 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoClaw: Evaluating AI Agents on Continuous Software Evolution
Mar 13, 2026With AI agents increasingly deployed as long-running systems, it becomes essential to autonomously construct and continuously evolve customized software to enable interaction within dynamic environments. Yet, existing benchmarks evaluate agents on isolated, one-off coding tasks, neglecting the temporal dependencies and technical debt inherent in real-world software evolution. To bridge this gap, we introduce DeepCommit, an agentic pipeline that reconstructs verifiable Milestone DAGs from noisy commit logs, where milestones are defined as semantically cohesive development goals. These executable sequences enable EvoClaw, a novel benchmark that requires agents to sustain system integrity and limit error accumulation, dimensions of long-term software evolution largely missing from current benchmarks. Our evaluation of 12 frontier models across 4 agent frameworks reveals a critical vulnerability: overall performance scores drop significantly from $>$80% on isolated tasks to at most 38% in continuous settings, exposing agents' profound struggle with long-term maintenance and error propagation.
Multi-Agent Memory from a Computer Architecture Perspective: Visions and Challenges Ahead
Mar 09, 2026As LLM agents evolve into collaborative multi-agent systems, their memory requirements grow rapidly in complexity. This position paper frames multi-agent memory as a computer architecture problem. We distinguish shared and distributed memory paradigms, propose a three-layer memory hierarchy (I/O, cache, and memory), and identify two critical protocol gaps: cache sharing across agents and structured memory access control. We argue that the most pressing open challenge is multi-agent memory consistency. Our architectural framing provides a foundation for building reliable, scalable multi-agent systems.
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications
Feb 26, 2026Large Language Models (LLMs) are deployed as autonomous agents in increasingly complex applications, where enabling long-horizon memory is critical for achieving strong performance. However, a significant gap exists between practical applications and current evaluation standards for agent memory: existing benchmarks primarily focus on dialogue-centric, human-agent interactions. In reality, agent memory consists of a continuous stream of agent-environment interactions that are primarily composed of machine-generated representations. To bridge this gap, we introduce AMA-Bench (Agent Memory with Any length), which evaluates long-horizon memory for LLMs in real agentic applications. It features two key components: (1) a set of real-world agentic trajectories across representative agentic applications, paired with expert-curated QA, and (2) a set of synthetic agentic trajectories that scale to arbitrary horizons, paired with rule-based QA. Our comprehensive study shows that existing memory systems underperform on AMA-Bench primarily because they lack causality and objective information and are constrained by the lossy nature of similarity-based retrieval employed by many memory systems. To address these limitations, we propose AMA-Agent, an effective memory system featuring a causality graph and tool-augmented retrieval. Our results demonstrate that AMA-Agent achieves 57.22% average accuracy on AMA-Bench, surpassing the strongest memory system baselines by 11.16%.
LLM4Cov: Execution-Aware Agentic Learning for High-coverage Testbench Generation
Feb 18, 2026Execution-aware LLM agents offer a promising paradigm for learning from tool feedback, but such feedback is often expensive and slow to obtain, making online reinforcement learning (RL) impractical. High-coverage hardware verification exemplifies this challenge due to its reliance on industrial simulators and non-differentiable execution signals. We propose LLM4Cov, an offline agent-learning framework that models verification as memoryless state transitions guided by deterministic evaluators. Building on this formulation, we introduce execution-validated data curation, policy-aware agentic data synthesis, and worst-state-prioritized sampling to enable scalable learning under execution constraints. We further curate a reality-aligned benchmark adapted from an existing verification suite through a revised evaluation protocol. Using the proposed pipeline, a compact 4B-parameter model achieves 69.2% coverage pass rate under agentic evaluation, outperforming its teacher by 5.3% and demonstrating competitive performance against models an order of magnitude larger.
