 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRPO with State Mutations: Improving LLM-Based Hardware Test Plan Generation
Jan 12, 2026RTL design often relies heavily on ad-hoc testbench creation early in the design cycle. While large language models (LLMs) show promise for RTL code generation, their ability to reason about hardware specifications and generate targeted test plans remains largely unexplored. We present the first systematic study of LLM reasoning capabilities for RTL verification stimuli generation, establishing a two-stage framework that decomposes test plan generation from testbench execution. Our benchmark reveals that state-of-the-art models, including DeepSeek-R1 and Claude-4.0-Sonnet, achieve only 15.7-21.7% success rates on generating stimuli that pass golden RTL designs. To improve LLM generated stimuli, we develop a comprehensive training methodology combining supervised fine-tuning with a novel reinforcement learning approach, GRPO with State Mutation (GRPO-SMu), which enhances exploration by varying input mutations. Our approach leverages a tree-based branching mutation strategy to construct training data comprising equivalent and mutated trees, moving beyond linear mutation approaches to provide rich learning signals. Training on this curated dataset, our 7B parameter model achieves a 33.3% golden test pass rate and a 13.9% mutation detection rate, representing a 17.6% absolute improvement over baseline and outperforming much larger general-purpose models. These results demonstrate that specialized training methodologies can significantly enhance LLM reasoning capabilities for hardware verification tasks, establishing a foundation for automated sub-unit testing in semiconductor design workflows.
Autonomous Code Evolution Meets NP-Completeness
Sep 09, 2025Large language models (LLMs) have recently shown strong coding abilities, enabling not only static code generation but also iterative code self-evolving through agentic frameworks. Recently, AlphaEvolve \cite{novikov2025alphaevolve} demonstrated that LLM-based coding agents can autonomously improve algorithms and surpass human experts, with scopes limited to isolated kernels spanning hundreds of lines of code. Inspired by AlphaEvolve, we present SATLUTION, the first framework to extend LLM-based code evolution to the full repository scale, encompassing hundreds of files and tens of thousands of lines of C/C++ code. Targeting Boolean Satisfiability (SAT), the canonical NP-complete problem and a cornerstone of both theory and applications. SATLUTION orchestrates LLM agents to directly evolve solver repositories under strict correctness guarantees and distributed runtime feedback, while simultaneously self-evolving its own evolution policies and rules. Starting from SAT Competition 2024 codebases and benchmark, SATLUTION evolved solvers that decisively outperformed the human-designed winners of the SAT Competition 2025, and also surpassed both 2024 and 2025 champions on the 2024 benchmarks.
PRO-V: An Efficient Program Generation Multi-Agent System for Automatic RTL Verification
Jun 13, 2025LLM-assisted hardware verification is gaining substantial attention due to its potential to significantly reduce the cost and effort of crafting effective testbenches. It also serves as a critical enabler for LLM-aided end-to-end hardware language design. However, existing current LLMs often struggle with Register Transfer Level (RTL) code generation, resulting in testbenches that exhibit functional errors in Hardware Description Languages (HDL) logic. Motivated by the strong performance of LLMs in Python code generation under inference-time sampling strategies, and their promising capabilities as judge agents, we propose PRO-V a fully program generation multi-agent system for robust RTL verification. Pro-V incorporates an efficient best-of-n iterative sampling strategy to enhance the correctness of generated testbenches. Moreover, it introduces an LLM-as-a-judge aid validation framework featuring an automated prompt generation pipeline. By converting rule-based static analysis from the compiler into natural language through in-context learning, this pipeline enables LLMs to assist the compiler in determining whether verification failures stem from errors in the RTL design or the testbench. PRO-V attains a verification accuracy of 87.17% on golden RTL implementations and 76.28% on RTL mutants. Our code is open-sourced at https://github.com/stable-lab/Pro-V.
HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization
Jun 09, 2025While Large Language Models (LLMs) have demonstrated significant advancements in reasoning and agent-based problem-solving, current evaluation methodologies fail to adequately assess their capabilities: existing benchmarks either rely on closed-ended questions prone to saturation and memorization, or subjective comparisons that lack consistency and rigor. In this work, we introduce HeuriGym, an agentic framework designed for evaluating heuristic algorithms generated by LLMs for combinatorial optimization problems, characterized by clearly defined objectives and expansive solution spaces. HeuriGym empowers LLMs to propose heuristics, receive evaluative feedback via code execution, and iteratively refine their solutions. We evaluate nine state-of-the-art models on nine problems across domains such as computer systems, logistics, and biology, exposing persistent limitations in tool use, planning, and adaptive reasoning. To quantify performance, we propose the Quality-Yield Index (QYI), a metric that captures both solution pass rate and quality. Even top models like GPT-o4-mini-high and Gemini-2.5-Pro attain QYI scores of only 0.6, well below the expert baseline of 1. Our open-source benchmark aims to guide the development of LLMs toward more effective and realistic problem-solving in scientific and engineering domains.
ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation
Jun 05, 2025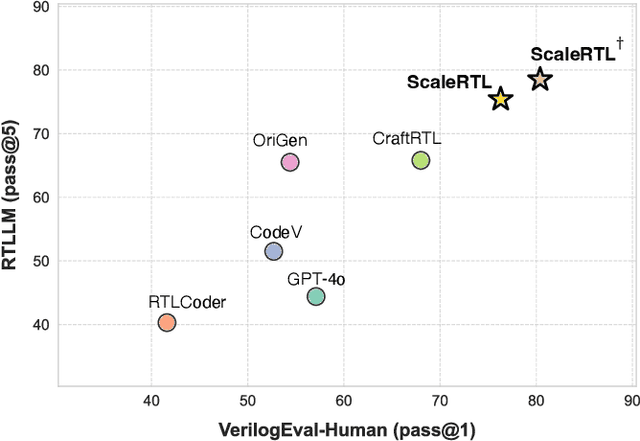
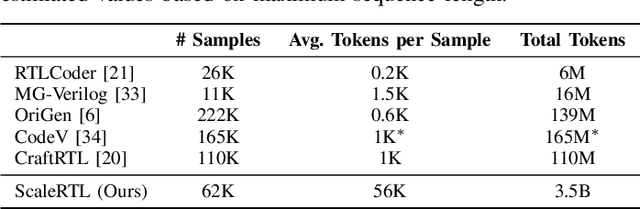
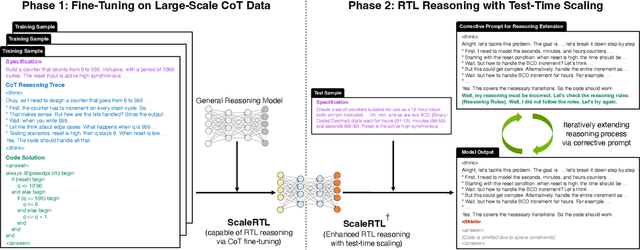
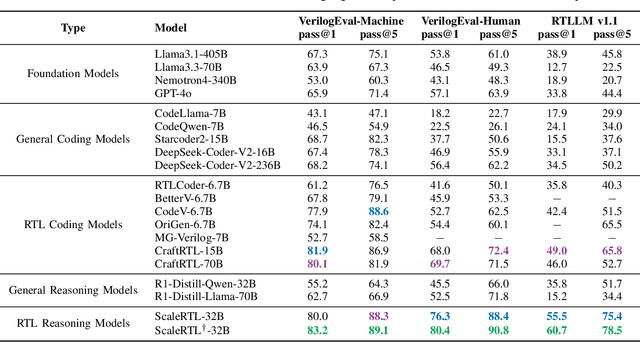
Recent advances in large language models (LLMs) have enabled near-human performance on software coding benchmarks, but their effectiveness in RTL code generation remains limited due to the scarcity of high-quality training data. While prior efforts have fine-tuned LLMs for RTL tasks, they do not fundamentally overcome the data bottleneck and lack support for test-time scaling due to their non-reasoning nature. In this work, we introduce ScaleRTL, the first reasoning LLM for RTL coding that scales up both high-quality reasoning data and test-time compute. Specifically, we curate a diverse set of long chain-of-thought reasoning traces averaging 56K tokens each, resulting in a dataset of 3.5B tokens that captures rich RTL knowledge. Fine-tuning a general-purpose reasoning model on this corpus yields ScaleRTL that is capable of deep RTL reasoning. Subsequently, we further enhance the performance of ScaleRTL through a novel test-time scaling strategy that extends the reasoning process via iteratively reflecting on and self-correcting previous reasoning steps. Experimental results show that ScaleRTL achieves state-of-the-art performance on VerilogEval and RTLLM, outperforming 18 competitive baselines by up to 18.4% on VerilogEval and 12.7% on RTLLM.
