 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxed Triangle Inequality for Kullback-Leibler Divergence Between Multivariate Gaussian Distributions
Jan 31, 2026The Kullback-Leibler (KL) divergence is not a proper distance metric and does not satisfy the triangle inequality, posing theoretical challenges in certain practical applications. Existing work has demonstrated that KL divergence between multivariate Gaussian distributions follows a relaxed triangle inequality. Given any three multivariate Gaussian distributions $\mathcal{N}_1, \mathcal{N}_2$, and $\mathcal{N}_3$, if $KL(\mathcal{N}_1, \mathcal{N}_2)\leq ε_1$ and $KL(\mathcal{N}_2, \mathcal{N}_3)\leq ε_2$, then $KL(\mathcal{N}_1, \mathcal{N}_3)< 3ε_1+3ε_2+2\sqrt{ε_1ε_2}+o(ε_1)+o(ε_2)$. However, the supremum of $KL(\mathcal{N}_1, \mathcal{N}_3)$ is still unknown. In this paper, we investigate the relaxed triangle inequality for the KL divergence between multivariate Gaussian distributions and give the supremum of $KL(\mathcal{N}_1, \mathcal{N}_3)$ as well as the conditions when the supremum can be attained. When $ε_1$ and $ε_2$ are small, the supremum is $ε_1+ε_2+\sqrt{ε_1ε_2}+o(ε_1)+o(ε_2)$. Finally, we demonstrate several applications of our results in out-of-distribution detection with flow-based generative models and safe reinforcement learning.
The Paradigm Shift: A Comprehensive Survey on Large Vision Language Models for Multimodal Fake News Detection
Jan 16, 2026In recent years, the rapid evolution of large vision-language models (LVLMs) has driven a paradigm shift in multimodal fake news detection (MFND), transforming it from traditional feature-engineering approaches to unified, end-to-end multimodal reasoning frameworks. Early methods primarily relied on shallow fusion techniques to capture correlations between text and images, but they struggled with high-level semantic understanding and complex cross-modal interactions. The emergence of LVLMs has fundamentally changed this landscape by enabling joint modeling of vision and language with powerful representation learning, thereby enhancing the ability to detect misinformation that leverages both textual narratives and visual content. Despite these advances, the field lacks a systematic survey that traces this transition and consolidates recent developments. To address this gap, this paper provides a comprehensive review of MFND through the lens of LVLMs. We first present a historical perspective, mapping the evolution from conventional multimodal detection pipelines to foundation model-driven paradigms. Next, we establish a structured taxonomy covering model architectures, datasets, and performance benchmarks. Furthermore, we analyze the remaining technical challenges, including interpretability, temporal reasoning, and domain generalization. Finally, we outline future research directions to guide the next stage of this paradigm shift. To the best of our knowledge, this is the first comprehensive survey to systematically document and analyze the transformative role of LVLMs in combating multimodal fake news. The summary of existing methods mentioned is in our Github: \href{https://github.com/Tan-YiLong/Overview-of-Fake-News-Detection}{https://github.com/Tan-YiLong/Overview-of-Fake-News-Detection}.
GRRE: Leveraging G-Channel Removed Reconstruction Error for Robust Detection of AI-Generated Images
Jan 06, 2026The rapid progress of generative models, particularly diffusion models and GANs, has greatly increased the difficulty of distinguishing synthetic images from real ones. Although numerous detection methods have been proposed, their accuracy often degrades when applied to images generated by novel or unseen generative models, highlighting the challenge of achieving strong generalization. To address this challenge, we introduce a novel detection paradigm based on channel removal reconstruction. Specifically, we observe that when the green (G) channel is removed from real images and reconstructed, the resulting reconstruction errors differ significantly from those of AI-generated images. Building upon this insight, we propose G-channel Removed Reconstruction Error (GRRE), a simple yet effective method that exploits this discrepancy for robust AI-generated image detection. Extensive experiments demonstrate that GRRE consistently achieves high detection accuracy across multiple generative models, including those unseen during training. Compared with existing approaches, GRRE not only maintains strong robustness against various perturbations and post-processing operations but also exhibits superior cross-model generalization. These results highlight the potential of channel-removal-based reconstruction as a powerful forensic tool for safeguarding image authenticity in the era of generative AI.