Double-P: Hierarchical Top-P Sparse Attention for Long-Context LLMs
Feb 05, 2026As long-context inference becomes central to large language models (LLMs), attention over growing key-value caches emerges as a dominant decoding bottleneck, motivating sparse attention for scalable inference. Fixed-budget top-k sparse attention cannot adapt to heterogeneous attention distributions across heads and layers, whereas top-p sparse attention directly preserves attention mass and provides stronger accuracy guarantees. Existing top-p methods, however, fail to jointly optimize top-p accuracy, selection overhead, and sparse attention cost, which limits their overall efficiency. We present Double-P, a hierarchical sparse attention framework that optimizes all three stages. Double-P first performs coarse-grained top-p estimation at the cluster level using size-weighted centroids, then adaptively refines computation through a second top-p stage that allocates token-level attention only when needed. Across long-context benchmarks, Double-P consistently achieves near-zero accuracy drop, reducing attention computation overhead by up to 1.8x and delivers up to 1.3x end-to-end decoding speedup over state-of-the-art fixed-budget sparse attention methods.
PRO-V: An Efficient Program Generation Multi-Agent System for Automatic RTL Verification
Jun 13, 2025LLM-assisted hardware verification is gaining substantial attention due to its potential to significantly reduce the cost and effort of crafting effective testbenches. It also serves as a critical enabler for LLM-aided end-to-end hardware language design. However, existing current LLMs often struggle with Register Transfer Level (RTL) code generation, resulting in testbenches that exhibit functional errors in Hardware Description Languages (HDL) logic. Motivated by the strong performance of LLMs in Python code generation under inference-time sampling strategies, and their promising capabilities as judge agents, we propose PRO-V a fully program generation multi-agent system for robust RTL verification. Pro-V incorporates an efficient best-of-n iterative sampling strategy to enhance the correctness of generated testbenches. Moreover, it introduces an LLM-as-a-judge aid validation framework featuring an automated prompt generation pipeline. By converting rule-based static analysis from the compiler into natural language through in-context learning, this pipeline enables LLMs to assist the compiler in determining whether verification failures stem from errors in the RTL design or the testbench. PRO-V attains a verification accuracy of 87.17% on golden RTL implementations and 76.28% on RTL mutants. Our code is open-sourced at https://github.com/stable-lab/Pro-V.
MAGE: A Multi-Agent Engine for Automated RTL Code Generation
Dec 10, 2024



The automatic generation of RTL code (e.g., Verilog) through natural language instructions has emerged as a promising direction with the advancement of large language models (LLMs). However, producing RTL code that is both syntactically and functionally correct remains a significant challenge. Existing single-LLM-agent approaches face substantial limitations because they must navigate between various programming languages and handle intricate generation, verification, and modification tasks. To address these challenges, this paper introduces MAGE, the first open-source multi-agent AI system designed for robust and accurate Verilog RTL code generation. We propose a novel high-temperature RTL candidate sampling and debugging system that effectively explores the space of code candidates and significantly improves the quality of the candidates. Furthermore, we design a novel Verilog-state checkpoint checking mechanism that enables early detection of functional errors and delivers precise feedback for targeted fixes, significantly enhancing the functional correctness of the generated RTL code. MAGE achieves a 95.7% rate of syntactic and functional correctness code generation on VerilogEval-Human 2 benchmark, surpassing the state-of-the-art Claude-3.5-sonnet by 23.3 %, demonstrating a robust and reliable approach for AI-driven RTL design workflows.
GeoT: Tensor Centric Library for Graph Neural Network via Efficient Segment Reduction on GPU
Apr 08, 2024In recent years, Graph Neural Networks (GNNs) have ignited a surge of innovation, significantly enhancing the processing of geometric data structures such as graphs, point clouds, and meshes. As the domain continues to evolve, a series of frameworks and libraries are being developed to push GNN efficiency to new heights. While graph-centric libraries have achieved success in the past, the advent of efficient tensor compilers has highlighted the urgent need for tensor-centric libraries. Yet, efficient tensor-centric frameworks for GNNs remain scarce due to unique challenges and limitations encountered when implementing segment reduction in GNN contexts. We introduce GeoT, a cutting-edge tensor-centric library designed specifically for GNNs via efficient segment reduction. GeoT debuts innovative parallel algorithms that not only introduce new design principles but also expand the available design space. Importantly, GeoT is engineered for straightforward fusion within a computation graph, ensuring compatibility with contemporary tensor-centric machine learning frameworks and compilers. Setting a new performance benchmark, GeoT marks a considerable advancement by showcasing an average operator speedup of 1.80x and an end-to-end speedup of 1.68x.