JARVIS: A Multi-Agent Code Assistant for High-Quality EDA Script Generation
May 20, 2025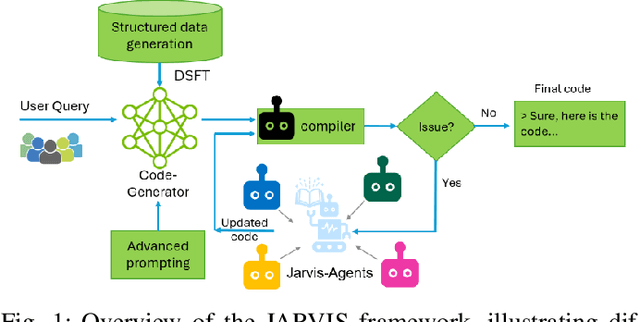
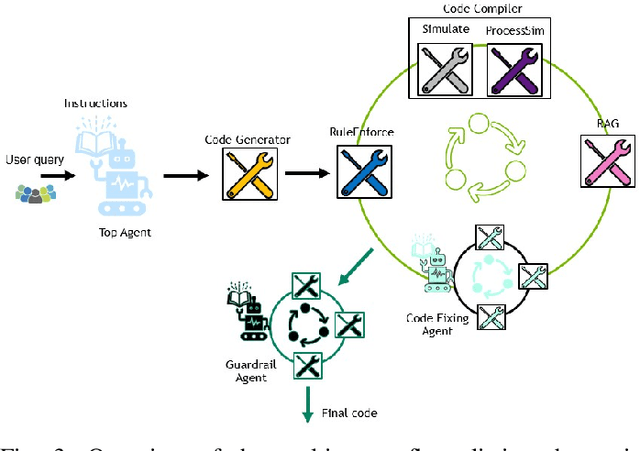
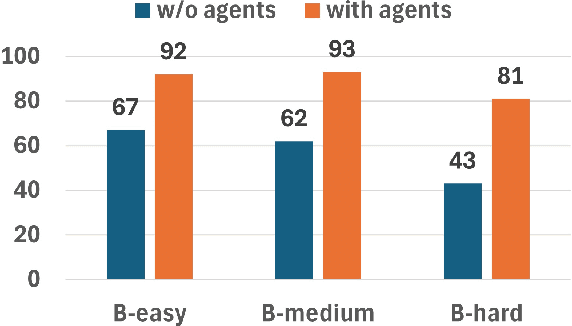
This paper presents JARVIS, a novel multi-agent framework that leverages Large Language Models (LLMs) and domain expertise to generate high-quality scripts for specialized Electronic Design Automation (EDA) tasks. By combining a domain-specific LLM trained with synthetically generated data, a custom compiler for structural verification, rule enforcement, code fixing capabilities, and advanced retrieval mechanisms, our approach achieves significant improvements over state-of-the-art domain-specific models. Our framework addresses the challenges of data scarcity and hallucination errors in LLMs, demonstrating the potential of LLMs in specialized engineering domains. We evaluate our framework on multiple benchmarks and show that it outperforms existing models in terms of accuracy and reliability. Our work sets a new precedent for the application of LLMs in EDA and paves the way for future innovations in this field.
Deep Physics Prior for First Order Inverse Optimization
Apr 28, 2025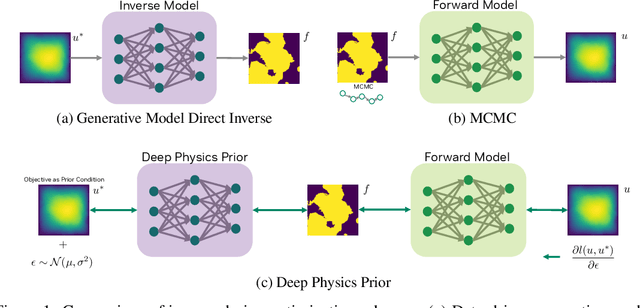
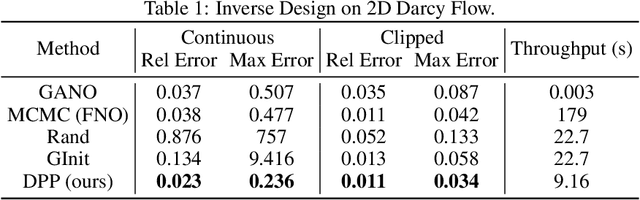

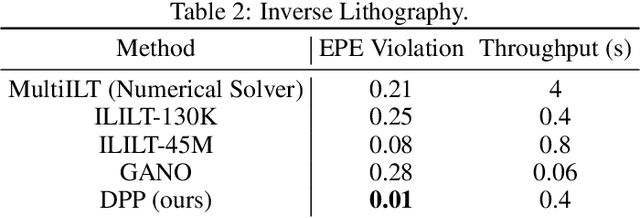
Inverse design optimization aims to infer system parameters from observed solutions, posing critical challenges across domains such as semiconductor manufacturing, structural engineering, materials science, and fluid dynamics. The lack of explicit mathematical representations in many systems complicates this process and makes the first order optimization impossible. Mainstream approaches, including generative AI and Bayesian optimization, address these challenges but have limitations. Generative AI is computationally expensive, while Bayesian optimization, relying on surrogate models, suffers from scalability, sensitivity to priors, and noise issues, often leading to suboptimal solutions. This paper introduces Deep Physics Prior (DPP), a novel method enabling first-order gradient-based inverse optimization with surrogate machine learning models. By leveraging pretrained auxiliary Neural Operators, DPP enforces prior distribution constraints to ensure robust and meaningful solutions. This approach is particularly effective when prior data and observation distributions are unknown.