DiffMark: Diffusion-based Robust Watermark Against Deepfakes
Jul 02, 2025Deepfakes pose significant security and privacy threats through malicious facial manipulations. While robust watermarking can aid in authenticity verification and source tracking, existing methods often lack the sufficient robustness against Deepfake manipulations. Diffusion models have demonstrated remarkable performance in image generation, enabling the seamless fusion of watermark with image during generation. In this study, we propose a novel robust watermarking framework based on diffusion model, called DiffMark. By modifying the training and sampling scheme, we take the facial image and watermark as conditions to guide the diffusion model to progressively denoise and generate corresponding watermarked image. In the construction of facial condition, we weight the facial image by a timestep-dependent factor that gradually reduces the guidance intensity with the decrease of noise, thus better adapting to the sampling process of diffusion model. To achieve the fusion of watermark condition, we introduce a cross information fusion (CIF) module that leverages a learnable embedding table to adaptively extract watermark features and integrates them with image features via cross-attention. To enhance the robustness of the watermark against Deepfake manipulations, we integrate a frozen autoencoder during training phase to simulate Deepfake manipulations. Additionally, we introduce Deepfake-resistant guidance that employs specific Deepfake model to adversarially guide the diffusion sampling process to generate more robust watermarked images. Experimental results demonstrate the effectiveness of the proposed DiffMark on typical Deepfakes. Our code will be available at https://github.com/vpsg-research/DiffMark.
GSDNet: Revisiting Incomplete Multimodal-Diffusion from Graph Spectrum Perspective for Conversation Emotion Recognition
Jun 14, 2025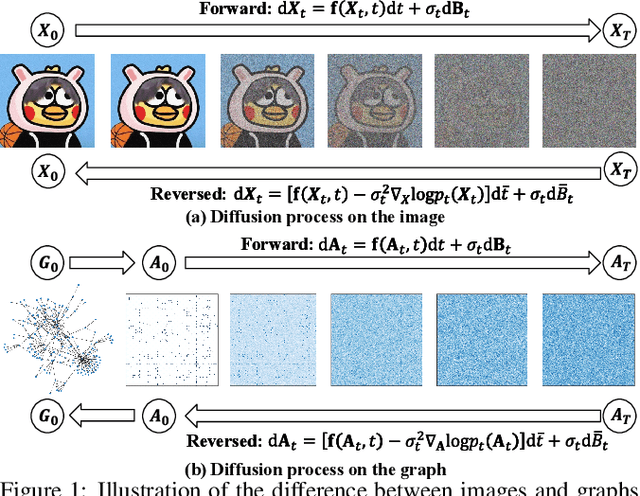
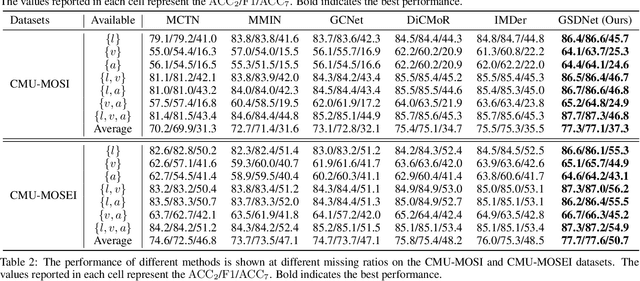
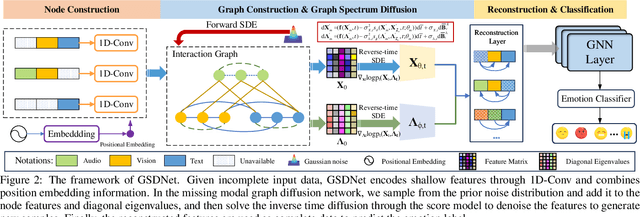
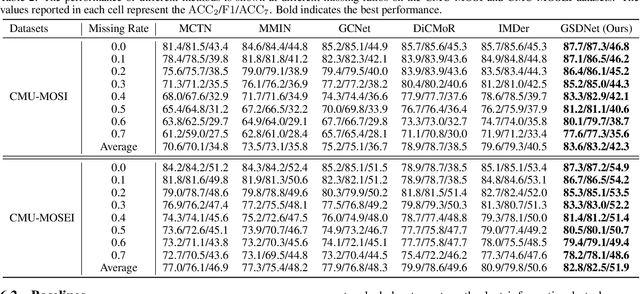
Multimodal emotion recognition in conversations (MERC) aims to infer the speaker's emotional state by analyzing utterance information from multiple sources (i.e., video, audio, and text). Compared with unimodality, a more robust utterance representation can be obtained by fusing complementary semantic information from different modalities. However, the modality missing problem severely limits the performance of MERC in practical scenarios. Recent work has achieved impressive performance on modality completion using graph neural networks and diffusion models, respectively. This inspires us to combine these two dimensions through the graph diffusion model to obtain more powerful modal recovery capabilities. Unfortunately, existing graph diffusion models may destroy the connectivity and local structure of the graph by directly adding