 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLProtector: An LLM-driven Vulnerability Detection System
Nov 14, 2024This paper presents LProtector, an automated vulnerability detection system for C/C++ codebases driven by the large language model (LLM) GPT-4o and Retrieval-Augmented Generation (RAG). As software complexity grows, traditional methods face challenges in detecting vulnerabilities effectively. LProtector leverages GPT-4o's powerful code comprehension and generation capabilities to perform binary classification and identify vulnerabilities within target codebases. We conducted experiments on the Big-Vul dataset, showing that LProtector outperforms two state-of-the-art baselines in terms of F1 score, demonstrating the potential of integrating LLMs with vulnerability detection.
Integration of Mamba and Transformer -- MAT for Long-Short Range Time Series Forecasting with Application to Weather Dynamics
Sep 13, 2024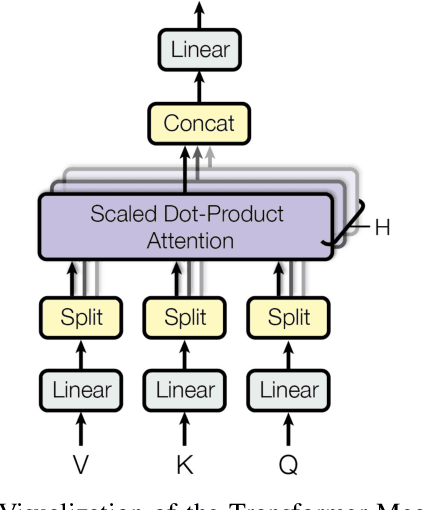
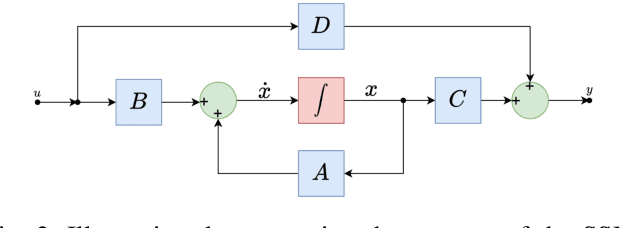
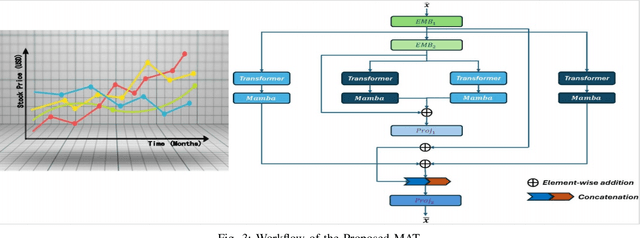
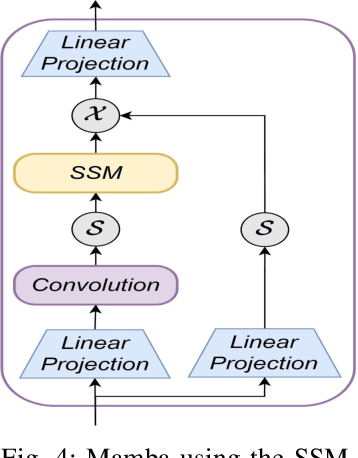
Long-short range time series forecasting is essential for predicting future trends and patterns over extended periods. While deep learning models such as Transformers have made significant strides in advancing time series forecasting, they often encounter difficulties in capturing long-term dependencies and effectively managing sparse semantic features. The state-space model, Mamba, addresses these issues through its adept handling of selective input and parallel computing, striking a balance between computational efficiency and prediction accuracy. This article examines the advantages and disadvantages of both Mamba and Transformer models, and introduces a combined approach, MAT, which leverages the strengths of each model to capture unique long-short range dependencies and inherent evolutionary patterns in multivariate time series. Specifically, MAT harnesses the long-range dependency capabilities of Mamba and the short-range characteristics of Transformers. Experimental results on benchmark weather datasets demonstrate that MAT outperforms existing comparable methods in terms of prediction accuracy, scalability, and memory efficiency.
