 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Domain Generalization for Multi-modal Object Recognition
Paper and Code
Aug 11, 2024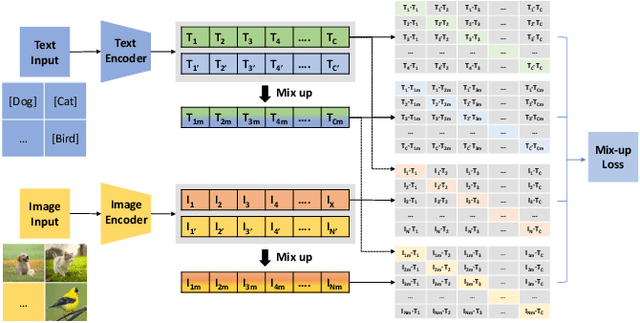
In multi-label classification, machine learning encounters the challenge of domain generalization when handling tasks with distributions differing from the training data. Existing approaches primarily focus on vision object recognition and neglect the integration of natural language. Recent advancements in vision-language pre-training leverage supervision from extensive visual-language pairs, enabling learning across diverse domains and enhancing recognition in multi-modal scenarios. However, these approaches face limitations in loss function utilization, generality across backbones, and class-aware visual fusion. This paper proposes solutions to these limitations by inferring the actual loss, broadening evaluations to larger vision-language backbones, and introducing Mixup-CLIPood, which incorporates a novel mix-up loss for enhanced class-aware visual fusion. Our method demonstrates superior performance in domain generalization across multiple datasets.