Gaussian noise to the adjacency matrix, resulting in the generated graph data being unable to retain the semantic and topological information of the original graph. To this end, we propose a novel Graph Spectral Diffusion Network (GSDNet), which maps Gaussian noise to the graph spectral space of missing modalities and recovers the missing data according to its original distribution. Compared with previous graph diffusion methods, GSDNet only affects the eigenvalues of the adjacency matrix instead of destroying the adjacency matrix directly, which can maintain the global topological information and important spectral features during the diffusion process. Extensive experiments have demonstrated that GSDNet achieves state-of-the-art emotion recognition performance in various modality loss scenarios.
ReGraP-LLaVA: Reasoning enabled Graph-based Personalized Large Language and Vision Assistant
May 06, 2025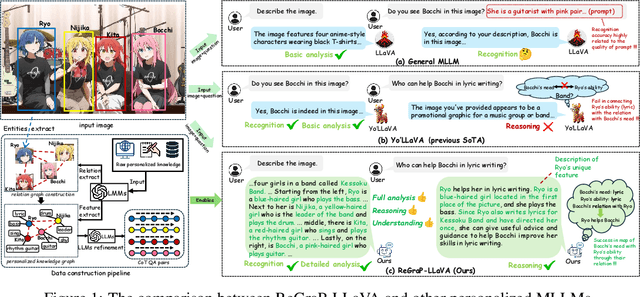

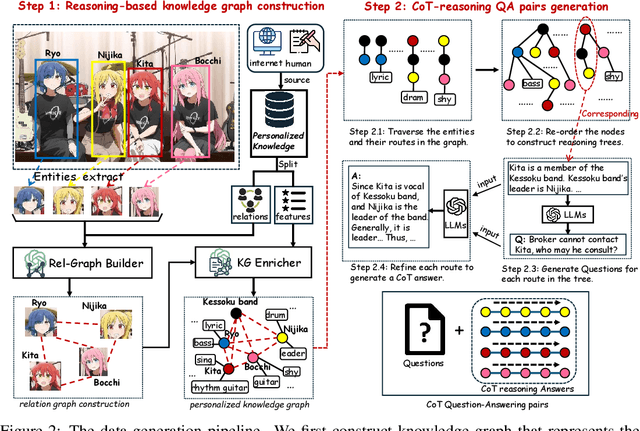
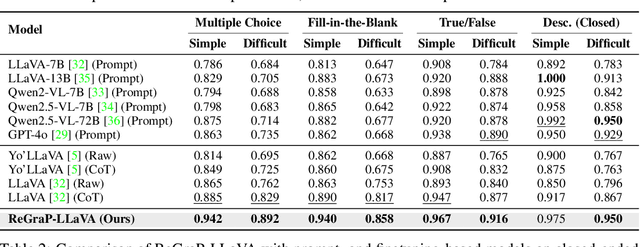
Recent advances in personalized MLLMs enable effective capture of user-specific concepts, supporting both recognition of personalized concepts and contextual captioning. However, humans typically explore and reason over relations among objects and individuals, transcending surface-level information to achieve more personalized and contextual understanding. To this end, existing methods may face three main limitations: Their training data lacks multi-object sets in which relations among objects are learnable. Building on the limited training data, their models overlook the relations between different personalized concepts and fail to reason over them. Their experiments mainly focus on a single personalized concept, where evaluations are limited to recognition and captioning tasks. To address the limitations, we present a new dataset named ReGraP, consisting of 120 sets of personalized knowledge. Each set includes images, KGs, and CoT QA pairs derived from the KGs, enabling more structured and sophisticated reasoning pathways. We propose ReGraP-LLaVA, an MLLM trained with the corresponding KGs and CoT QA pairs, where soft and hard graph prompting methods are designed to align KGs within the model's semantic space. We establish the ReGraP Benchmark, which contains diverse task types: multiple-choice, fill-in-the-blank, True/False, and descriptive questions in both open- and closed-ended settings. The proposed benchmark is designed to evaluate the relational reasoning and knowledge-connection capability of personalized MLLMs. We conduct experiments on the proposed ReGraP-LLaVA and other competitive MLLMs. Results show that the proposed model not only learns personalized knowledge but also performs relational reasoning in responses, achieving the SoTA performance compared with the competitive methods. All the codes and datasets are released at: https://github.com/xyfyyds/ReGraP.