Timing Analysis Agent: Autonomous Multi-Corner Multi-Mode (MCMM) Timing Debugging with Timing Debug Relation Graph
Apr 15, 2025Timing analysis is an essential and demanding verification method for Very Large Scale Integrated (VLSI) circuit design and optimization. In addition, it also serves as the cornerstone of the final sign-off, determining whether the chip is ready to be sent to the semiconductor foundry for fabrication. Recently, as the technology advance relentlessly, smaller metal pitches and the increasing number of devices have led to greater challenges and longer turn-around-time for experienced human designers to debug timing issues from the Multi-Corner Multi-Mode (MCMM) timing reports. As a result, an efficient and intelligent methodology is highly necessary and essential for debugging timing issues and reduce the turnaround times. Recently, Large Language Models (LLMs) have shown great promise across various tasks in language understanding and interactive decision-making, incorporating reasoning and actions. In this work, we propose a timing analysis agent, that is empowered by multi-LLMs task solving, and incorporates a novel hierarchical planning and solving flow to automate the analysis of timing reports from commercial tool. In addition, we build a Timing Debug Relation Graph (TDRG) that connects the reports with the relationships of debug traces from experienced timing engineers. The timing analysis agent employs the novel Agentic Retrieval Augmented Generation (RAG) approach, that includes agent and coding to retrieve data accurately, on the developed TDRG. In our studies, the proposed timing analysis agent achieves an average 98% pass-rate on a single-report benchmark and a 90% pass-rate for multi-report benchmark from industrial designs, demonstrating its effectiveness and adaptability.
Learning Library Cell Representations in Vector Space
Mar 28, 2025We propose Lib2Vec, a novel self-supervised framework to efficiently learn meaningful vector representations of library cells, enabling ML models to capture essential cell semantics. The framework comprises three key components: (1) an automated method for generating regularity tests to quantitatively evaluate how well cell representations reflect inter-cell relationships; (2) a self-supervised learning scheme that systematically extracts training data from Liberty files, removing the need for costly labeling; and (3) an attention-based model architecture that accommodates various pin counts and enables the creation of property-specific cell and arc embeddings. Experimental results demonstrate that Lib2Vec effectively captures functional and electrical similarities. Moreover, linear algebraic operations on cell vectors reveal meaningful relationships, such as vector(BUF) - vector(INV) + vector(NAND) ~ vector(AND), showcasing the framework's nuanced representation capabilities. Lib2Vec also enhances downstream circuit learning applications, especially when labeled data is scarce.
AssertionForge: Enhancing Formal Verification Assertion Generation with Structured Representation of Specifications and RTL
Mar 24, 2025



Generating SystemVerilog Assertions (SVAs) from natural language specifications remains a major challenge in formal verification (FV) due to the inherent ambiguity and incompleteness of specifications. Existing LLM-based approaches, such as AssertLLM, focus on extracting information solely from specification documents, often failing to capture essential internal signal interactions and design details present in the RTL code, leading to incomplete or incorrect assertions. We propose a novel approach that constructs a Knowledge Graph (KG) from both specifications and RTL, using a hardware-specific schema with domain-specific entity and relation types. We create an initial KG from the specification and then systematically fuse it with information extracted from the RTL code, resulting in a unified, comprehensive KG. This combined representation enables a more thorough understanding of the design and allows for a multi-resolution context synthesis process which is designed to extract diverse verification contexts from the KG. Experiments on four designs demonstrate that our method significantly enhances SVA quality over prior methods. This structured representation not only improves FV but also paves the way for future research in tasks like code generation and design understanding.