 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPSeg: Auto-Prompt Model with Acquired and Injected Knowledge for Nuclear Instance Segmentation and Classification
Apr 03, 2025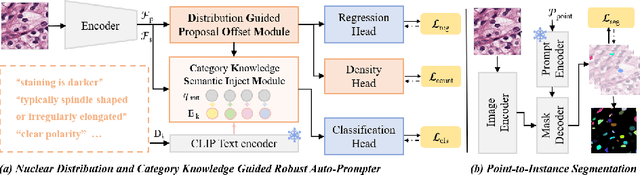
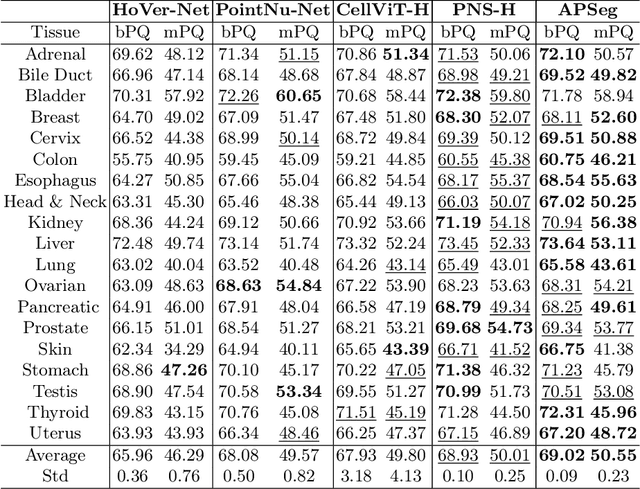
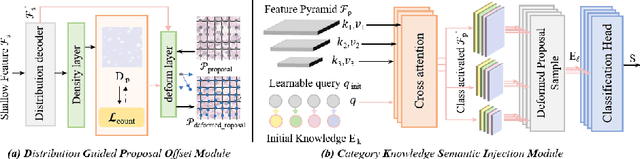
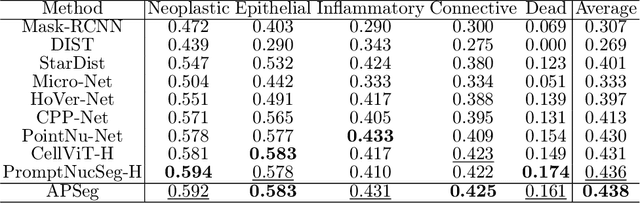
Nuclear instance segmentation and classification provide critical quantitative foundations for digital pathology diagnosis. With the advent of the foundational Segment Anything Model (SAM), the accuracy and efficiency of nuclear segmentation have improved significantly. However, SAM imposes a strong reliance on precise prompts, and its class-agnostic design renders its classification results entirely dependent on the provided prompts. Therefore, we focus on generating prompts with more accurate localization and classification and propose \textbf{APSeg}, \textbf{A}uto-\textbf{P}rompt model with acquired and injected knowledge for nuclear instance \textbf{Seg}mentation and classification. APSeg incorporates two knowledge-aware modules: (1) Distribution-Guided Proposal Offset Module (\textbf{DG-POM}), which learns distribution knowledge through density map guided, and (2) Category Knowledge Semantic Injection Module (\textbf{CK-SIM}), which injects morphological knowledge derived from category descriptions. We conducted extensive experiments on the PanNuke and CoNSeP datasets, demonstrating the effectiveness of our approach. The code will be released upon acceptance.
Instance Migration Diffusion for Nuclear Instance Segmentation in Pathology
Apr 02, 2025Nuclear instance segmentation plays a vital role in disease diagnosis within digital pathology. However, limited labeled data in pathological images restricts the overall performance of nuclear instance segmentation. To tackle this challenge, we propose a novel data augmentation framework Instance Migration Diffusion Model (IM-Diffusion), IM-Diffusion designed to generate more varied pathological images by constructing diverse nuclear layouts and internuclear spatial relationships. In detail, we introduce a Nuclear Migration Module (NMM) which constructs diverse nuclear layouts by simulating the process of nuclear migration. Building on this, we further present an Internuclear-regions Inpainting Module (IIM) to generate diverse internuclear spatial relationships by structure-aware inpainting. On the basis of the above, IM-Diffusion generates more diverse pathological images with different layouts and internuclear spatial relationships, thereby facilitating downstream tasks. Evaluation on the CoNSeP and GLySAC datasets demonstrate that the images generated by IM-Diffusion effectively enhance overall instance segmentation performance. Code will be made public later.