Optimizing Multi-Round Enhanced Training in Diffusion Models for Improved Preference Understanding
Apr 25, 2025Generative AI has significantly changed industries by enabling text-driven image generation, yet challenges remain in achieving high-resolution outputs that align with fine-grained user preferences. Consequently, multi-round interactions are necessary to ensure the generated images meet expectations. Previous methods enhanced prompts via reward feedback but did not optimize over a multi-round dialogue dataset. In this work, we present a Visual Co-Adaptation (VCA) framework incorporating human-in-the-loop feedback, leveraging a well-trained reward model aligned with human preferences. Using a diverse multi-turn dialogue dataset, our framework applies multiple reward functions, such as diversity, consistency, and preference feedback, while fine-tuning the diffusion model through LoRA, thus optimizing image generation based on user input. We also construct multi-round dialogue datasets of prompts and image pairs aligned with user intent. Experiments demonstrate that our method outperforms state-of-the-art baselines, significantly improving image consistency and alignment with user intent. Our approach consistently surpasses competing models in user satisfaction, especially in multi-turn dialogue scenarios.
Efficient Temporal Consistency in Diffusion-Based Video Editing with Adaptor Modules: A Theoretical Framework
Apr 22, 2025Adapter-based methods are commonly used to enhance model performance with minimal additional complexity, especially in video editing tasks that require frame-to-frame consistency. By inserting small, learnable modules into pretrained diffusion models, these adapters can maintain temporal coherence without extensive retraining. Approaches that incorporate prompt learning with both shared and frame-specific tokens are particularly effective in preserving continuity across frames at low training cost. In this work, we want to provide a general theoretical framework for adapters that maintain frame consistency in DDIM-based models under a temporal consistency loss. First, we prove that the temporal consistency objective is differentiable under bounded feature norms, and we establish a Lipschitz bound on its gradient. Second, we show that gradient descent on this objective decreases the loss monotonically and converges to a local minimum if the learning rate is within an appropriate range. Finally, we analyze the stability of modules in the DDIM inversion procedure, showing that the associated error remains controlled. These theoretical findings will reinforce the reliability of diffusion-based video editing methods that rely on adapter strategies and provide theoretical insights in video generation tasks.
