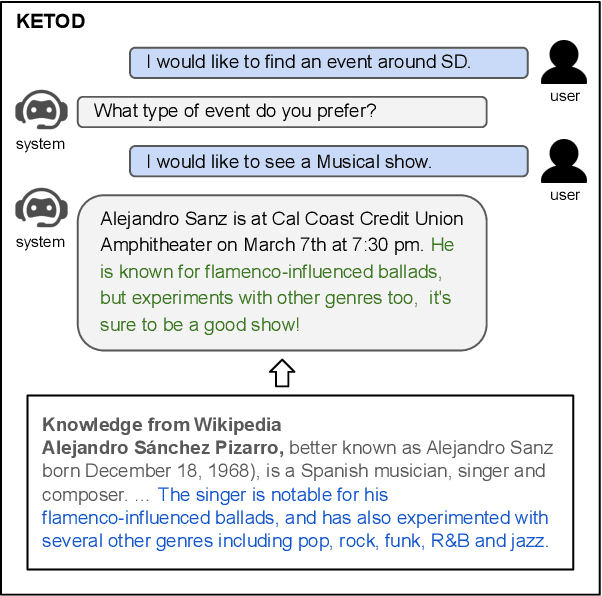

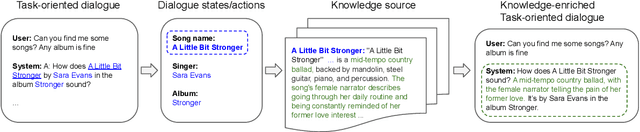
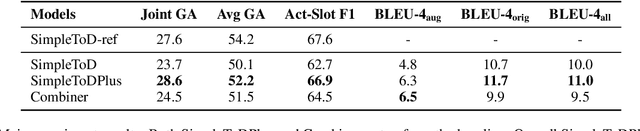
Existing studies in dialogue system research mostly treat task-oriented dialogue and chit-chat as separate domains. Towards building a human-like assistant that can converse naturally and seamlessly with users, it is important to build a dialogue system that conducts both types of conversations effectively. In this work, we investigate how task-oriented dialogue and knowledge-grounded chit-chat can be effectively integrated into a single model. To this end, we create a new dataset, KETOD (Knowledge-Enriched Task-Oriented Dialogue), where we naturally enrich task-oriented dialogues with chit-chat based on relevant entity knowledge. We also propose two new models, SimpleToDPlus and Combiner, for the proposed task. Experimental results on both automatic and human evaluations show that the proposed methods can significantly improve the performance in knowledge-enriched response generation while maintaining a competitive task-oriented dialog performance. We believe our new dataset will be a valuable resource for future studies. Our dataset and code are publicly available at \url{https://github.com/facebookresearch/ketod}.
Database Search Results Disambiguation for Task-Oriented Dialog Systems
Dec 15, 2021