WECAR: An End-Edge Collaborative Inference and Training Framework for WiFi-Based Continuous Human Activity Recognition
Mar 09, 2025WiFi-based human activity recognition (HAR) holds significant promise for ubiquitous sensing in smart environments. A critical challenge lies in enabling systems to dynamically adapt to evolving scenarios, learning new activities without catastrophic forgetting of prior knowledge, while adhering to the stringent computational constraints of edge devices. Current approaches struggle to reconcile these requirements due to prohibitive storage demands for retaining historical data and inefficient parameter utilization. We propose WECAR, an end-edge collaborative inference and training framework for WiFi-based continuous HAR, which decouples computational workloads to overcome these limitations. In this framework, edge devices handle model training, lightweight optimization, and updates, while end devices perform efficient inference. WECAR introduces two key innovations, i.e., dynamic continual learning with parameter efficiency and hierarchical distillation for end deployment. For the former, we propose a transformer-based architecture enhanced by task-specific dynamic model expansion and stability-aware selective retraining. For the latter, we propose a dual-phase distillation mechanism that includes multi-head self-attention relation distillation and prefix relation distillation. We implement WECAR based on heterogeneous hardware using Jetson Nano as edge devices and the ESP32 as end devices, respectively. Our experiments across three public WiFi datasets reveal that WECAR not only outperforms several state-of-the-art methods in performance and parameter efficiency, but also achieves a substantial reduction in the model's parameter count post-optimization without sacrificing accuracy. This validates its practicality for resource-constrained environments.
ConSense: Continually Sensing Human Activity with WiFi via Growing and Picking
Feb 18, 2025WiFi-based human activity recognition (HAR) holds significant application potential across various fields. To handle dynamic environments where new activities are continuously introduced, WiFi-based HAR systems must adapt by learning new concepts without forgetting previously learned ones. Furthermore, retaining knowledge from old activities by storing historical exemplar is impractical for WiFi-based HAR due to privacy concerns and limited storage capacity of edge devices. In this work, we propose ConSense, a lightweight and fast-adapted exemplar-free class incremental learning framework for WiFi-based HAR. The framework leverages the transformer architecture and involves dynamic model expansion and selective retraining to preserve previously learned knowledge while integrating new information. Specifically, during incremental sessions, small-scale trainable parameters that are trained specifically on the data of each task are added in the multi-head self-attention layer. In addition, a selective retraining strategy that dynamically adjusts the weights in multilayer perceptron based on the performance stability of neurons across tasks is used. Rather than training the entire model, the proposed strategies of dynamic model expansion and selective retraining reduce the overall computational load while balancing stability on previous tasks and plasticity on new tasks. Evaluation results on three public WiFi datasets demonstrate that ConSense not only outperforms several competitive approaches but also requires fewer parameters, highlighting its practical utility in class-incremental scenarios for HAR.
Polynomial Time Near-Time-Optimal Multi-Robot Path Planning in Three Dimensions with Applications to Large-Scale UAV Coordination
Jul 06, 2022
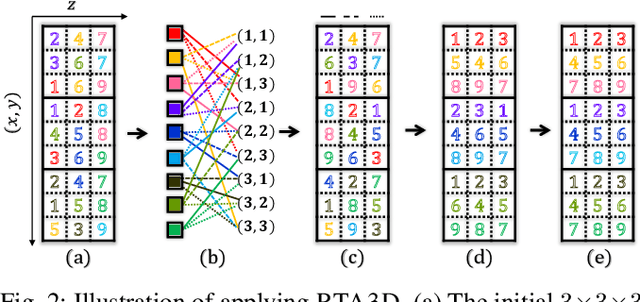

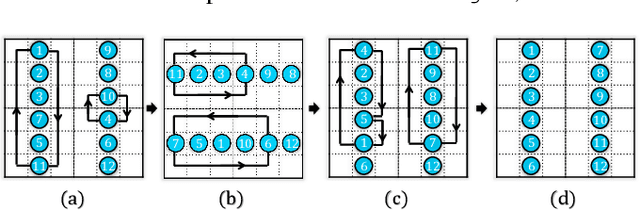
For enabling efficient, large-scale coordination of unmanned aerial vehicles (UAVs) under the labeled setting, in this work, we develop the first polynomial time algorithm for the reconfiguration of many moving bodies in three-dimensional spaces, with provable $1.x$ asymptotic makespan optimality guarantee under high robot density. More precisely, on an $m_1\times m_2 \times m_3$ grid, $m_1\ge m_2\ge m_3$, our method computes solutions for routing up to $\frac{m_1m_2m_3}{3}$ uniquely labeled robots with uniformly randomly distributed start and goal configurations within a makespan of $m_1 + 2m_2 +2m_3+o(m_1)$, with high probability. Because the makespan lower bound for such instances is $m_1 + m_2+m_3 - o(m_1)$, also with high probability, as $m_1 \to \infty$, $\frac{m_1+2m_2+2m_3}{m_1+m_2+m_3}$ optimality guarantee is achieved. $\frac{m_1+2m_2+2m_3}{m_1+m_2+m_3} \in (1, \frac{5}{3}]$, yielding $1.x$ optimality. In contrast, it is well-known that multi-robot path planning is NP-hard to optimally solve. In numerical evaluations, our method readily scales to support the motion planning of over $100,000$ robots in 3D while simultaneously achieving $1.x$ optimality. We demonstrate the application of our method in coordinating many quadcopters in both simulation and hardware experiments.
