 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Inverse Lithography with Generative Reinforcement Learning
Feb 22, 2026Inverse lithography (ILT) is critical for modern semiconductor manufacturing but suffers from highly non-convex objectives that often trap optimization in poor local minima. Generative AI has been explored to warm-start ILT, yet most approaches train deterministic image-to-image translators to mimic sub-optimal datasets, providing limited guidance for escaping non-convex traps during refinement. We reformulate mask synthesis as conditional sampling: a generator learns a distribution over masks conditioned on the design and proposes multiple candidates. The generator is first pretrained with WGAN plus a reconstruction loss, then fine-tuned using Group Relative Policy Optimization (GRPO) with an ILT-guided imitation loss. At inference, we sample a small batch of masks, run fast batched ILT refinement, evaluate lithography metrics (e.g., EPE, process window), and select the best candidate. On \texttt{LithoBench} dataset, the proposed hybrid framework reduces EPE violations under a 3\,nm tolerance and roughly doubles throughput versus a strong numerical ILT baseline, while improving final mask quality. We also present over 20\% EPE improvement on \texttt{ICCAD13} contest cases with 3$\times$ speedup over the SOTA numerical ILT solver. By learning to propose ILT-friendly initializations, our approach mitigates non-convexity and advances beyond what traditional solvers or GenAI can achieve.
OMG-Agent: Toward Robust Missing Modality Generation with Decoupled Coarse-to-Fine Agentic Workflows
Feb 04, 2026Data incompleteness severely impedes the reliability of multimodal systems. Existing reconstruction methods face distinct bottlenecks: conventional parametric/generative models are prone to hallucinations due to over-reliance on internal memory, while retrieval-augmented frameworks struggle with retrieval rigidity. Critically, these end-to-end architectures are fundamentally constrained by Semantic-Detail Entanglement -- a structural conflict between logical reasoning and signal synthesis that compromises fidelity. In this paper, we present \textbf{\underline{O}}mni-\textbf{\underline{M}}odality \textbf{\underline{G}}eneration Agent (\textbf{OMG-Agent}), a novel framework that shifts the paradigm from static mapping to a dynamic coarse-to-fine Agentic Workflow. By mimicking a \textit{deliberate-then-act} cognitive process, OMG-Agent explicitly decouples the task into three synergistic stages: (1) an MLLM-driven Semantic Planner that resolves input ambiguity via Progressive Contextual Reasoning, creating a deterministic structured semantic plan; (2) a non-parametric Evidence Retriever that grounds abstract semantics in external knowledge; and (3) a Retrieval-Injected Executor that utilizes retrieved evidence as flexible feature prompts to overcome rigidity and synthesize high-fidelity details. Extensive experiments on multiple benchmarks demonstrate that OMG-Agent consistently surpasses state-of-the-art methods, maintaining robustness under extreme missingness, e.g., a $2.6$-point gain on CMU-MOSI at $70$\% missing rates.
LaViT: Aligning Latent Visual Thoughts for Multi-modal Reasoning
Jan 15, 2026Current multimodal latent reasoning often relies on external supervision (e.g., auxiliary images), ignoring intrinsic visual attention dynamics. In this work, we identify a critical Perception Gap in distillation: student models frequently mimic a teacher's textual output while attending to fundamentally divergent visual regions, effectively relying on language priors rather than grounded perception. To bridge this, we propose LaViT, a framework that aligns latent visual thoughts rather than static embeddings. LaViT compels the student to autoregressively reconstruct the teacher's visual semantics and attention trajectories prior to text generation, employing a curriculum sensory gating mechanism to prevent shortcut learning. Extensive experiments show that LaViT significantly enhances visual grounding, achieving up to +16.9% gains on complex reasoning tasks and enabling a compact 3B model to outperform larger open-source variants and proprietary models like GPT-4o.
TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment
Jan 09, 2026Recent studies have demonstrated the efficacy of integrating Group Relative Policy Optimization (GRPO) into flow matching models, particularly for text-to-image and text-to-video generation. However, we find that directly applying these techniques to image-to-video (I2V) models often fails to yield consistent reward improvements. To address this limitation, we present TAGRPO, a robust post-training framework for I2V models inspired by contrastive learning. Our approach is grounded in the observation that rollout videos generated from identical initial noise provide superior guidance for optimization. Leveraging this insight, we propose a novel GRPO loss applied to intermediate latents, encouraging direct alignment with high-reward trajectories while maximizing distance from low-reward counterparts. Furthermore, we introduce a memory bank for rollout videos to enhance diversity and reduce computational overhead. Despite its simplicity, TAGRPO achieves significant improvements over DanceGRPO in I2V generation.
Rotate Your Character: Revisiting Video Diffusion Models for High-Quality 3D Character Generation
Jan 09, 2026Generating high-quality 3D characters from single images remains a significant challenge in digital content creation, particularly due to complex body poses and self-occlusion. In this paper, we present RCM (Rotate your Character Model), an advanced image-to-video diffusion framework tailored for high-quality novel view synthesis (NVS) and 3D character generation. Compared to existing diffusion-based approaches, RCM offers several key advantages: (1) transferring characters with any complex poses into a canonical pose, enabling consistent novel view synthesis across the entire viewing orbit, (2) high-resolution orbital video generation at 1024x1024 resolution, (3) controllable observation positions given different initial camera poses, and (4) multi-view conditioning supporting up to 4 input images, accommodating diverse user scenarios. Extensive experiments demonstrate that RCM outperforms state-of-the-art methods in both novel view synthesis and 3D generation quality.
An LLM-based Quantitative Framework for Evaluating High-Stealthy Backdoor Risks in OSS Supply Chains
Nov 17, 2025In modern software development workflows, the open-source software supply chain contributes significantly to efficient and convenient engineering practices. With increasing system complexity, using open-source software as third-party dependencies has become a common practice. However, the lack of maintenance for underlying dependencies and insufficient community auditing create challenges in ensuring source code security and the legitimacy of repository maintainers, especially under high-stealthy backdoor attacks exemplified by the XZ-Util incident. To address these problems, we propose a fine-grained project evaluation framework for backdoor risk assessment in open-source software. The framework models stealthy backdoor attacks from the viewpoint of the attacker and defines targeted metrics for each attack stage. In addition, to overcome the limitations of static analysis in assessing the reliability of repository maintenance activities such as irregular committer privilege escalation and limited participation in reviews, the framework uses large language models (LLMs) to conduct semantic evaluation of code repositories without relying on manually crafted patterns. The framework is evaluated on sixty six high-priority packages in the Debian ecosystem. The experimental results indicate that the current open-source software supply chain is exposed to various security risks.