Benchmarking GNN-Based Recommender Systems on Intel Optane Persistent Memory
Jul 25, 2022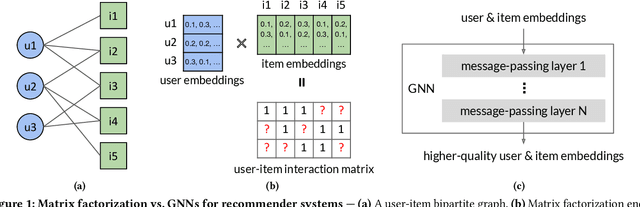
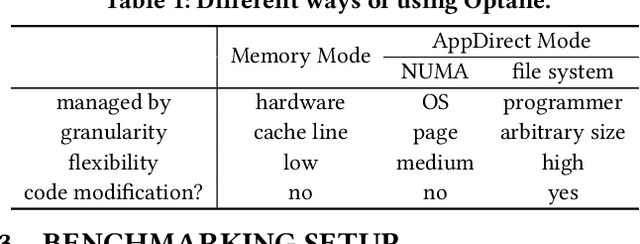
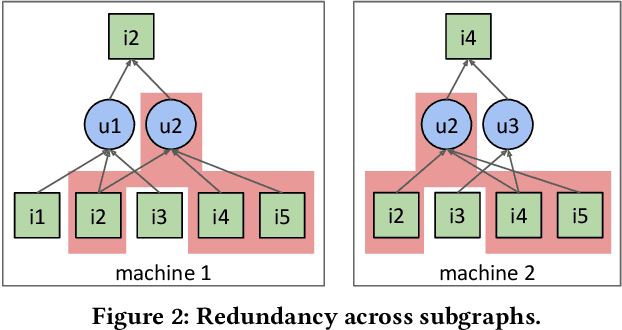
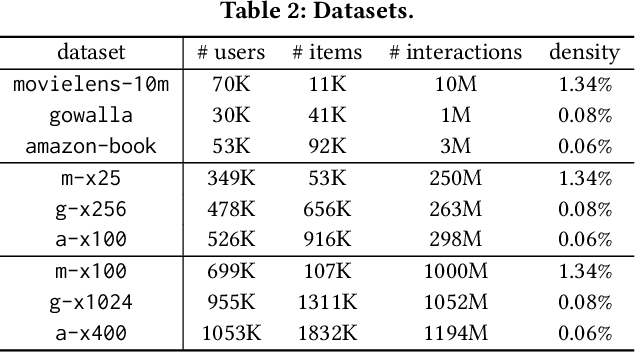
Graph neural networks (GNNs), which have emerged as an effective method for handling machine learning tasks on graphs, bring a new approach to building recommender systems, where the task of recommendation can be formulated as the link prediction problem on user-item bipartite graphs. Training GNN-based recommender systems (GNNRecSys) on large graphs incurs a large memory footprint, easily exceeding the DRAM capacity on a typical server. Existing solutions resort to distributed subgraph training, which is inefficient due to the high cost of dynamically constructing subgraphs and significant redundancy across subgraphs. The emerging Intel Optane persistent memory allows a single machine to have up to 6 TB of memory at an affordable cost, thus making single-machine GNNRecSys training feasible, which eliminates the inefficiencies in distributed training. One major concern of using Optane for GNNRecSys is Optane's relatively low bandwidth compared with DRAMs. This limitation can be particularly detrimental to achieving high performance for GNNRecSys workloads since their dominant compute kernels are sparse and memory access intensive. To understand whether Optane is a good fit for GNNRecSys training, we perform an in-depth characterization of GNNRecSys workloads and a comprehensive benchmarking study. Our benchmarking results show that when properly configured, Optane-based single-machine GNNRecSys training outperforms distributed training by a large margin, especially when handling deep GNN models. We analyze where the speedup comes from, provide guidance on how to configure Optane for GNNRecSys workloads, and discuss opportunities for further optimizations.
FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
Mar 04, 2022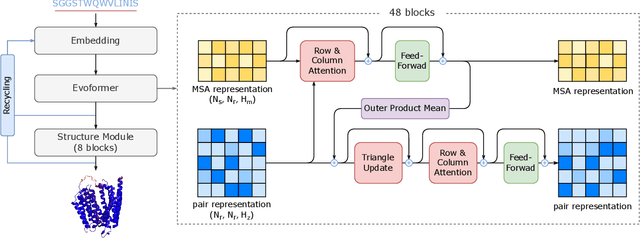
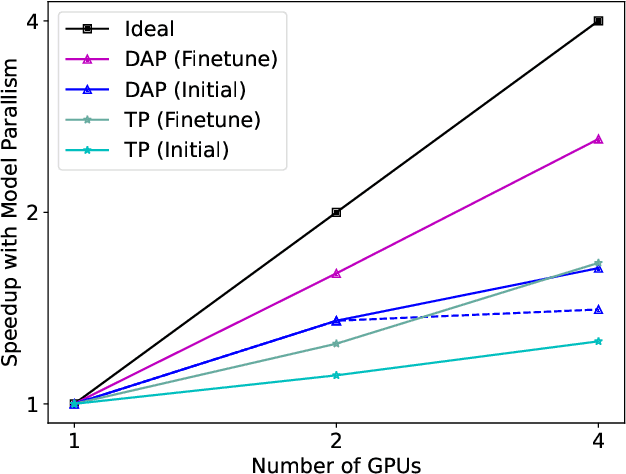
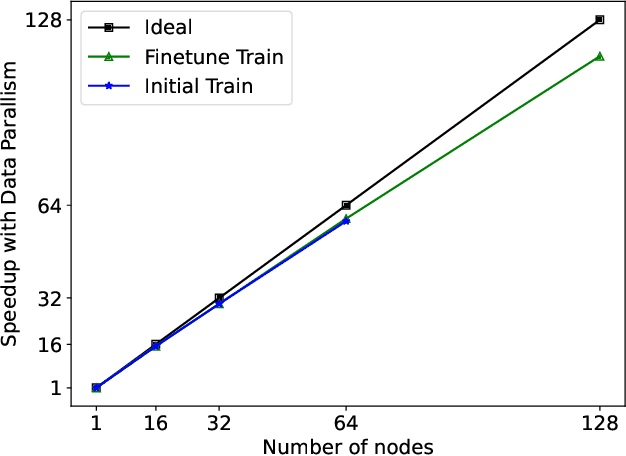
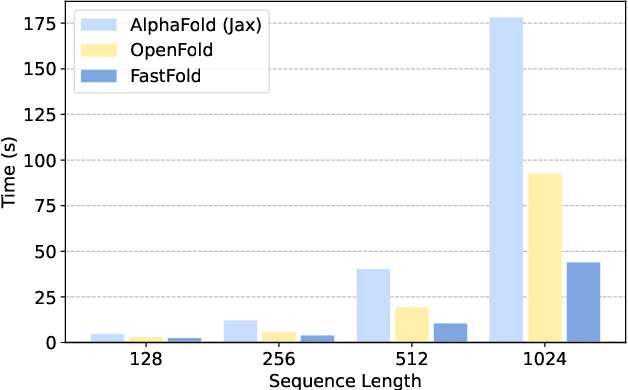
Protein structure prediction is an important method for understanding gene translation and protein function in the domain of structural biology. AlphaFold introduced the Transformer model to the field of protein structure prediction with atomic accuracy. However, training and inference of the AlphaFold model are time-consuming and expensive because of the special performance characteristics and huge memory consumption. In this paper, we propose FastFold, a highly efficient implementation of the protein structure prediction model for training and inference. FastFold includes a series of GPU optimizations based on a thorough analysis of AlphaFold's performance. Meanwhile, with Dynamic Axial Parallelism and Duality Async Operation, FastFold achieves high model parallelism scaling efficiency, surpassing existing popular model parallelism techniques. Experimental results show that FastFold reduces overall training time from 11 days to 67 hours and achieves 7.5-9.5X speedup for long-sequence inference. Furthermore, We scaled FastFold to 512 GPUs and achieved an aggregate of 6.02 PetaFLOPs with 90.1% parallel efficiency. The implementation can be found at https://github.com/hpcaitech/FastFold