Federated Learning with Diversified Preference for Humor Recognition
Dec 03, 2020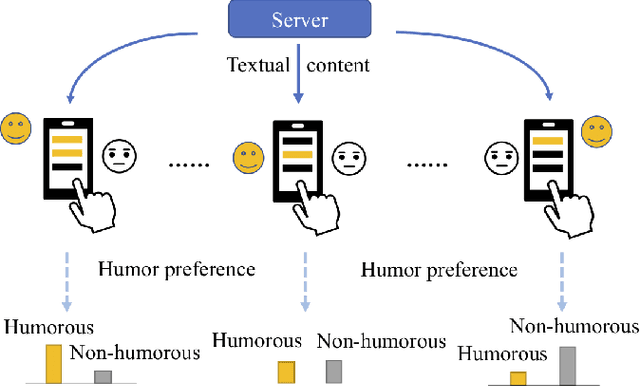
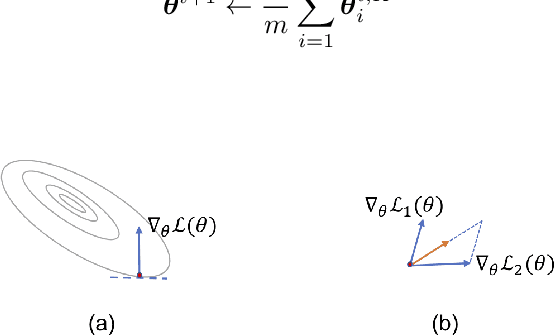
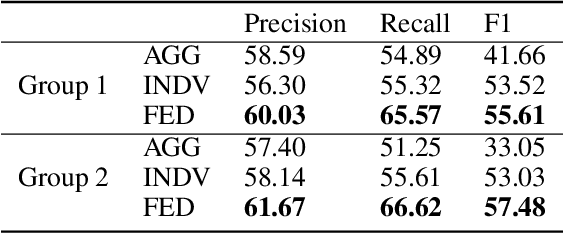
Understanding humor is critical to creative language modeling with many applications in human-AI interaction. However, due to differences in the cognitive systems of the audience, the perception of humor can be highly subjective. Thus, a given passage can be regarded as funny to different degrees by different readers. This makes training humorous text recognition models that can adapt to diverse humor preferences highly challenging. In this paper, we propose the FedHumor approach to recognize humorous text contents in a personalized manner through federated learning (FL). It is a federated BERT model capable of jointly considering the overall distribution of humor scores with humor labels by individuals for given texts. Extensive experiments demonstrate significant advantages of FedHumor in recognizing humor contents accurately for people with diverse humor preferences compared to 9 state-of-the-art humor recognition approaches.
