 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedTRPO: Trajectory Reduction in Policy Optimization of Diffusion Large Language Models
Mar 19, 2026Diffusion Large Language Models (dLLMs) introduce a new paradigm for language generation, which in turn presents new challenges for aligning them with human preferences. In this work, we aim to improve the policy optimization for dLLMs by reducing the cost of the trajectory probability calculation, thereby enabling scaled-up offline policy training. We prove that: (i) under reference policy regularization, the probability ratio of the newly unmasked tokens is an unbiased estimate of that of intermediate diffusion states, and (ii) the probability of the full trajectory can be effectively estimated with a single forward pass of a re-masked final state. By integrating these two trajectory reduction strategies into a policy optimization objective, we propose Trajectory Reduction Policy Optimization (dTRPO). We evaluate dTRPO on 7B dLLMs across instruction-following and reasoning benchmarks. Results show that it substantially improves the core performance of state-of-the-art dLLMs, achieving gains of up to 9.6% on STEM tasks, up to 4.3% on coding tasks, and up to 3.0% on instruction-following tasks. Moreover, dTRPO exhibits strong training efficiency due to its offline, single-forward nature, and achieves improved generation efficiency through high-quality outputs.
MobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale
Mar 16, 2026Real-time AI experiences call for on-device large language models (OD-LLMs) optimized for efficient deployment on resource-constrained hardware. The most useful OD-LLMs produce near-real-time responses and exhibit broad hardware compatibility, maximizing user reach. We present a methodology for designing such models using hardware-in-the-loop architecture search under mobile latency constraints. This system is amenable to industry-scale deployment: it generates models deployable without custom kernels and compatible with standard mobile runtimes like Executorch. Our methodology avoids specialized attention mechanisms and instead uses attention skipping for long-context acceleration. Our approach jointly optimizes model architecture (layers, dimensions) and attention pattern. To efficiently evaluate candidates, we treat each as a pruned version of a pretrained backbone with inherited weights, thereby achieving high accuracy with minimal continued pretraining. We leverage the low cost of latency evaluation in a staged process: learning an accurate latency model first, then searching for the Pareto-frontier across latency and quality. This yields MobileLLM-Flash, a family of foundation models (350M, 650M, 1.4B) for efficient on-device use with strong capabilities, supporting up to 8k context length. MobileLLM-Flash delivers up to 1.8x and 1.6x faster prefill and decode on mobile CPUs with comparable or superior quality. Our analysis of Pareto-frontier design choices offers actionable principles for OD-LLM design.
The Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
SHARP: Accelerating Language Model Inference by SHaring Adjacent layers with Recovery Parameters
Feb 11, 2025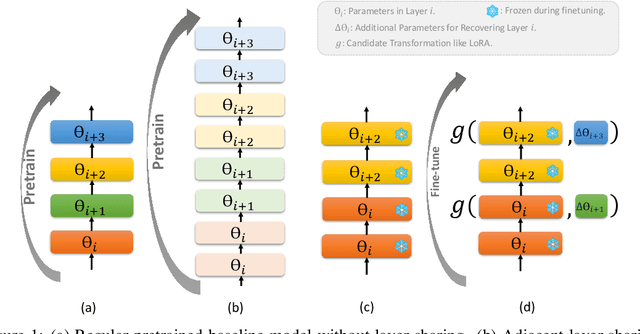

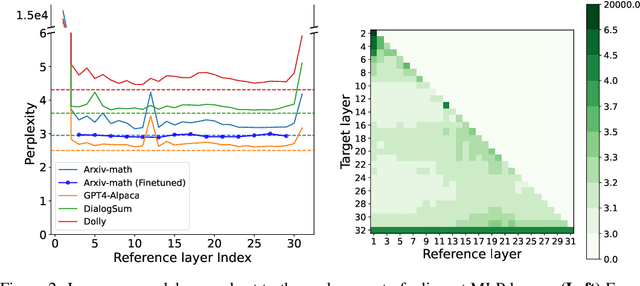
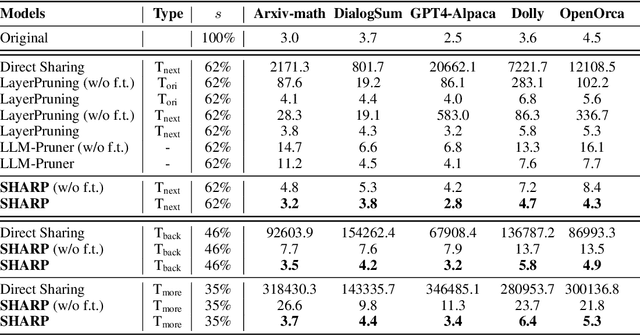
While Large language models (LLMs) have advanced natural language processing tasks, their growing computational and memory demands make deployment on resource-constrained devices like mobile phones increasingly challenging. In this paper, we propose SHARP (SHaring Adjacent Layers with Recovery Parameters), a novel approach to accelerate LLM inference by sharing parameters across adjacent layers, thus reducing memory load overhead, while introducing low-rank recovery parameters to maintain performance. Inspired by observations that consecutive layers have similar outputs, SHARP employs a two-stage recovery process: Single Layer Warmup (SLW), and Supervised Fine-Tuning (SFT). The SLW stage aligns the outputs of the shared layers using L_2 loss, providing a good initialization for the following SFT stage to further restore the model performance. Extensive experiments demonstrate that SHARP can recover the model's perplexity on various in-distribution tasks using no more than 50k fine-tuning data while reducing the number of stored MLP parameters by 38% to 65%. We also conduct several ablation studies of SHARP and show that replacing layers towards the later parts of the model yields better performance retention, and that different recovery parameterizations perform similarly when parameter counts are matched. Furthermore, SHARP saves 42.8% in model storage and reduces the total inference time by 42.2% compared to the original Llama2-7b model on mobile devices. Our results highlight SHARP as an efficient solution for reducing inference costs in deploying LLMs without the need for pretraining-scale resources.