Robust Domain Generalization for Multi-modal Object Recognition
Aug 11, 2024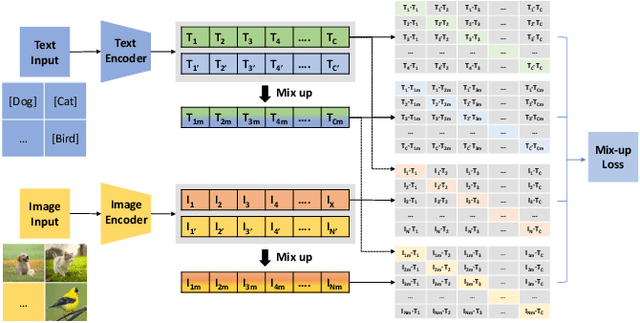
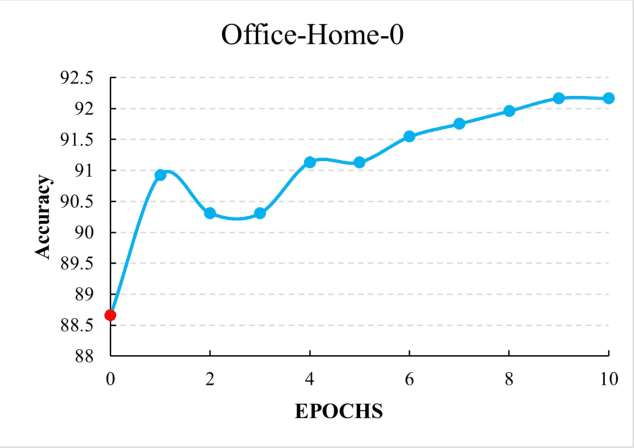
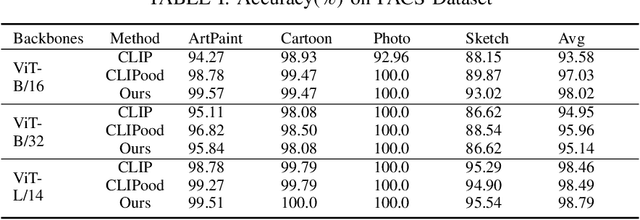
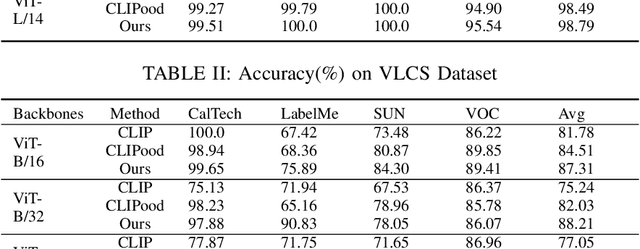
In multi-label classification, machine learning encounters the challenge of domain generalization when handling tasks with distributions differing from the training data. Existing approaches primarily focus on vision object recognition and neglect the integration of natural language. Recent advancements in vision-language pre-training leverage supervision from extensive visual-language pairs, enabling learning across diverse domains and enhancing recognition in multi-modal scenarios. However, these approaches face limitations in loss function utilization, generality across backbones, and class-aware visual fusion. This paper proposes solutions to these limitations by inferring the actual loss, broadening evaluations to larger vision-language backbones, and introducing Mixup-CLIPood, which incorporates a novel mix-up loss for enhanced class-aware visual fusion. Our method demonstrates superior performance in domain generalization across multiple datasets.