Multi-Participant Multi-Class Vertical Federated Learning
Jan 30, 2020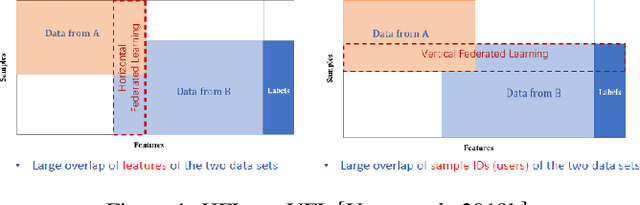

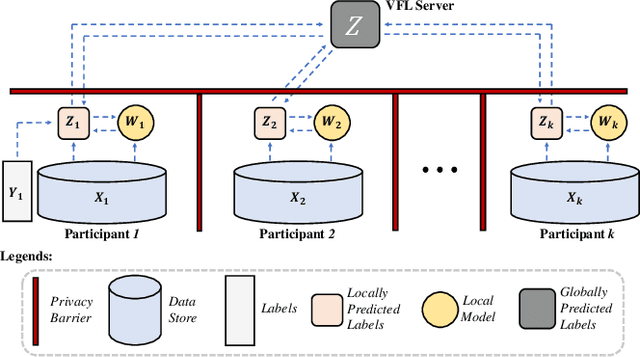

Federated learning (FL) is a privacy-preserving paradigm for training collective machine learning models with locally stored data from multiple participants. Vertical federated learning (VFL) deals with the case where participants sharing the same sample ID space but having different feature spaces, while label information is owned by one participant. Current studies of VFL only support two participants, and mostly focus on binaryclass logistic regression problems. In this paper, we propose the Multi-participant Multi-class Vertical Federated Learning (MMVFL) framework for multi-class VFL problems involving multiple parties. Extending the idea of multi-view learning (MVL), MMVFL enables label sharing from its owner to other VFL participants in a privacypreserving manner. To demonstrate the effectiveness of MMVFL, a feature selection scheme is incorporated into MMVFL to compare its performance against supervised feature selection and MVL-based approaches. Experiment results on real-world datasets show that MMVFL can effectively share label information among multiple VFL participants and match multi-class classification performance of existing approaches.
Few-Shot Learning-Based Human Activity Recognition
Mar 25, 2019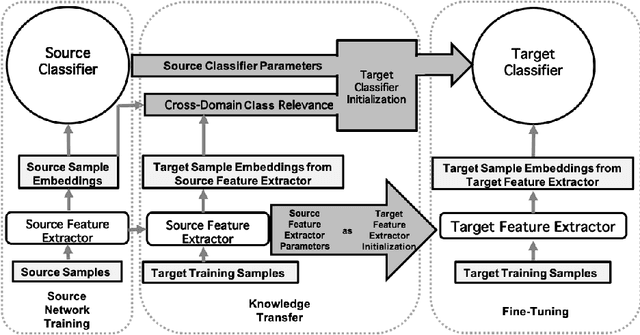
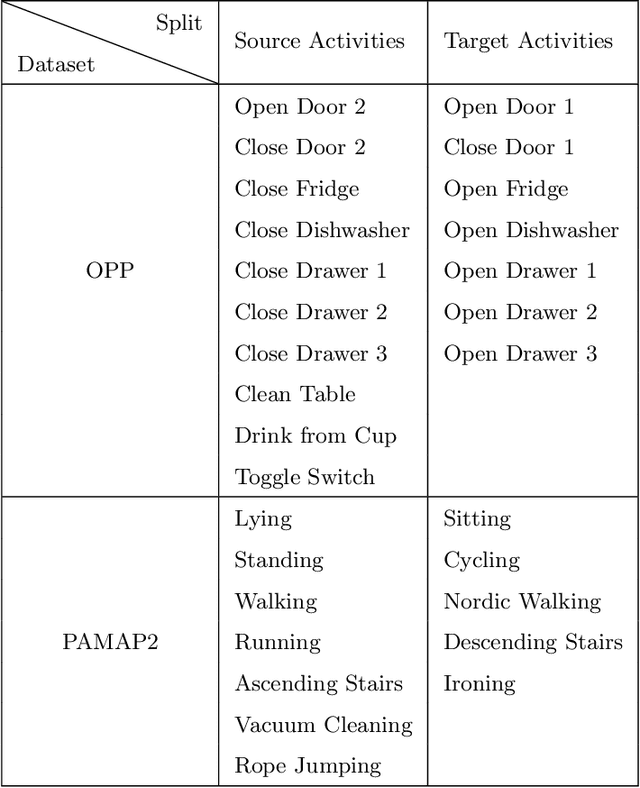
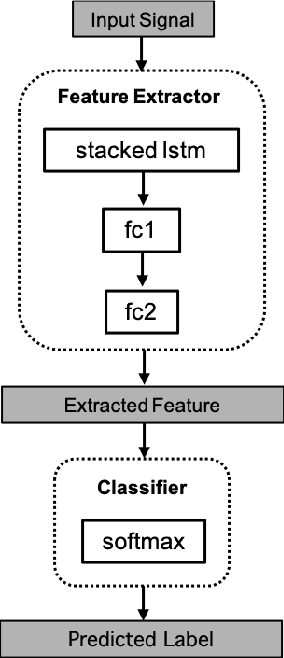
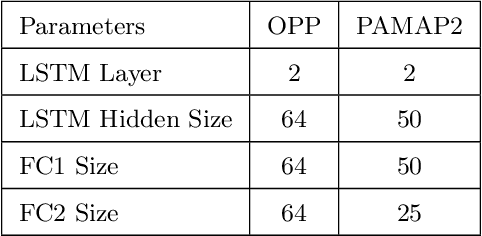
Few-shot learning is a technique to learn a model with a very small amount of labeled training data by transferring knowledge from relevant tasks. In this paper, we propose a few-shot learning method for wearable sensor based human activity recognition, a technique that seeks high-level human activity knowledge from low-level sensor inputs. Due to the high costs to obtain human generated activity data and the ubiquitous similarities between activity modes, it can be more efficient to borrow information from existing activity recognition models than to collect more data to train a new model from