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization
Feb 04, 2025The optimal bit-width for achieving the best trade-off between quantized model size and accuracy has been a subject of ongoing debate. While some advocate for 4-bit quantization, others propose that 1.58-bit offers superior results. However, the lack of a cohesive framework for different bits has left such conclusions relatively tenuous. We present ParetoQ, the first unified framework that facilitates rigorous comparisons across 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization settings. Our findings reveal a notable learning transition between 2 and 3 bits: For 3-bits and above, the fine-tuned models stay close to their original pre-trained distributions, whereas for learning 2-bit networks or below, the representations change drastically. By optimizing training schemes and refining quantization functions, ParetoQ surpasses all previous methods tailored to specific bit widths. Remarkably, our ParetoQ ternary 600M-parameter model even outperforms the previous SoTA ternary 3B-parameter model in accuracy, using only one-fifth of the parameters. Extensive experimentation shows that ternary, 2-bit, and 3-bit quantization maintains comparable performance in the size-accuracy trade-off and generally exceeds 4-bit and binary quantization. Considering hardware constraints, 2-bit quantization offers promising potential for memory reduction and speedup.
MAGE: A Multi-Agent Engine for Automated RTL Code Generation
Dec 10, 2024



The automatic generation of RTL code (e.g., Verilog) through natural language instructions has emerged as a promising direction with the advancement of large language models (LLMs). However, producing RTL code that is both syntactically and functionally correct remains a significant challenge. Existing single-LLM-agent approaches face substantial limitations because they must navigate between various programming languages and handle intricate generation, verification, and modification tasks. To address these challenges, this paper introduces MAGE, the first open-source multi-agent AI system designed for robust and accurate Verilog RTL code generation. We propose a novel high-temperature RTL candidate sampling and debugging system that effectively explores the space of code candidates and significantly improves the quality of the candidates. Furthermore, we design a novel Verilog-state checkpoint checking mechanism that enables early detection of functional errors and delivers precise feedback for targeted fixes, significantly enhancing the functional correctness of the generated RTL code. MAGE achieves a 95.7% rate of syntactic and functional correctness code generation on VerilogEval-Human 2 benchmark, surpassing the state-of-the-art Claude-3.5-sonnet by 23.3 %, demonstrating a robust and reliable approach for AI-driven RTL design workflows.
GeoT: Tensor Centric Library for Graph Neural Network via Efficient Segment Reduction on GPU
Apr 08, 2024In recent years, Graph Neural Networks (GNNs) have ignited a surge of innovation, significantly enhancing the processing of geometric data structures such as graphs, point clouds, and meshes. As the domain continues to evolve, a series of frameworks and libraries are being developed to push GNN efficiency to new heights. While graph-centric libraries have achieved success in the past, the advent of efficient tensor compilers has highlighted the urgent need for tensor-centric libraries. Yet, efficient tensor-centric frameworks for GNNs remain scarce due to unique challenges and limitations encountered when implementing segment reduction in GNN contexts. We introduce GeoT, a cutting-edge tensor-centric library designed specifically for GNNs via efficient segment reduction. GeoT debuts innovative parallel algorithms that not only introduce new design principles but also expand the available design space. Importantly, GeoT is engineered for straightforward fusion within a computation graph, ensuring compatibility with contemporary tensor-centric machine learning frameworks and compilers. Setting a new performance benchmark, GeoT marks a considerable advancement by showcasing an average operator speedup of 1.80x and an end-to-end speedup of 1.68x.