EAROL: Environmental Augmented Perception-Aware Planning and Robust Odometry via Downward-Mounted Tilted LiDAR
Aug 20, 2025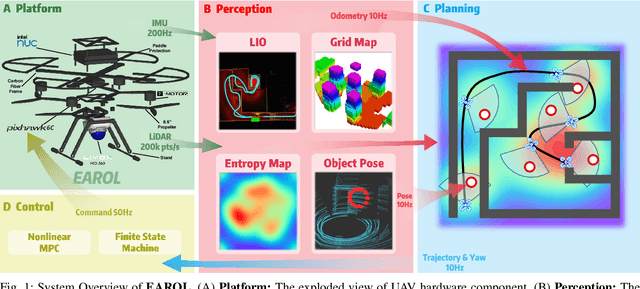
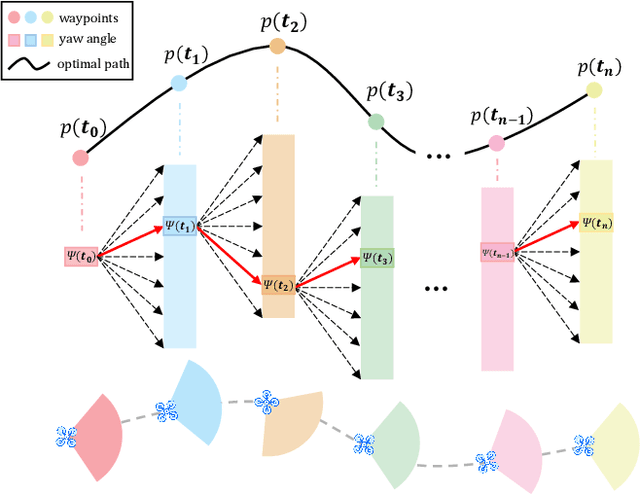

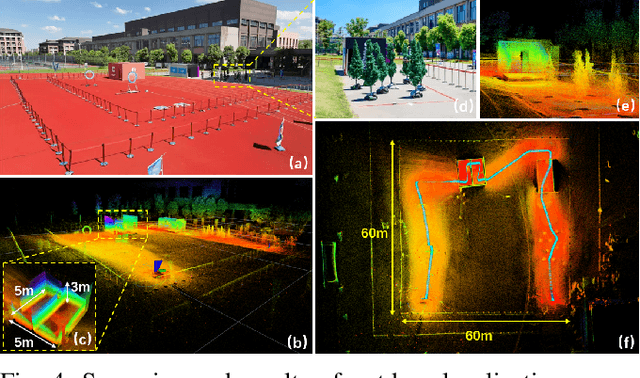
To address the challenges of localization drift and perception-planning coupling in unmanned aerial vehicles (UAVs) operating in open-top scenarios (e.g., collapsed buildings, roofless mazes), this paper proposes EAROL, a novel framework with a downward-mounted tilted LiDAR configuration (20{\deg} inclination), integrating a LiDAR-Inertial Odometry (LIO) system and a hierarchical trajectory-yaw optimization algorithm. The hardware innovation enables constraint enhancement via dense ground point cloud acquisition and forward environmental awareness for dynamic obstacle detection. A tightly-coupled LIO system, empowered by an Iterative Error-State Kalman Filter (IESKF) with dynamic motion compensation, achieves high level 6-DoF localization accuracy in feature-sparse environments. The planner, augmented by environment, balancing environmental exploration, target tracking precision, and energy efficiency. Physical experiments demonstrate 81% tracking error reduction, 22% improvement in perceptual coverage, and near-zero vertical drift across indoor maze and 60-meter-scale outdoor scenarios. This work proposes a hardware-algorithm co-design paradigm, offering a robust solution for UAV autonomy in post-disaster search and rescue missions. We will release our software and hardware as an open-source package for the community. Video: https://youtu.be/7av2ueLSiYw.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
TK-Mamba: Marrying KAN with Mamba for Text-Driven 3D Medical Image Segmentation
May 24, 2025



3D medical image segmentation is vital for clinical diagnosis and treatment but is challenged by high-dimensional data and complex spatial dependencies. Traditional single-modality networks, such as CNNs and Transformers, are often limited by computational inefficiency and constrained contextual modeling in 3D settings. We introduce a novel multimodal framework that leverages Mamba and Kolmogorov-Arnold Networks (KAN) as an efficient backbone for long-sequence modeling. Our approach features three key innovations: First, an EGSC (Enhanced Gated Spatial Convolution) module captures spatial information when unfolding 3D images into 1D sequences. Second, we extend Group-Rational KAN (GR-KAN), a Kolmogorov-Arnold Networks variant with rational basis functions, into 3D-Group-Rational KAN (3D-GR-KAN) for 3D medical imaging - its first application in this domain - enabling superior feature representation tailored to volumetric data. Third, a dual-branch text-driven strategy leverages CLIP's text embeddings: one branch swaps one-hot labels for semantic vectors to preserve inter-organ semantic relationships, while the other aligns images with detailed organ descriptions to enhance semantic alignment. Experiments on the Medical Segmentation Decathlon (MSD) and KiTS23 datasets show our method achieving state-of-the-art performance, surpassing existing approaches in accuracy and efficiency. This work highlights the power of combining advanced sequence modeling, extended network architectures, and vision-language synergy to push forward 3D medical image segmentation, delivering a scalable solution for clinical use. The source code is openly available at https://github.com/yhy-whu/TK-Mamba.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.