scratch when only a few data are available for model training. The proposed few-shot human activity recognition method leverages a deep learning model for feature extraction and classification while knowledge transfer is performed in the manner of model parameter transfer. In order to alleviate negative transfer, we propose a metric to measure cross-domain class-wise relevance so that knowledge of higher relevance is assigned larger weights during knowledge transfer. Promising results in extensive experiments show the advantages of the proposed approach.
Autoencoder Based Sample Selection for Self-Taught Learning
Aug 05, 2018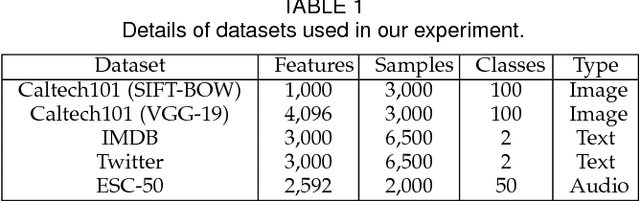
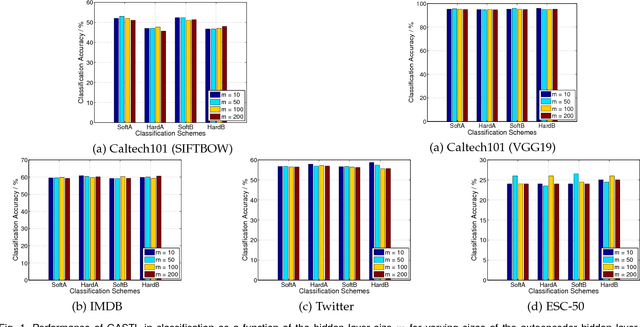
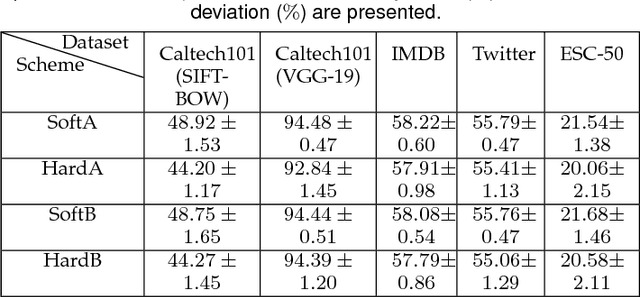
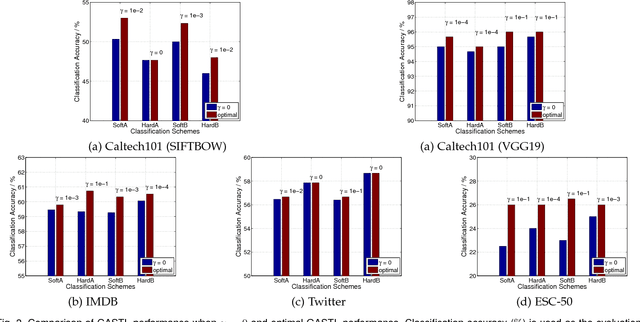
Self-taught learning is a technique that uses a large number of unlabeled data as source samples to improve the task performance on target samples. Compared with other transfer learning techniques, self-taught learning can be applied to a broader set of scenarios due to the loose restrictions on source data. However, knowledge transferred from source samples that are not sufficiently related to the target domain may negatively influence the target learner, which is referred to as negative transfer. In this paper, we propose a metric for the relevance between a source sample and target samples. To be more specific, both source and target samples are reconstructed through a single-layer autoencoder with a linear relationship between source samples and target samples simultaneously enforced. An l_{2,1}-norm sparsity constraint is imposed on the transformation matrix to identify source samples relevant to the target domain. Source domain samples that are deemed relevant are assigned pseudo-labels reflecting their relevance to target domain samples, and are combined with target samples in order to provide an expanded training set for classifier training. Local data structures are also preserved during source sample selection through spectral graph analysis. Promising results in extensive experiments show the advantages of the proposed approach.