Rumor Detection with a novel graph neural network approach
Apr 02, 2024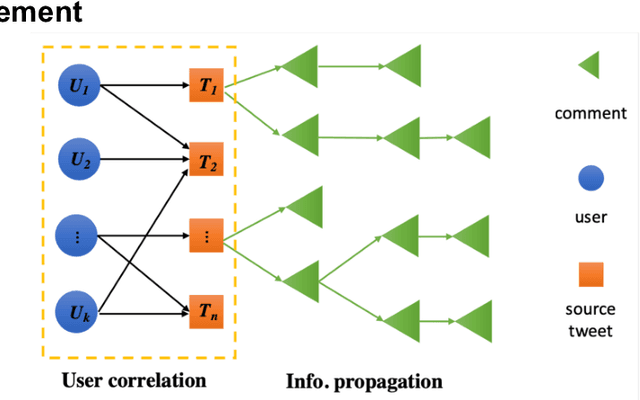
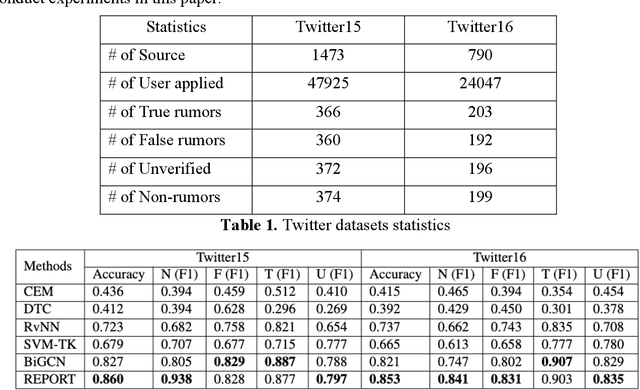

The wide spread of rumors on social media has caused a negative impact on people's daily life, leading to potential panic, fear, and mental health problems for the public. How to debunk rumors as early as possible remains a challenging problem. Existing studies mainly leverage information propagation structure to detect rumors, while very few works focus on correlation among users that they may coordinate to spread rumors in order to gain large popularity. In this paper, we propose a new detection model, that jointly learns both the representations of user correlation and information propagation to detect rumors on social media. Specifically, we leverage graph neural networks to learn the representations of user correlation from a bipartite graph that describes the correlations between users and source tweets, and the representations of information propagation with a tree structure. Then we combine the learned representations from these two modules to classify the rumors. Since malicious users intend to subvert our model after deployment, we further develop a greedy attack scheme to analyze the cost of three adversarial attacks: graph attack, comment attack, and joint attack. Evaluation results on two public datasets illustrate that the proposed MODEL outperforms the state-of-the-art rumor detection models. We also demonstrate our method performs well for early rumor detection. Moreover, the proposed detection method is more robust to adversarial attacks compared to the best existing method. Importantly, we show that it requires a high cost for attackers to subvert user correlation pattern, demonstrating the importance of considering user correlation for rumor detection.
Image Captioning in news report scenario
Apr 02, 2024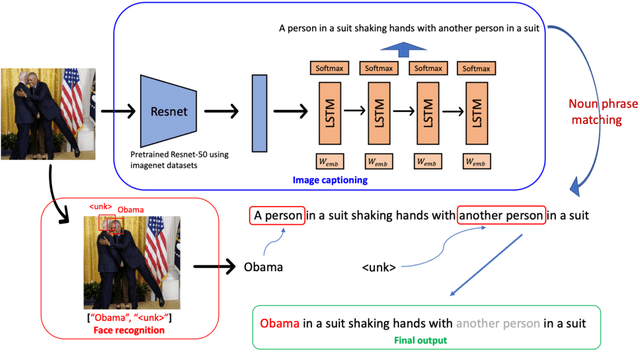
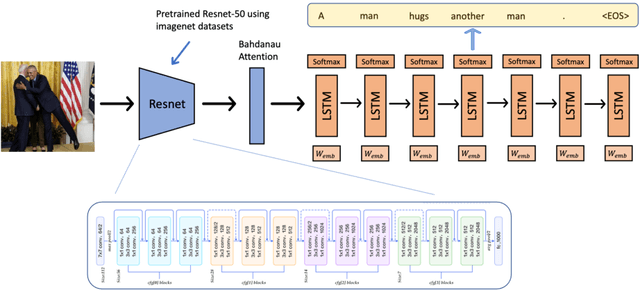


Image captioning strives to generate pertinent captions for specified images, situating itself at the crossroads of Computer Vision (CV) and Natural Language Processing (NLP). This endeavor is of paramount importance with far-reaching applications in recommendation systems, news outlets, social media, and beyond. Particularly within the realm of news reporting, captions are expected to encompass detailed information, such as the identities of celebrities captured in the images. However, much of the existing body of work primarily centers around understanding scenes and actions. In this paper, we explore the realm of image captioning specifically tailored for celebrity photographs, illustrating its broad potential for enhancing news industry practices. This exploration aims to augment automated news content generation, thereby facilitating a more nuanced dissemination of information. Our endeavor shows a broader horizon, enriching the narrative in news reporting through a more intuitive image captioning framework.