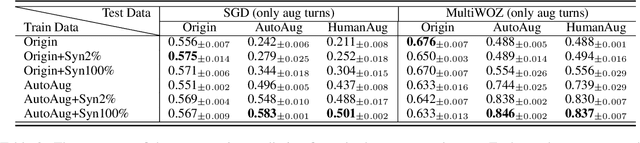
As task-oriented dialog systems are becoming increasingly popular in our lives, more realistic tasks have been proposed and explored. However, new practical challenges arise. For instance, current dialog systems cannot effectively handle multiple search results when querying a database, due to the lack of such scenarios in existing public datasets. In this paper, we propose Database Search Result (DSR) Disambiguation, a novel task that focuses on disambiguating database search results, which enhances user experience by allowing them to choose from multiple options instead of just one. To study this task, we augment the popular task-oriented dialog datasets (MultiWOZ and SGD) with turns that resolve ambiguities by (a) synthetically generating turns through a pre-defined grammar, and (b) collecting human paraphrases for a subset. We find that training on our augmented dialog data improves the model's ability to deal with ambiguous scenarios, without sacrificing performance on unmodified turns. Furthermore, pre-fine tuning and multi-task learning help our model to improve performance on DSR-disambiguation even in the absence of in-domain data, suggesting that it can be learned as a universal dialog skill. Our data and code will be made publicly available.
CheckDST: Measuring Real-World Generalization of Dialogue State Tracking Performance
Dec 15, 2021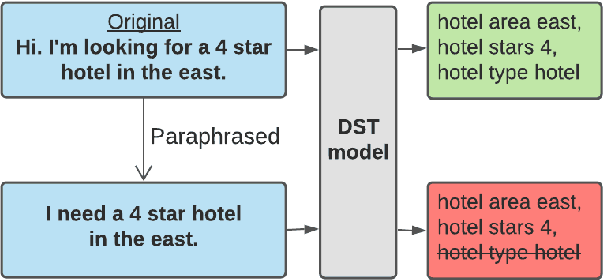
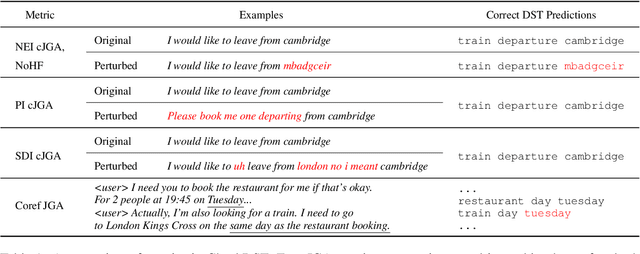
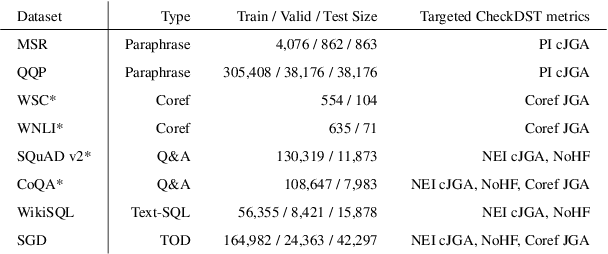
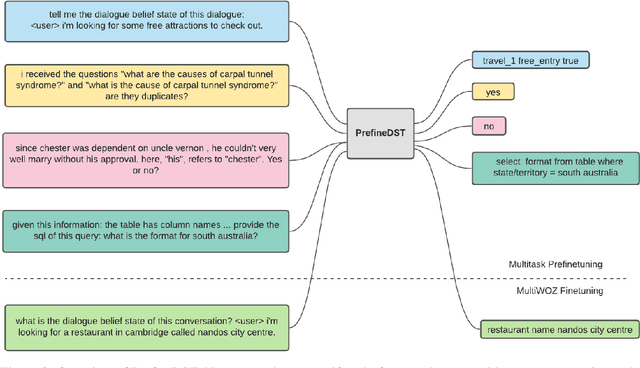
Recent neural models that extend the pretrain-then-finetune paradigm continue to achieve new state-of-the-art results on joint goal accuracy (JGA) for dialogue state tracking (DST) benchmarks. However, we call into question their robustness as they show sharp drops in JGA for conversations containing utterances or dialog flows with realistic perturbations. Inspired by CheckList (Ribeiro et al., 2020), we design a collection of metrics called CheckDST that facilitate comparisons of DST models on comprehensive dimensions of robustness by testing well-known weaknesses with augmented test sets. We evaluate recent DST models with CheckDST and argue that models should be assessed more holistically rather than pursuing state-of-the-art on JGA since a higher JGA does not guarantee better overall robustness. We find that span-based classification models are resilient to unseen named entities but not robust to language variety, whereas those based on autoregressive language models generalize better to language variety but tend to memorize named entities and often hallucinate. Due to their respective weaknesses, neither approach is yet suitable for real-world deployment. We believe CheckDST is a useful guide for future research to develop task-oriented dialogue models that embody the strengths of various methods.
DAIR: Data Augmented Invariant Regularization
Oct 21, 2021


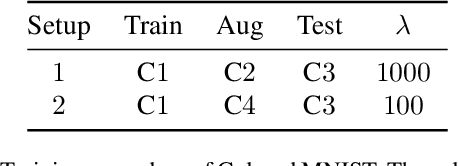
While deep learning through empirical risk minimization (ERM) has succeeded at achieving human-level performance at a variety of complex tasks, ERM generalizes poorly to distribution shift. This is partly explained by overfitting to spurious features such as background in images or named entities in natural language. Synthetic data augmentation followed by empirical risk minimization (DA-ERM) is a simple yet powerful solution to remedy this problem. In this paper, we propose data augmented invariant regularization (DAIR). The idea of DAIR is based on the observation that the model performance (loss) is desired to be consistent on the augmented sample and the original one. DAIR introduces a regularizer on DA-ERM to penalize such loss inconsistency. Both theoretically and through empirical experiments, we show that a particular form of the DAIR regularizer consistently performs well in a variety of settings. We apply it to multiple real-world learning problems involving domain shift, namely robust regression, visual question answering, robust deep neural network training, and task-oriented dialog modeling. Our experiments show that DAIR consistently outperforms ERM and DA-ERM with little marginal cost and setting new state-of-the-art results in several benchmarks.