Graph Autoencoder-Based Unsupervised Feature Selection with Broad and Local Data Structure Preservation
Apr 21, 2018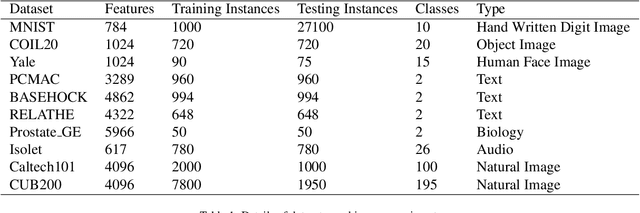
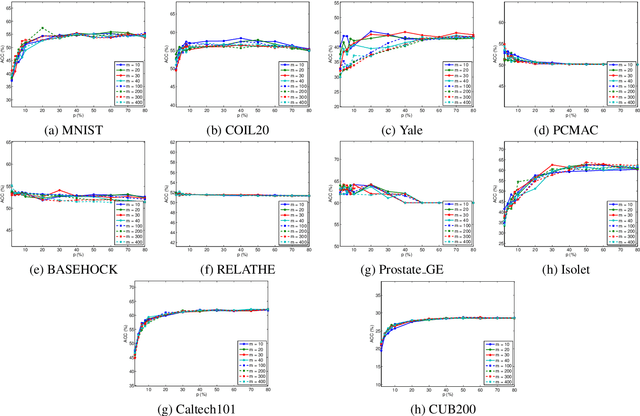

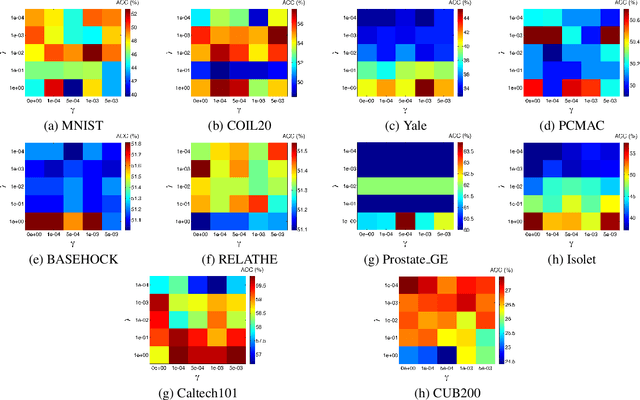
Feature selection is a dimensionality reduction technique that selects a subset of representative features from high dimensional data by eliminating irrelevant and redundant features. Recently, feature selection combined with sparse learning has attracted significant attention due to its outstanding performance compared with traditional feature selection methods that ignores correlation between features. These works first map data onto a low-dimensional subspace and then select features by posing a sparsity constraint on the transformation matrix. However, they are restricted by design to linear data transformation, a potential drawback given that the underlying correlation structures of data are often non-linear. To leverage a more sophisticated embedding, we propose an autoencoder-based unsupervised feature selection approach that leverages a single-layer autoencoder for a joint framework of feature selection and manifold learning. More specifically, we enforce column sparsity on the weight matrix connecting the input layer and the hidden layer, as in previous work. Additionally, we include spectral graph analysis on the projected data into the learning process to achieve local data geometry preservation from the original data space to the low-dimensional feature space. Extensive experiments are conducted on image, audio, text, and biological data. The promising experimental results validate the superiority of the proposed method.