Accelerating Semi-Asynchronous Federated Learning
Feb 22, 2024
Federated Learning (FL) is a distributed machine learning paradigm that allows clients to train models on their data while preserving their privacy. FL algorithms, such as Federated Averaging (FedAvg) and its variants, have been shown to converge well in many scenarios. However, these methods require clients to upload their local updates to the server in a synchronous manner, which can be slow and unreliable in realistic FL settings. To address this issue, researchers have developed asynchronous FL methods that allow clients to continue training on their local data using a stale global model. However, most of these methods simply aggregate all of the received updates without considering their relative contributions, which can slow down convergence. In this paper, we propose a contribution-aware asynchronous FL method that takes into account the staleness and statistical heterogeneity of the received updates. Our method dynamically adjusts the contribution of each update based on these factors, which can speed up convergence compared to existing methods.
Particle Filter SLAM for Vehicle Localization
Feb 20, 2024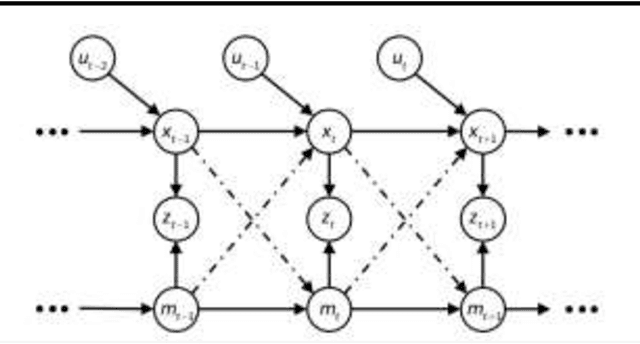
Simultaneous Localization and Mapping (SLAM) presents a formidable challenge in robotics, involving the dynamic construction of a map while concurrently determining the precise location of the robotic agent within an unfamiliar environment. This intricate task is further compounded by the inherent "chicken-and-egg" dilemma, where accurate mapping relies on a dependable estimation of the robot's location, and vice versa. Moreover, the computational intensity of SLAM adds an additional layer of complexity, making it a crucial yet demanding topic in the field. In our research, we address the challenges of SLAM by adopting the Particle Filter SLAM method. Our approach leverages encoded data and fiber optic gyro (FOG) information to enable precise estimation of vehicle motion, while lidar technology contributes to environmental perception by providing detailed insights into surrounding obstacles. The integration of these data streams culminates in the establishment of a Particle Filter SLAM framework, representing a key endeavor in this paper to effectively navigate and overcome the complexities associated with simultaneous localization and mapping in robotic systems.
* 6 pages, Journal of Industrial Engineering and Applied Science
News Recommendation with Attention Mechanism
Feb 20, 2024This paper explores the area of news recommendation, a key component of online information sharing. Initially, we provide a clear introduction to news recommendation, defining the core problem and summarizing current methods and notable recent algorithms. We then present our work on implementing the NRAM (News Recommendation with Attention Mechanism), an attention-based approach for news recommendation, and assess its effectiveness. Our evaluation shows that NRAM has the potential to significantly improve how news content is personalized for users on digital news platforms.
* 7 pages, Journal of Industrial Engineering and Applied Science
Large Language Models for Forecasting and Anomaly Detection: A Systematic Literature Review
Feb 15, 2024



This systematic literature review comprehensively examines the application of Large Language Models (LLMs) in forecasting and anomaly detection, highlighting the current state of research, inherent challenges, and prospective future directions. LLMs have demonstrated significant potential in parsing and analyzing extensive datasets to identify patterns, predict future events, and detect anomalous behavior across various domains. However, this review identifies several critical challenges that impede their broader adoption and effectiveness, including the reliance on vast historical datasets, issues with generalizability across different contexts, the phenomenon of model hallucinations, limitations within the models' knowledge boundaries, and the substantial computational resources required. Through detailed analysis, this review discusses potential solutions and strategies to overcome these obstacles, such as integrating multimodal data, advancements in learning methodologies, and emphasizing model explainability and computational efficiency. Moreover, this review outlines critical trends that are likely to shape the evolution of LLMs in these fields, including the push toward real-time processing, the importance of sustainable modeling practices, and the value of interdisciplinary collaboration. Conclusively, this review underscores the transformative impact LLMs could have on forecasting and anomaly detection while emphasizing the need for continuous innovation, ethical considerations, and practical solutions to realize their full potential.