Multi-modal Learning for WebAssembly Reverse Engineering
Apr 04, 2024



The increasing adoption of WebAssembly (Wasm) for performance-critical and security-sensitive tasks drives the demand for WebAssembly program comprehension and reverse engineering. Recent studies have introduced machine learning (ML)-based WebAssembly reverse engineering tools. Yet, the generalization of task-specific ML solutions remains challenging, because their effectiveness hinges on the availability of an ample supply of high-quality task-specific labeled data. Moreover, previous works overlook the high-level semantics present in source code and its documentation. Acknowledging the abundance of available source code with documentation, which can be compiled into WebAssembly, we propose to learn representations of them concurrently and harness their mutual relationships for effective WebAssembly reverse engineering. In this paper, we present WasmRev, the first multi-modal pre-trained language model for WebAssembly reverse engineering. WasmRev is pre-trained using self-supervised learning on a large-scale multi-modal corpus encompassing source code, code documentation and the compiled WebAssembly, without requiring labeled data. WasmRev incorporates three tailored multi-modal pre-training tasks to capture various characteristics of WebAssembly and cross-modal relationships. WasmRev is only trained once to produce general-purpose representations that can broadly support WebAssembly reverse engineering tasks through few-shot fine-tuning with much less labeled data, improving data efficiency. We fine-tune WasmRev onto three important reverse engineering tasks: type recovery, function purpose identification and WebAssembly summarization. Our results show that WasmRev pre-trained on the corpus of multi-modal samples establishes a robust foundation for these tasks, achieving high task accuracy and outperforming the state-of-the-art ML methods for WebAssembly reverse engineering.
Learning to Maximize Mutual Information for Chain-of-Thought Distillation
Mar 05, 2024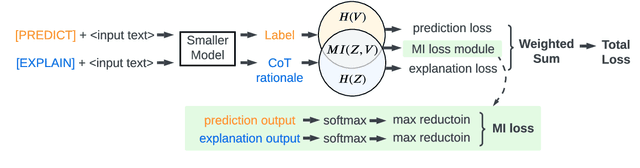
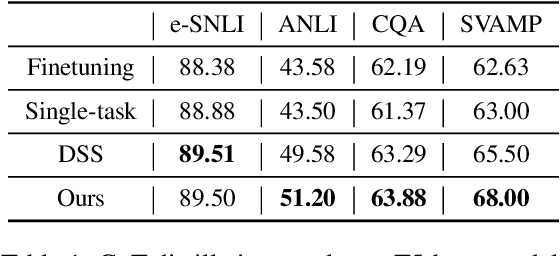
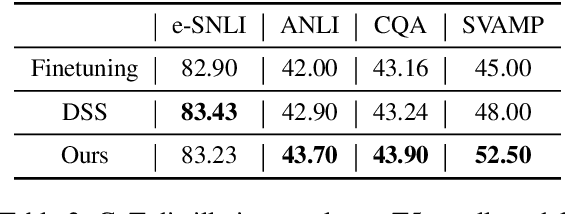
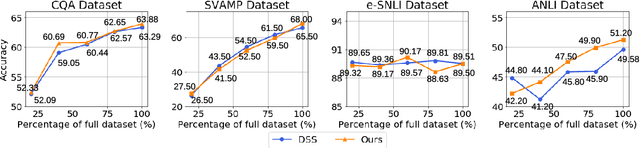
Knowledge distillation, the technique of transferring knowledge from large, complex models to smaller ones, marks a pivotal step towards efficient AI deployment. Distilling Step-by-Step (DSS), a novel method utilizing chain-of-thought (CoT) distillation, has demonstrated promise by imbuing smaller models with the superior reasoning capabilities of their larger counterparts. In DSS, the distilled model acquires the ability to generate rationales and predict labels concurrently through a multi-task learning framework. However, DSS overlooks the intrinsic relationship between the two training tasks, leading to ineffective integration of CoT knowledge with the task of label prediction. To this end, we investigate the mutual relationship of the two tasks from Information Bottleneck perspective and formulate it as maximizing the mutual information of the representation features of the two tasks. We propose a variational approach to solve this optimization problem using a learning-based method. Our experimental results across four datasets demonstrate that our method outperforms the state-of-the-art DSS. Our findings offer insightful guidance for future research on language model distillation as well as applications involving CoT. Code and models will be released soon.