Twin Co-Adaptive Dialogue for Progressive Image Generation
Apr 21, 2025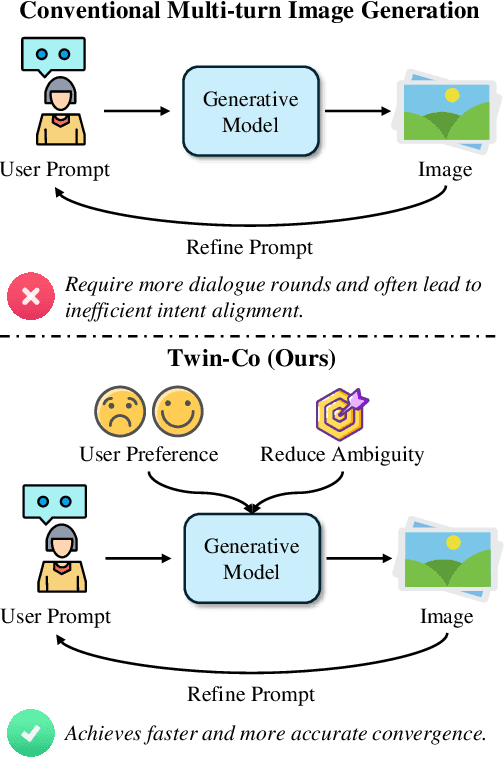
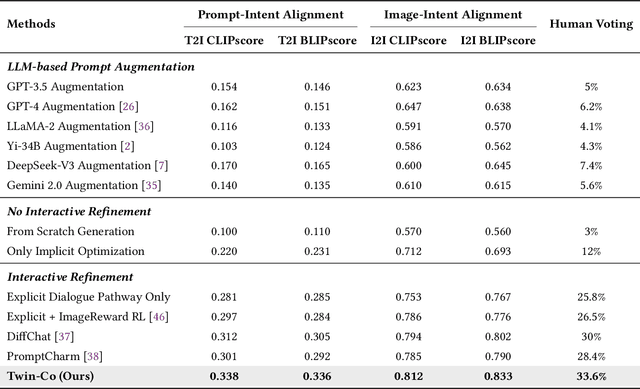
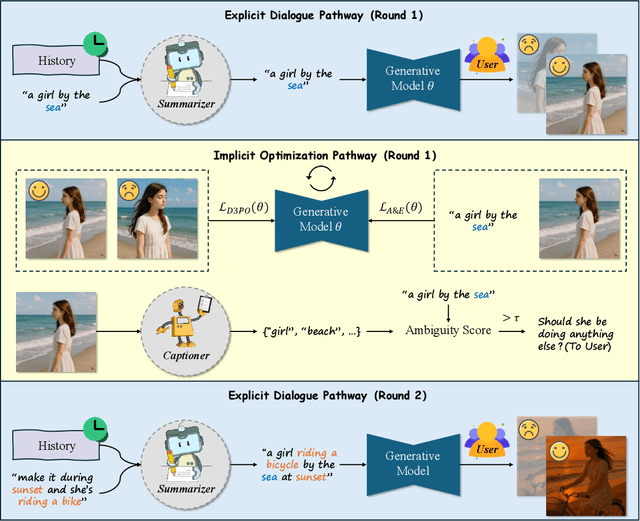

Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.
SE-GNN: Seed Expanded-Aware Graph Neural Network with Iterative Optimization for Semi-supervised Entity Alignment
Mar 24, 2025Entity alignment aims to use pre-aligned seed pairs to find other equivalent entities from different knowledge graphs (KGs) and is widely used in graph fusion-related fields. However, as the scale of KGs increases, manually annotating pre-aligned seed pairs becomes difficult. Existing research utilizes entity embeddings obtained by aggregating single structural information to identify potential seed pairs, thus reducing the reliance on pre-aligned seed pairs. However, due to the structural heterogeneity of KGs, the quality of potential seed pairs obtained using only a single structural information is not ideal. In addition, although existing research improves the quality of potential seed pairs through semi-supervised iteration, they underestimate the impact of embedding distortion produced by noisy seed pairs on the alignment effect. In order to solve the above problems, we propose a seed expanded-aware graph neural network with iterative optimization for semi-supervised entity alignment, named SE-GNN. First, we utilize the semantic attributes and structural features of entities, combined with a conditional filtering mechanism, to obtain high-quality initial potential seed pairs. Next, we designed a local and global awareness mechanism. It introduces initial potential seed pairs and combines local and global information to obtain a more comprehensive entity embedding representation, which alleviates the impact of KGs structural heterogeneity and lays the foundation for the optimization of initial potential seed pairs. Then, we designed the threshold nearest neighbor embedding correction strategy. It combines the similarity threshold and the bidirectional nearest neighbor method as a filtering mechanism to select iterative potential seed pairs and also uses an embedding correction strategy to eliminate the embedding distortion.